templateEnsemble
整体学习模板
描述
例子
整体学习创建一个模板
使用templateEnsemble指定一个整体学习的模板。您必须指定集合的方法,学习周期,数量和类型的弱的学习者。对于这个示例,指定AdaBoostM1方法,100学生,分类树弱的学习者。
t = templateEnsemble (“AdaBoostM1”,100,“树”)
t =适合分类AdaBoostM1的模板。类型:“分类”方法:“AdaBoostM1”LearnerTemplates:“树”NLearn: 100 LearnRate: []
模板对象的所有属性都是空的,除了方法,类型,LearnerTemplates,NLearn。训练时,软件填写空的属性与各自的默认值。例如,软件填充LearnRate财产与1。
t是一个计划,一个学习者,没有计算发生当你指定它。你可以通过t来fitcecoc指定合奏二进制ECOC兼职学习的学习者。
创建一个模板ECOC多级学习
用于创建一个模板fitcecoc。
加载心律失常的数据集。
负载心律失常汇总(分类(Y));
值计算百分比1 245 2 54.20% 44 9.73% 3 15 3.32% 4 15 3.32% 5 13 2.88% 6 25 5.53% 7 3 9 9 8 2 0.44% 0.66% 1.99% 10 50 11.06% 14 4 0.88% 15 5 1.11% 16 4.87%
rng (1);%的再现性
有些类小相对频率数据。
创建一个模板AdaBoostM1合奏的分类树,并指定使用100学习者和0.1的收缩。默认情况下,促进生长树桩(即。,一个节点有一组叶)。因为有类小频率,树木必须足够的敏感的少数类。指定最小数量的叶子节点观测到3。
tTree = templateTree (“MinLeafSize”,20);t = templateEnsemble (“AdaBoostM1”、100、tTree“LearnRate”,0.1);
所有属性是空的,除了模板的对象方法和类型和相应的属性的名称-值对函数调用的参数值。当你通过t训练函数,软件填写空的属性与各自的默认值。
指定t作为一个二进制学习者ECOC多级模型。火车使用默认one-versus-one编码设计。
Mdl = fitcecoc (X, Y,“学习者”t);
Mdl是一个ClassificationECOC多级模型。Mdl.BinaryLearners是78 - 1单元阵列的吗CompactClassificationEnsemble模型。Mdl.BinaryLearners {j} .Trained是100 - 1单元阵列的吗CompactClassificationTree模型,j= 1,…,78。
您可以验证一个二进制学习者包含一个弱的学习者,不是一个树桩使用视图。
视图(Mdl.BinaryLearners {1} .Trained {1},“模式”,“图”)

显示分类(resubstitution)误分类错误。
L = resubLoss (Mdl,“LossFun”,“classiferror”)
L = 0.0819
加快培训ECOC分类器使用装箱和并行计算
训练one-versus-all ECOC分类器使用GentleBoost合奏的决策树与代理分裂。加快培训,本数值预测和使用并行计算。装箱是有效的只有当fitcecoc使用一个树的学习者。训练后,估计使用10倍交叉验证分类错误。注意,并行计算需要并行计算工具箱™。
加载示例数据
加载和检查心律失常数据集。
负载心律失常(氮、磷)大小(X) =
n = 452
p = 279
isLabels =独特(Y);nLabels =元素个数(isLabels)
nLabels = 13
汇总(分类(Y))
值计算百分比1 245 2 54.20% 44 9.73% 3 15 3.32% 4 15 3.32% 5 13 2.88% 6 25 5.53% 7 3 9 9 8 2 0.44% 0.66% 1.99% 10 50 11.06% 14 4 0.88% 15 5 1.11% 16 4.87%
数据集包含279年预测,样本的大小452年相对较小。的16个不同的标签,只有13表示的响应(Y)。每个标签描述了不同程度的心律失常,和54.20%的观测是在课堂上1。
