基于深度学习的多光谱图像语义分割
本例展示了如何使用U-Net对七通道的多光谱图像进行语义分割。
语义分割是指给图像中的每个像素标上一个类。语义分割的一个应用是跟踪森林砍伐,即森林覆盖随时间的变化。环境机构跟踪森林砍伐情况,以评估和量化一个地区的环境和生态健康状况。
基于深度学习的语义分割可以从高分辨率航空照片中获得精确的植被覆盖测量。一个挑战是区分具有相似视觉特征的类,例如尝试将绿色像素分类为草、灌木或树。为了提高分类精度,一些数据集包含多光谱图像,提供关于每个像素的额外信息。例如,哈姆林海滩州立公园的数据集用三个近红外通道补充了彩色图像,提供了更清晰的类别分离。

这个例子首先向您展示了如何使用预先训练好的U-Net执行语义分割,然后使用分割结果来计算植被覆盖的程度。然后,您可以选择使用基于补丁的训练方法在哈姆林海滩国家公园数据集上训练U-Net网络。
下载数据集
本例使用高分辨率多光谱数据集来训练网络[1].这组图像是用无人机在纽约哈姆林海滩州立公园上空拍摄的。数据包含有标记的训练集、验证集和测试集,有18个对象类标签。数据文件大小为3.0 GB。
方法下载数据集的mat文件版本downloadHamlinBeachMSIDatahelper函数。该函数作为支持文件附加到示例中。金宝app指定dataDir作为数据的期望位置。
dataDir = fullfile(tempdir,“rit18_data”);downloadHamlinBeachMSIData (dataDir);
加载数据集。
负载(fullfile (dataDir“rit18_data.mat”));谁train_dataval_datatest_data
名称大小字节类属性test_data 7x12446x7654 1333663576 uint16 train_data 7x9393x5642 741934284 uint16 val_data 7x8833x6918 855493716 uint16
所述多光谱图像数据排列为numChannels——- - - - - -宽度——- - - - - -高度数组。然而,在MATLAB®中,多通道图像被排列为宽度——- - - - - -高度——- - - - - -numChannels数组。要重新塑造数据,使通道处于第三维度,请使用switchChannelsToThirdPlanehelper函数。该函数作为支持文件附加到示例中。金宝app
train_data = switchChannelsToThirdPlane(train_data);val_data = switchChannelsToThirdPlane(val_data);test_data = switchChannelsToThirdPlane(test_data);
确认数据具有正确的结构。
谁train_dataval_datatest_data
名称大小字节类属性test_data 12446x7654x7 1333663576 uint16 train_data 9393x5642x7 741934284 uint16 val_data 8833x6918x7 855493716 uint16
培训数据保存为MAT文件,培训标签保存为PNG文件。这有助于使用控件加载训练数据imageDatastore和一个pixelLabelDatastore在培训。
保存(“train_data.mat”,“train_data”);imwrite (train_labels“train_labels.png”);
多光谱数据可视化
在这个数据集中,RGB颜色通道是第3、2和1个图像通道。以蒙太奇的形式显示训练、验证和测试图像的颜色组件。要使图像在屏幕上显得更亮,请使用histeq函数。
图蒙太奇(...{histeq(train_data(:,:,[3 2 1])),...Histeq (val_data(:,:,[3 2 1])),...Histeq (test_data(:,:,[3 2 1]))},...BorderSize = 10,写成BackgroundColor =“白色”)标题(训练、验证和测试图像的RGB组件(从左到右))

以蒙太奇的形式显示训练数据的最后三个直方图均衡化通道。这些通道与近红外波段相对应,并根据其热特征突出显示图像的不同组成部分。例如,靠近第二个通道图像中心的树比其他两个通道中的树显示出更多的细节。
图蒙太奇(...{histeq (train_data (:: 4)), histeq (train_data (:,:, 5)), histeq (train_data (:,: 6)},...BorderSize = 10,写成BackgroundColor =“白色”)标题(训练图像IR通道1、2、3(从左到右))