火车One-Versus-All ECOC分类器
创建一个模板。您必须指定至少三个参数:一个方法,学习者的数量,类型的学习者。对于这个示例,指定“GentleBoost”的方法,One hundred.学习者的数量,一个决策树模板,使用代理将因为有失踪的观察。
tTree = templateTree (“代孕”,“上”);tEnsemble = templateEnsemble (“GentleBoost”,100年,tTree);
tEnsemble是一个模板对象。它的大部分属性都是空的,但是软件填充在训练他们的默认值。
训练one-versus-all ECOC分类器使用决策树作为二进制学习者的集合体。加快训练,使用装箱和并行计算。
装箱(
“NumBins”, 50岁)- - -当你有一个大的训练数据集,您可以加快训练(潜在的准确性下降)使用“NumBins”名称-值对的论点。这个论点是有效的只有当fitcecoc使用一个树的学习者。如果你指定“NumBins”值,然后软件箱子每个数值预测到指定数量的等概率的垃圾箱,然后生长树本指数代替原始数据。你可以试着“NumBins”, 50岁首先,然后改变“NumBins”价值取决于训练速度和准确性。并行计算(
“选项”,statset (UseParallel,真的))——并行计算工具箱的许可证,您可以加快计算通过使用并行计算,这将池中的每个二进制学习者一个工人。工人的数量取决于你的系统配置。当你使用决策树为二进制学习者,fitcecoc对培训使用英特尔®线程构建块(TBB)双核系统及以上。因此,指定“UseParallel”在一台计算机上选择是不帮助。使用这个选项在一个集群中。
另外,指定该先验概率是1 /K,在那里K= 13个不同的类的数量。
选择= statset (“UseParallel”,真正的);Mdl = fitcecoc (X, Y,“编码”,“onevsall”,“学习者”tEnsemble,…“之前”,“统一”,“NumBins”,50岁,“选项”、选择);
开始平行池(parpool)使用“本地”概要文件…连接到平行池(工人数量:6)。
Mdl是一个ClassificationECOC模型。
交叉验证
旨在ECOC分类器使用10倍交叉验证。
CVMdl = crossval (Mdl,“选项”、选择);
警告:一个或多个折叠不含点的组。
CVMdl是一个ClassificationPartitionedECOC模型。警告表明,一些类并不代表而软件培训至少一倍。因此,这些折叠无法预测为失踪的类标签。您可以使用细胞检查的结果褶皱索引和点符号。例如,访问第一折通过输入的结果CVMdl.Trained {1}。
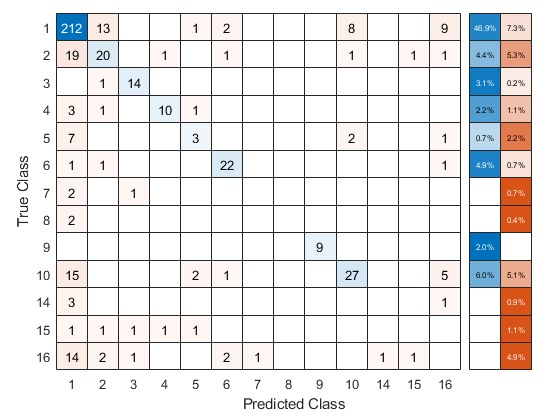
使用旨在ECOC分类器预测validation-fold标签。你可以计算出混淆矩阵使用confusionchart。移动和调整大小的图表通过改变内在的位置属性,以确保百分比出现在行总结。
oofLabel = kfoldPredict (CVMdl,“选项”、选择);ConfMat = confusionchart (Y, oofLabel,“RowSummary”,“total-normalized”);ConfMat。InnerPosition = (0.10 - 0.12 0.85 - 0.85);
复制分箱数据
通过使用复制被预测数据BinEdges训练模型和的性质离散化函数。
X = Mdl.X;%的预测数据Xbinned = 0(大小(X));边缘= Mdl.BinEdges;%找到被预测的指标。idxNumeric =找到(~ cellfun (@isempty边缘));如果iscolumn (idxNumeric) idxNumeric = idxNumeric ';结束为j = idxNumeric x = x (:, j);% x转换为数组如果x是一个表。如果istable (x) x = table2array (x);结束%组x到垃圾箱用离散化的功能。xbinned =离散化(x,[无穷;边缘{};正]);Xbinned (:, j) = Xbinned;结束
Xbinned包含本指标,从1到垃圾箱的数量,数值预测。Xbinned值是0分类预测。如果X包含南年代,那么相应的Xbinned值是南年代。