通道7是一个掩码,表示有效的分割区域。显示训练、验证和测试图像的掩码。
图蒙太奇(...{train_data (:: 7), val_data (:,: 7), test_data (:,: 7)},...BorderSize = 10,写成BackgroundColor =“白色”)标题(训练、验证和测试图像掩码(从左到右))

可视化基本真理标签
标记的图像包含用于分割的真实数据,每个像素分配给18个类中的一个。获取具有相应id的类列表。
disp(类)
0.其他类/图像边界道路标志2。树3。建设4。交通工具(小汽车、卡车或公共汽车)6人。7号椅子。野餐桌8。9.黑木面板 White Wood Panel 10. Orange Landing Pad 11. Water Buoy 12. Rocks 13. Other Vegetation 14. Grass 15. Sand 16. Water (Lake) 17. Water (Pond) 18. Asphalt (Parking Lot/Walkway)
创建一个类名向量。
classNames = [“路标”,“树”,“建筑”,“汽车”,“人”,...“LifeguardChair”,“PicnicTable”,“BlackWoodPanel”,...“WhiteWoodPanel”,“OrangeLandingPad”,“浮”,“石头”,...“LowLevelVegetation”,“Grass_Lawn”,“Sand_Beach”,...“Water_Lake”,“Water_Pond”,“沥青”];
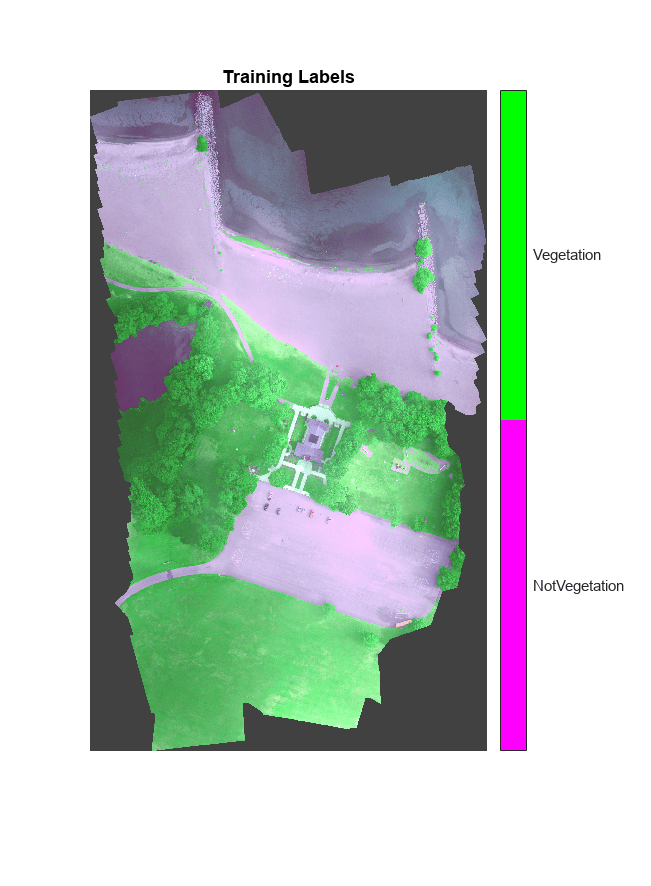
在直方图均衡化的RGB训练图像上叠加标签。为图像添加一个颜色条。
cmap = jet(编号(classNames));B = labeloverlay(histeq(train_data(:,:,4:6)),train_labels,透明度=0.8,Colormap=cmap);图imshow(B)标题(“培训”标签) N = number (classNames);ticks = 1/(N*2):1/N:1;colorbar (TickLabels = cellstr(类名),蜱虫=蜱虫,TickLength = 0, TickLabelInterpreter =“没有”);colormap城市规划机构(cmap)
执行语义分割
下载预先训练好的U-Net网络。
trainedUnet_url =“//www.tatmou.com/金宝appsupportfiles/vision/data/multispectralUnet.mat”;downloadTrainedNetwork (trainedUnet_url dataDir);负载(fullfile (dataDir“multispectralUnet.mat”));
要在训练好的网络上执行语义分割,请使用segmentMultispectralImage使用验证数据的辅助函数。该函数作为支持文件附加到示例中。金宝app的segmentMultispectralImage函数对图像补丁执行分割semanticseg函数。需要处理补丁,因为图像的大小阻止一次性处理整个图像。
predictPatchSize = [1024 1024];segmentedImage = segmentMultispectralImage(val_data,net,predictPatchSize);
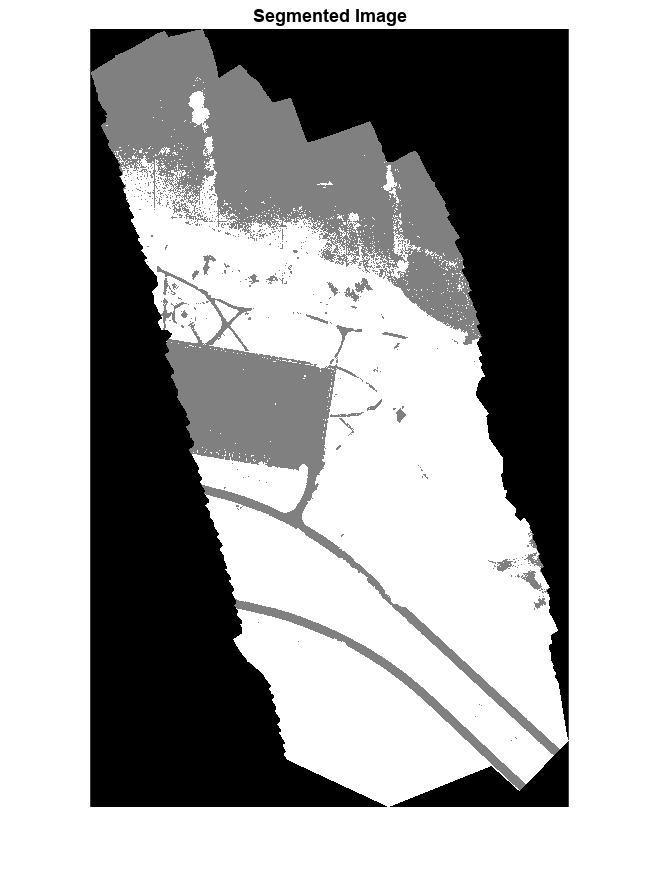
为了只提取分割的有效部分,将分割后的图像乘以验证数据的掩码通道。
segmentedImage = uint8(val_data(:,:,7)~=0) .* segmentedImage;figure imshow(segmentedImage,[]) title(“分割图像”)
语义分割的输出是有噪声的。执行后期图像处理,以消除噪声和杂散像素。使用medfilt2函数从分割中去除椒盐噪声。可视化去除噪声后的分割图像。
segmentedImage = medfilt2(segmentedImage,[7,7]);imshow (segmentedImage []);标题(“去除噪声的分割图像”)

将分割后的图像叠加在直方图均衡的RGB验证图像上。
B = labeloverlay(histeq(val_data(:,:,[3 2 1])),segmentedImage,透明度=0.8,Colormap=cmap);图imshow(B)标题(“标记分段图像”) colorbar (TickLabels = cellstr(类名),蜱虫=蜱虫,TickLength = 0, TickLabelInterpreter =“没有”);colormap城市规划机构(cmap)