输入参数
输出参数
提示
NLearn可以从几十到几千不等。通常,一个具有良好的预测能力需要从几百到几千弱的学习者。然而,你不需要训练一次为一个周期。您可以首先增长几十个学生,检查整体性能,然后,如果必要的话,火车更弱的学习者使用的简历对于分类问题,或的简历回归问题。整体性能取决于合奏和薄弱的学习者的设置。也就是说,如果您指定薄弱的学习者使用默认参数,然后合奏可以执行。因此,像合奏的设置,是一种很好的做法,薄弱的学习者使用模板的参数调整,并选择最小化泛化误差的值。
在分类问题(即
类型是“分类”):如果整体聚合方法(
方法)是“包”和:误分类代价是高度不平衡,在袋子样品,软件oversamples独特的观察从类,它有一个很大的处罚。
类先验概率是高度倾斜,软件oversamples独特的观察从类,有一个很大的先验概率。
对于小样本大小,这些组合会导致很低的相对频率out-of-bag观测的类,它有一个很大的罚款或先验概率。因此,估计out-of-bag错误是高度变量和可能很难理解。为了避免out-of-bag估计误差方差大,特别是对于小样本大小,设定一个更加平衡的误分类代价矩阵使用
成本名称-值对参数的拟合函数,或少倾斜使用先验概率向量之前名称-值对参数的拟合函数。因为一些输入和输出参数的顺序在训练数据对应不同的类,是一种很好的做法来指定类的顺序使用
一会名称-值对参数的拟合函数。快速确定类的顺序,从训练数据中删除所有的观察,是保密的(即有一个失踪的标签),获取和显示数组的所有不同的类,然后指定数组
一会。例如,假设响应变量(Y)是一个单元阵列的标签。这个代码指定了类顺序变量一会。Ycat =分类(Y);一会=类别(Ycat)
分类分配<定义>未分类的观察和类别不包括<定义>从它的输出。因此,如果使用这段代码单元阵列的标签分类数组或类似的代码,那么你不需要删除的观察与失踪的标签来获取不同的类的列表。指定顺序应该从lowest-represented标签项目最多,然后迅速确定类的顺序(如在前面的子弹),但安排前将由频率列表中的类列表
一会。从之前的例子后,这段代码指定了类-项目最多的最低订单classNamesLH。Ycat =分类(Y);一会=类别(Ycat);频率= countcats (Ycat);[~,idx] =(频率)进行排序;classNamesLH =一会(idx);
算法
整体聚合算法的细节,请参阅整体算法。
如果您指定
方法提高算法和学习者决策树,那么软件生长树桩默认情况下。决定树桩是一个根节点连接到两个终端,叶节点。你可以调整树深度通过指定MaxNumSplits,MinLeafSize,MinParentSize名称-值对参数使用templateTree。软件生成在袋子样品采样过密类大误分类代价采样类小误分类代价。因此,out-of-bag样本较少的观察从类大误分类代价和更多的观察类小误分类代价。如果你训练一个分类合奏使用一个小的数据集和一个高度倾斜成本矩阵,然后out-of-bag观察每个类的数量可能非常低。因此,估计out-of-bag错误可以有很大的差异,可能难以解释。同样的现象也发生类先验概率大。
RUSBoost合奏的聚合方法(
方法),名称-值对的论点RatioToSmallest指定抽样比例为每一个类对lowest-represented类。例如,假设有两类训练数据,一个和B。一个有100个观察和B有10个观察。同时,假设lowest-represented类米在训练数据的观察。如果你设置
“RatioToSmallest”, 2,然后年代*米2 * 10=20.。因此,软件培训每一个学习者使用20观察类一个从类和20的观察B。如果你设置‘RatioToSmallest’, (2 - 2),那么你将获得相同的结果。如果你设置
‘RatioToSmallest’, (2, 1),然后s1*米2 * 10=20.和s2*米1 * 10=10。因此,软件培训每一个学习者使用20观察类一个从类和10的观察B。
决策树的集合体,双核系统及以上,
fitcensemble和fitrensemble并行化训练使用英特尔®线程构建块(TBB)。在英特尔TBB的详细信息,请参见https://www.intel.com/content/www/us/en/developer/tools/oneapi/onetbb.html。
版本历史
介绍了R2014b