计算植被覆盖范围
语义分割结果可以用来回答相关的生态问题。例如,植被覆盖的土地面积的百分比是多少?要回答这个问题,请找到标记为植被的像素数。标签id 2(“Trees”)、13(“LowLevelVegetation”)和14(“Grass_Lawn”)是植被类别。还可以通过将掩码图像的ROI中的像素相加来找到有效像素的总数。
vegetationClassIds = uint8([2,13,14]);vegetationPixels = ismember(segmentedImage(:),vegetationClassIds);validPixels = (segmentedImage~=0);numVegetationPixels = sum(vegetationPixels(:));numValidPixels = sum(validPixels(:));
用植被像素数除以有效像素数计算植被覆盖率。
percentVegetationCover = (numVegetationPixels/numValidPixels)*100;流(“植被覆盖率为%3.2f%%。”, percentVegetationCover);
植被覆盖率为51.72%。
示例的其余部分向您展示如何在Hamlin Beach数据集上训练U-Net。
为训练创建随机补丁提取数据存储
使用随机补丁提取数据存储将训练数据输入网络。该数据存储从包含真实图像和像素标签数据的图像数据存储和像素标签数据存储中提取多个对应的随机补丁。补丁是一种常见的技术,用于防止大图像的内存不足,并有效地增加可用的训练数据量。
从“”开始加载训练图像。train_data.mat”在一个imageDatastore.因为MAT文件格式是非标准图像格式,所以必须使用MAT文件读取器来读取图像数据。你可以使用MAT文件阅读器,matRead6Channels,该方法从训练数据中提取前六个通道,并省略最后一个包含掩码的通道。该函数作为支持文件附加到示例中。金宝app
imds = imageDatastore(“train_data.mat”FileExtensions =“.mat”ReadFcn = @matRead6Channels);
创建一个pixelLabelDatastore存储包含18个标记区域的标签补丁。
pixelLabelIds = 1:18;pxds = pixelLabelDatastore(“train_labels.png”一会,pixelLabelIds);
创建一个randomPatchExtractionDatastore从图像数据存储和像素标签数据存储。每个小批包含16个大小为256 * 256像素的补丁。在纪元的每次迭代中提取1000个小批。
dsTrain = randompatchextracactiondatastore (imds,pxds,[256,256],PatchesPerImage=16000);
随机补丁提取数据存储dsTrain在历元的每个迭代中向网络提供小批量数据。预览数据存储以查看数据。
inputBatch =预览(dsTrain);disp (inputBatch)
InputImage ResponsePixelLabelImage __________________ _______________________ { 256×256×6 uint16}{256×256分类}{256×256×6 uint16}{256×256分类}{256×256×6 uint16}{256×256分类}{256×256×6 uint16}{256×256分类}{256×256×6 uint16}{256×256分类}{256×256×6 uint16}{256×256分类}{256×256×6 uint16}{256×256分类}{256×256×6 uint16}{256×256分类}
创建U-Net网络层
本例使用U-Net网络的一个变体。在U-Net中,在初始的卷积层序列中穿插最大池化层,依次降低输入图像的分辨率。这些层之后是一系列卷积层,其中穿插着上采样算子,依次增加输入图像的分辨率[2].U- net这个名字来源于这样一个事实,即网络可以画出一个像字母U一样的对称形状。
这个例子将U-Net修改为在卷积中使用零填充,以便卷积的输入和输出具有相同的大小。使用helper函数,createUnet,以使用几个预先选定的超参数创建U-Net。该函数作为支持文件附加到示例中。金宝app
inputTileSize = [256,256,6];lgraph = createUnet(inputTileSize);disp (lgraph.Layers)
58×1带有图层的图层数组:1“ImageInputLayer”图像输入256×256×6图片2的zerocenter正常化Encoder-Section-1-Conv-1二维卷积64 3×3×6旋转步[1]和填充[1 1 1 1]3‘Encoder-Section-1-ReLU-1 ReLU ReLU 4 Encoder-Section-1-Conv-2二维卷积64 3×3×64旋转步[1]和填充[1 1 1 1]5‘Encoder-Section-1-ReLU-2 ReLU ReLU 6“Encoder-Section-1-MaxPool”二维最大池2×2马克斯池步[2 2]和填充[0 0 0 0]7Encoder-Section-2-Conv-1二维卷积128 3×3×64旋转步[1]和填充(1 1 1)8“Encoder-Section-2-ReLU-1”ReLU ReLU 9 Encoder-Section-2-Conv-2二维卷积128 3×3×128旋转步[1]和填充[1 1 1 1]10 ' Encoder-Section-2-ReLU-2 ReLU ReLU 11“Encoder-Section-2-MaxPool”二维最大池2×2马克斯池步(2 - 2)和填充[0 0 0 0]12“Encoder-Section-3-Conv-1”二维卷积256 3×3×128旋转步[1]和填充[1 1 1 1] 13的Encoder-Section-3-ReLU-1 ReLU ReLU 14 Encoder-Section-3-Conv-2二维卷积256 3×3×256旋转步[1]和填充[1 1 1 1]15 ' Encoder-Section-3-ReLU-2 ReLU ReLU 16“Encoder-Section-3-MaxPool”二维最大池2×2马克斯池步(2 - 2)和填充[0 0 0 0]17 Encoder-Section-4-Conv-1二维卷积512 3×3×256旋转步[1]和填充[1 1 1 1]18 ' Encoder-Section-4-ReLU-1 ReLU ReLU 19 Encoder-Section-4-Conv-2二维卷积512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] 20 'Encoder-Section-4-ReLU-2' ReLU ReLU 21 'Encoder-Section-4-DropOut' Dropout 50% dropout 22 'Encoder-Section-4-MaxPool' 2-D Max Pooling 2×2 max pooling with stride [2 2] and padding [0 0 0 0] 23 'Mid-Conv-1' 2-D Convolution 1024 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] 24 'Mid-ReLU-1' ReLU ReLU 25 'Mid-Conv-2' 2-D Convolution 1024 3×3×1024 convolutions with stride [1 1] and padding [1 1 1 1] 26 'Mid-ReLU-2' ReLU ReLU 27 'Mid-DropOut' Dropout 50% dropout 28 'Decoder-Section-1-UpConv' 2-D Transposed Convolution 512 2×2×1024 transposed convolutions with stride [2 2] and cropping [0 0 0 0] 29 'Decoder-Section-1-UpReLU' ReLU ReLU 30 'Decoder-Section-1-DepthConcatenation' Depth concatenation Depth concatenation of 2 inputs 31 'Decoder-Section-1-Conv-1' 2-D Convolution 512 3×3×1024 convolutions with stride [1 1] and padding [1 1 1 1] 32 'Decoder-Section-1-ReLU-1' ReLU ReLU 33 'Decoder-Section-1-Conv-2' 2-D Convolution 512 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] 34 'Decoder-Section-1-ReLU-2' ReLU ReLU 35 'Decoder-Section-2-UpConv' 2-D Transposed Convolution 256 2×2×512 transposed convolutions with stride [2 2] and cropping [0 0 0 0] 36 'Decoder-Section-2-UpReLU' ReLU ReLU 37 'Decoder-Section-2-DepthConcatenation' Depth concatenation Depth concatenation of 2 inputs 38 'Decoder-Section-2-Conv-1' 2-D Convolution 256 3×3×512 convolutions with stride [1 1] and padding [1 1 1 1] 39 'Decoder-Section-2-ReLU-1' ReLU ReLU 40 'Decoder-Section-2-Conv-2' 2-D Convolution 256 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] 41 'Decoder-Section-2-ReLU-2' ReLU ReLU 42 'Decoder-Section-3-UpConv' 2-D Transposed Convolution 128 2×2×256 transposed convolutions with stride [2 2] and cropping [0 0 0 0] 43 'Decoder-Section-3-UpReLU' ReLU ReLU 44 'Decoder-Section-3-DepthConcatenation' Depth concatenation Depth concatenation of 2 inputs 45 'Decoder-Section-3-Conv-1' 2-D Convolution 128 3×3×256 convolutions with stride [1 1] and padding [1 1 1 1] 46 'Decoder-Section-3-ReLU-1' ReLU ReLU 47 'Decoder-Section-3-Conv-2' 2-D Convolution 128 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] 48 'Decoder-Section-3-ReLU-2' ReLU ReLU 49 'Decoder-Section-4-UpConv' 2-D Transposed Convolution 64 2×2×128 transposed convolutions with stride [2 2] and cropping [0 0 0 0] 50 'Decoder-Section-4-UpReLU' ReLU ReLU 51 'Decoder-Section-4-DepthConcatenation' Depth concatenation Depth concatenation of 2 inputs 52 'Decoder-Section-4-Conv-1' 2-D Convolution 64 3×3×128 convolutions with stride [1 1] and padding [1 1 1 1] 53 'Decoder-Section-4-ReLU-1' ReLU ReLU 54 'Decoder-Section-4-Conv-2' 2-D Convolution 64 3×3×64 convolutions with stride [1 1] and padding [1 1 1 1] 55 'Decoder-Section-4-ReLU-2' ReLU ReLU 56 'Final-ConvolutionLayer' 2-D Convolution 18 1×1×64 convolutions with stride [1 1] and padding [0 0 0 0] 57 'Softmax-Layer' Softmax softmax 58 'Segmentation-Layer' Pixel Classification Layer Cross-entropy loss
选择培训选项
使用动量随机梯度下降(SGDM)优化训练网络。属性指定SGDM的超参数设置trainingOptions(深度学习工具箱)函数。
训练一个深度网络是很耗时的。通过指定高学习率来加速培训。然而,这可能会导致网络的梯度爆炸或不受控制地增长,从而阻止网络成功训练。若要将渐变保持在有意义的范围内,请通过指定“GradientThreshold”作为0.05,并指定“GradientThresholdMethod”使用梯度的l2范数。
initialLearningRate = 0.05;maxEpochs = 150;minibatchSize = 16;L2reg = 0.0001;选项= trainingOptions(“个”,...InitialLearnRate = initialLearningRate,...动量= 0.9,...L2Regularization = l2reg,...MaxEpochs = MaxEpochs,...MiniBatchSize = MiniBatchSize,...LearnRateSchedule =“分段”,...洗牌=“every-epoch”,...GradientThresholdMethod =“l2norm”,...GradientThreshold = 0.05,...情节=“训练进步”,...VerboseFrequency = 20);
训练网络或下载预训练网络
为了训练网络,设置doTraining变量转换为真正的.训练模型使用trainNetwork(深度学习工具箱)函数。
如果有GPU,可以在GPU上进行训练。使用GPU需要并行计算工具箱™和支持CUDA®的NVIDIA®GPU。有关更多信息,请参见GPU计算要求(并行计算工具箱).在NVIDIA Titan X上训练大约需要20个小时。
doTraining = false;如果doTraining net = trainNetwork(dsTrain,lgraph,options);modelDateTime = string(datetime(“现在”格式=“yyyy-MM-dd-HH-mm-ss”));保存(fullfile (dataDir“multispectralUnet——”+ modelDateTime +“.mat”),“净”);结束
评估分割精度
分割验证数据。
segmentedImage = segmentMultispectralImage(val_data,net,predictPatchSize);
将分割后的图像和ground truth标签保存为PNG文件。该示例使用这些文件来计算精度指标。
imwrite (segmentedImage“results.png”);imwrite (val_labels“gtruth.png”);
加载分割结果和ground truth使用pixelLabelDatastore.
pxdsResults = pixelLabelDatastore(“results.png”一会,pixelLabelIds);pxdsTruth = pixelLabelDatastore(“gtruth.png”一会,pixelLabelIds);
利用语义分割的全局精度来度量语义分割的全局精度evaluateSemanticSegmentation函数。
ssm = evaluateSemanticSegmentation(pxdsResults,pxdsTruth,Metrics=“global-accuracy”);
评估语义分割结果 ---------------------------------------- * 所选指标:全球精度。*处理1张图像。*完成……完成了。*数据集指标:GlobalAccuracy ______________ 0.90411
全局精度分数表明,只有超过90%的像素被正确分类。
参考文献
[1] Kemker, R., C. Salvaggio, C. Kanan。用于语义分割的高分辨率多光谱数据集CoRR, abs/1703.01918, 2017。
[2]罗内伯格,O. P.费舍尔和T.布罗克斯。U-Net:用于生物医学图像分割的卷积网络, abs / 1505.04597。2015.
Kemker, Ronald, Carl Salvaggio和Christopher Kanan。基于深度学习的多光谱遥感图像语义分割算法ISPRS摄影测量与遥感杂志,深度学习RS数据,145(2018年11月1日):60-77。https://doi.org/10.1016/j.isprsjprs.2018.04.014。
另请参阅
trainingOptions(深度学习工具箱)|trainNetwork(深度学习工具箱)|randomPatchExtractionDatastore|pixelLabelDatastore|semanticseg|evaluateSemanticSegmentation|imageDatastore|histeq|unetLayers
相关的话题
- 开始使用深度学习进行语义分割
- 基于深度学习的语义分割
- 用于深度学习的数据存储(深度学习工具箱)
外部网站
您也可以从以下列表中选择一个网站: