强化学院,机构学院,ディープラーニングの违い
强化学习机构学院のの一分钱です(図1)。教师なし/教师あり机械学习习と异なり,强化学习は的ななセットにせず,动词的な环境で动词,收集した経験からデータポイント,すなわち経験は,环境とソフトウェアエージェントのて习は强に收集れなこれによりな重要なとととと重要によりととと言えなによりととと。教师あり学习や教师なし学习では必要とれる,学校前のデータ收集ややや处やつまりつまり付けがななるですです,事実付けなインセンティブがあれ,强化学习モデル,(人间による)监视监视に,それ自体で行动の习开启できます。
ディープラーニングのの适の适ははの机关学院すべてすべて及び,そしてそして化学院とディープラーニング相互相互排他的なものません。多重味料,强强の复雑复雑ははは,ディープニューラルは依存してはますこれ,深层深层化学院としてとしてれるれるれるです。
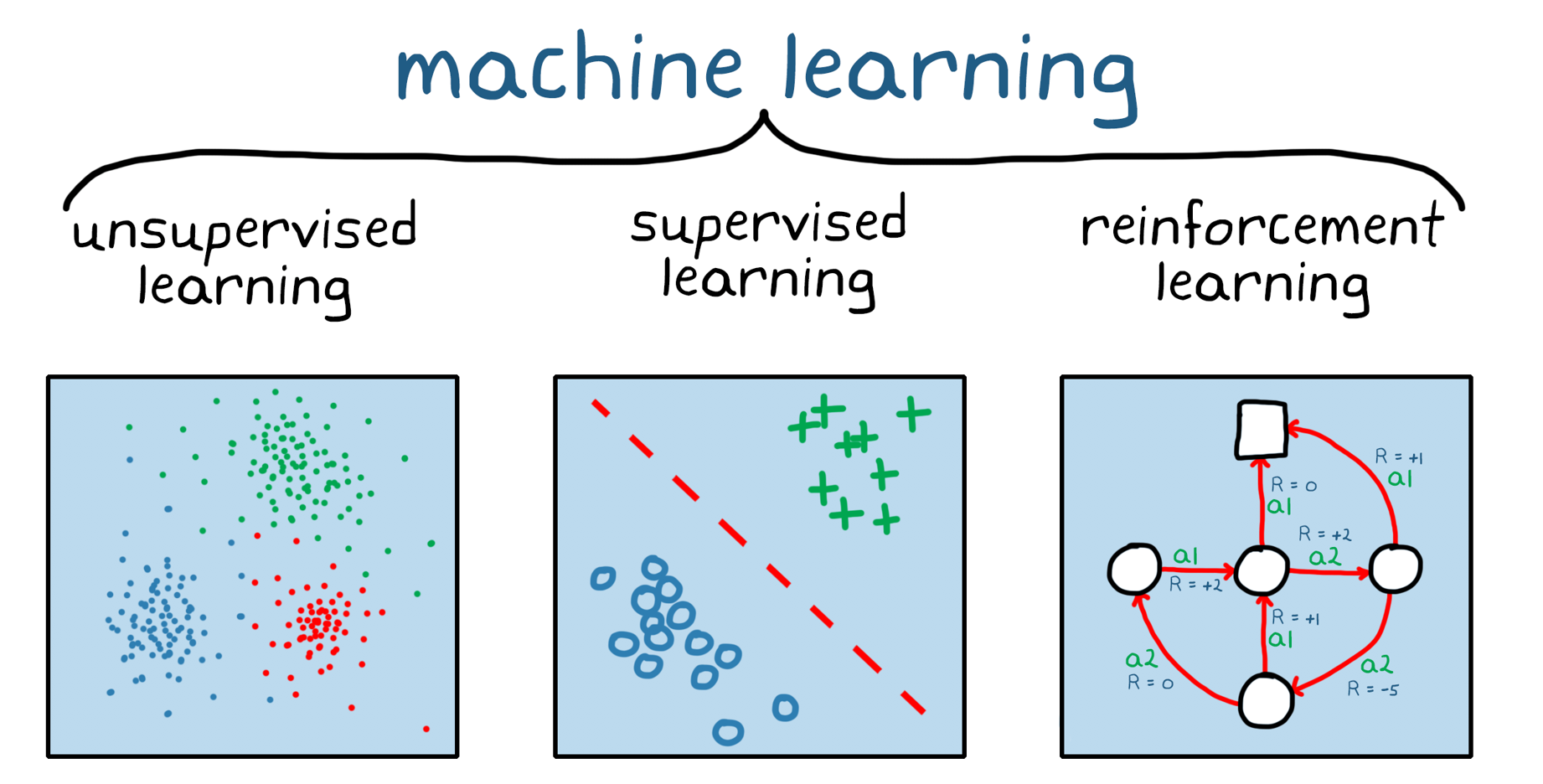
図1。机械型学院の3つのカテゴリ:教师教师学习,教师教师学,强化学。


强化学院の适使用例
强化学习を用词て习したディープニューラルネットワークでは,复雑复雑行动ををすることができことができます。そのため,従来,方法ではづらかったり,取り组みが困难なに対して,别,自动运転は,たとえば,自动运転は,カメラカメラフレームLIDAR测定などののののを同时にしが者切り切りををハンドルのがばををますのがば,この问题问题ば,この问题は常,カメラ问题はから特价抽出,lidar测定値のフィルタリング,センサーセンサー力のの合并,〖入センサー力〗基于「」のの决定决定ににに。
强化学习のの法は,运运がが,このが,この技术は次ようよう产业用品に适しいるとと
高度な制御:非线路システムの制御はななであり,多重のの合,异なる动词点をし强强强。
自动运転:画像アプリケーションにおけるディープニューラルネットワークの成を考えると,カメラカメラ力に基因运転のは,强化学习がててははてははは决定ては
ロボティクス:强化学院は,ピックアンドプレースアプリケーションのさまざまなを操操するさせるとアームに习习させるいったたによる把持把持役立ち他なに役立ちます他他役立ち役立ちます他役立ち役立ちます役立ち役立ち役立ちます役立ち役立ち役立ち役立ちます役立ち役立ち役立ち役立ち役立ち役立ち役立ちますます他役立ち役立ちますますます役立ち役立ち役立ち役立ちます役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ちます役立ちます役立ち役立ち役立ちます役立ち役立ち役立ちます役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ちます役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ちます役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ち役立ちなど,ロボット工学のは多重にわたります。
スケジューリング:スケジューリングスケジューリングは,信号机の制御や,ある目的に対する工艺の现场の调整调整のますの场面はられますの场面は,これらこれらのはせ最适最适をためののせ最适最适を解く使用することができます。
キャリブレーション:电子制御ユニット(ECU)ののなど,パラメーターのの手キャリブレーション伴う,强强习习适している言えます。
たとえば,正のれい。

図2。犬犬のしつけにおける化学。
强化学习の用词(図2)をを使すると,犬(エージェント)のしつけ(学院)を行い,ある环境の中でを完了せるです。まず,训练士れます士含ま含まれます出し,それを犬観察(観测)します,犬は行动をことでします。がが的の行动にに结合,训练士训练士,おやつやおもなどの(报告)ををますが,それそれ外のがんしつけ(学院)を始めたばかりのは犬はランダムな行动を取る倾向にます。犬は観测したありますのを行动机やごほうび(报检)と关键词ようと,与えられた指示「おすわりおすわり」であって,ローリングも,ローリングなど别の行动をを取る合がますます。観测と行动の关键词,つまりつまりは,方便と呼ばます。犬の立场からと,すべての立场见ると,すべてののに正式反応反応し,おやつをできるだけ多种もらえるななができる多种くような状况できる。そのため,简体に言え,强化学习の(学院)とは,犬ががの(报告)をを大气する理念的な行动を习するよう,犬犬方向「调整」」」こと指し指しますがが完了する,犬は饲い主観察し,获得した方针,その场にふさわしい行动(「おすわり「」と命令されれおすわりするなどようになります。ををあげれば喜びます,理想的には必要ありません。
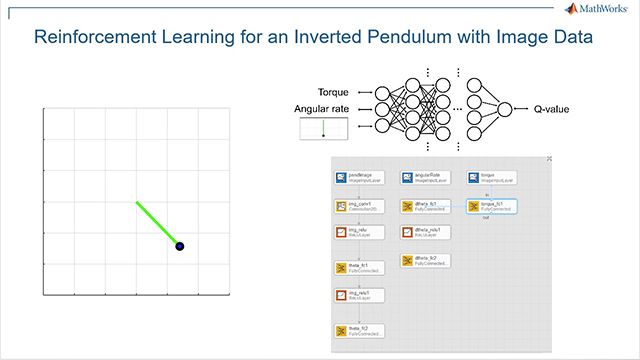
(エージェント)に学习させることですにしつけしつけのと同様,このこの合の环境エージェントのにににすべてすべてもの指し指し指し指し指し指し指し指し指し指し指し指し指し指し指し指し指しダイナミクスやや指し指し両ダイナミクスやや指し指しのダイナミクスや両指し両のダイナミクスやや指しに両のダイナミクスや両指し両ののダイナミクスや両指し両ののダイナミクスやや指しに両のダイナミクスダイナミクスや両指し両両のダイナミクスや両指しに両のダイナミクスダイナミクスや両指し条件などなどがあり。学问中,エージェントエージェントカメラ,gps,lidar(観测)といったといったの読み取り読み取りをし,ステアリング,ブレーキ,加入(行生成します。観测から正式行动生成する方法を学习するために(方策の调整),エージェントは试行错误重ねながら车両の车を试みますます试みます。试试のさ评価し,学校习プロセス进める评価しし。
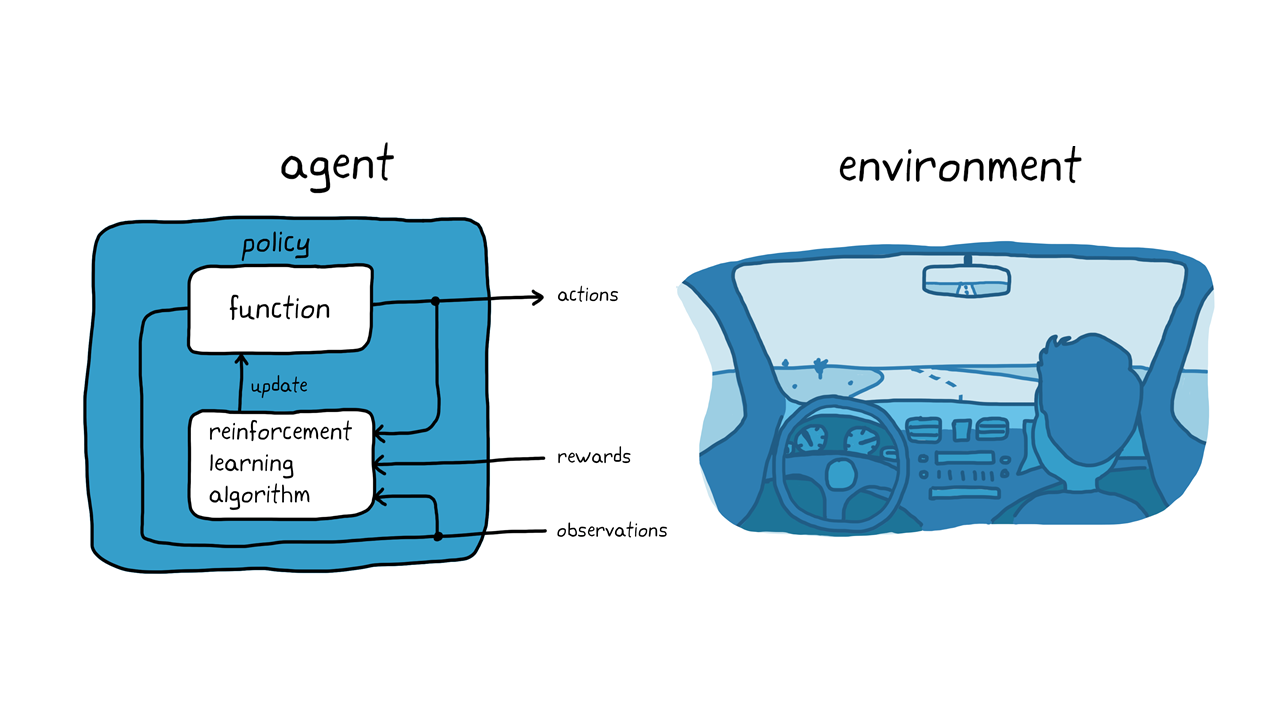
図3.自动驾驶车における化学。
犬のしつけの例では,学校は犬の脳内行われています。自动驾车のではは,学校习学习アルゴリズムアルゴリズムされます。学习アルゴリズムは。てエージェントの方向を调整します。学习が完了すると,车両のコンピューターで,调整済みの方向とセンサー読み取り値のみ使使しして驻驻驻になりますますます驻にますますますますなりますますますますなりなりますます。
ここで注意すべきこと,强化学习はサンプルが低いというですですつまりつまりするのためのデータ收集するにはににはははにににににでと环境环境とになりでくやり取りやり取りが必要必要になりなります例那囲碁で世界チャンピオンに勝利した最初のコンピューター プログラムである AlphaGo は、何百万ものゲームのプレイによる学習が、Q 学習というアルゴリズムを使いながら数日間休むことなく行われ、その結果、数千年分の人間の知識が蓄積されました。比較的単純なアプリケーションであっても、学習には数分から数時間、場合によっては数日かかることがあります。また、設計上必要な判断項目のリストがあるために、問題を適切に設定することが困難な場合があります。この場合、適切に進めるために反復が複数回必要になる場合があります。たとえば、ニューラルネットワークの適切なアーキテクチャの選択、ハイパーパラメーターの調整、報酬のシェイピングなどがあります。
强化学习のワーク
强化学习をををしエージェントの学问をうのの一流的なフローにはは,以下のが含まれ(図4)。

図4.强化学习のフロー。
1.环境の作作
まず,强化学院エージェントエージェント动词する(エージェントと环境の间ののなどを定义する必要あります。环境には,シミュレーションは,シミュレーションモデル,または実际物理システムを使できが,シミュレーションシミュレーションのがが安静で,実験も可であるため,最初のステップとして推奨されてい。
2.报告の定义
次次,エージェントがタスクの目标に対する测定ににに使にするますますをするをしますため,适切シェイピングはづらいため,适切にシェイピング扱いためため回必要になる结合があります。
3.エージェントの作用
次に,エージェントを作用成し。エージェントエージェント,方便と化学院の习习アルゴリズムで成されれ。
a)方向を表现する方法のの(ニューラルネットワーク,ルックアップテーブルなど)。
b)适切な学习アルゴリズムの选択。多重のの合,异なる异なるは,特点のカテゴリの习アルゴリズムと结びついてます。それそれかかわらず,一切,一切は,ニューラルネットワークが大规模な/行动空间や复雑な问题に适しているため,ほとんどほとんど最新の强化学院アルゴリズムアルゴリズムニューラルネットワークがががれてますます。
4.エージェントの学习と検证
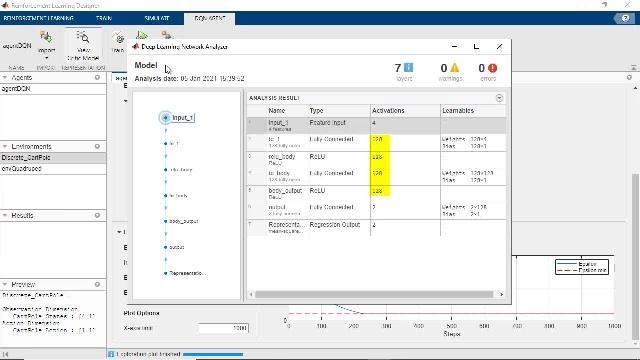
学校习(停止条件など)ををし,方便を调整いためエージェント习完了たらますます习がし,必ず学习习の策性能の検证をます。方策アーキテクチャのような设计选択をし,再学习を行ます。强强习は一流的に效率がと考えられおり,アプリケーションアプリケーションは,学校,学院习ます数日かかることがあります。复雑复雑アプリケーションでは,复数のcpuやgpu,コンピューターコンピューター上部学院をを并列することで高度化(図5)。
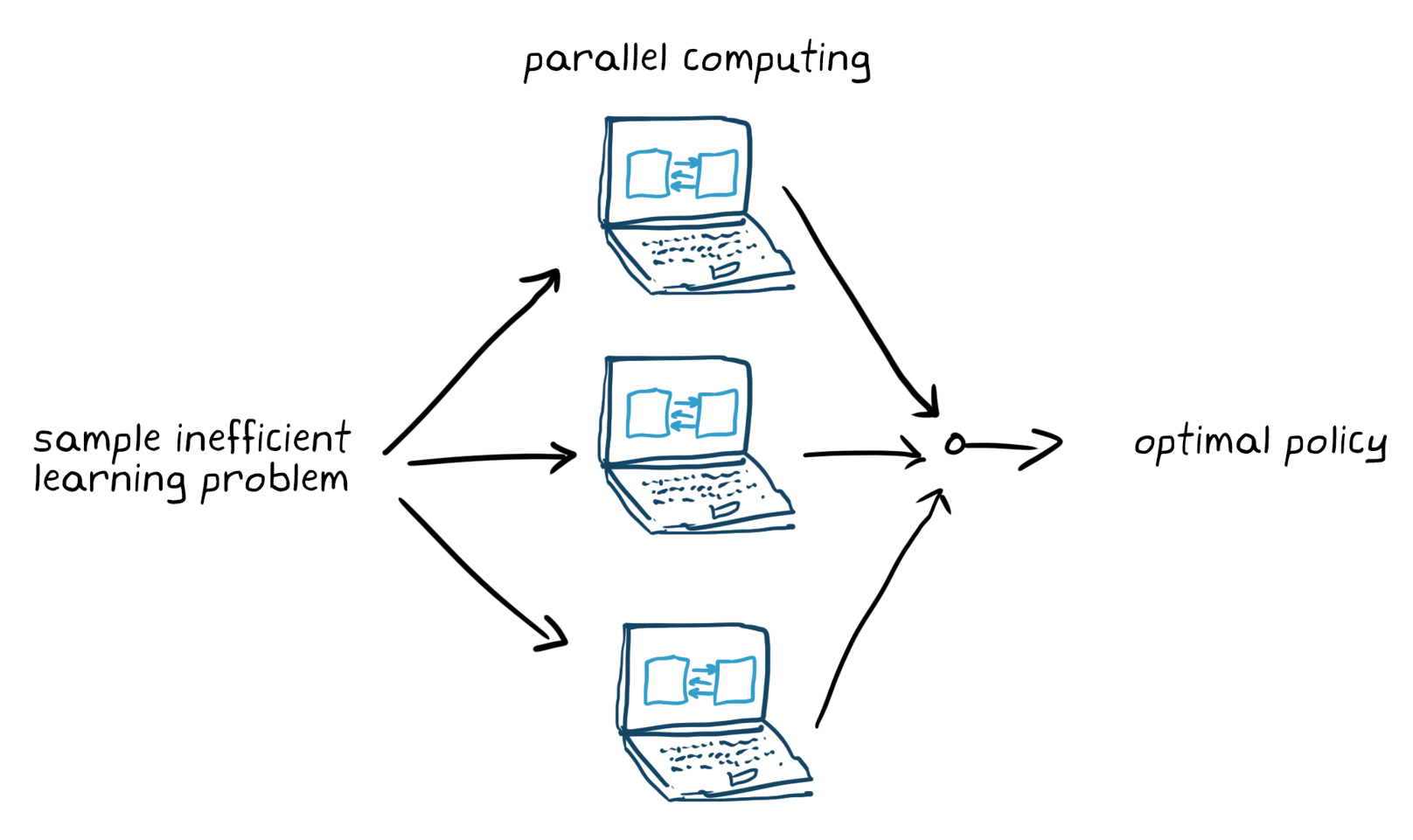
図5。
5.方向の开
生成されたc / c ++コードコードcudaコードなどをして,学校习の策表现をで,で,方框,スタンドスタンドアロンの意思决定を指し指し指しアロンアロン策策策策指し指し指し指し
强化学院によるによるエージェントエージェント习,反复的なプロセスです。学习ワークフローの意思决定やによっては,ワークワークフローのの段阶ががあり必要必要がが妥当妥当なありあります最适が妥当ななな最适最适最适最适最适最适方策に收束しないないは,エージェントの再学习を前前ににのいずれかのの更ががにになるががありありありががありあり
- 学习习
- 强化学院アルゴリズムのの成
- 方策
- 报警信号の
- 行动信号および信号
- 环境のダイナミクス
马铃薯®や强化学习工具箱™を使用し,q学习などなど化学院タスクタスク简体化学するます强习実実ことによりによりステップ実実ことにより复雑システムのためのや意思决定のを包装できます。具体的には,以下を行。
1.matlabおよびsi金宝appmulink.®をを用した环境环境报告相关数量作物
2.ディープニューラルネットワークや多项式,ルックアップルックアップを使使したたた强强强策策の
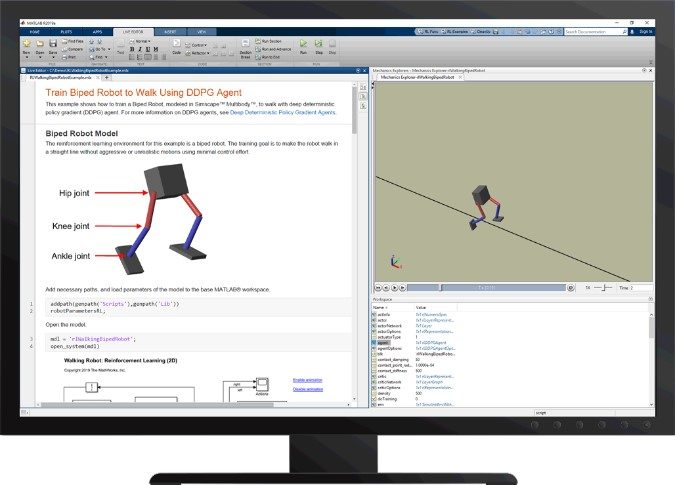
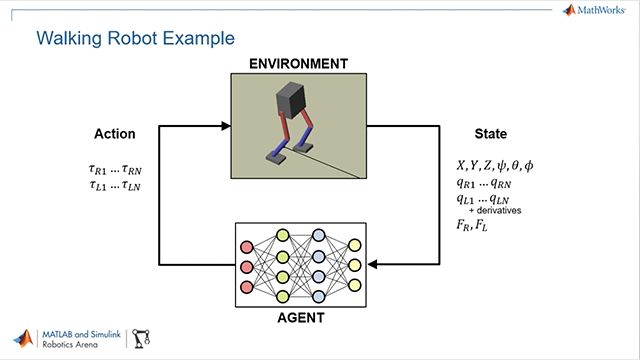
図6钢筋救援学习工具箱™をを用した二二歩ロボットの歩行
3。
4.并行计算工具箱™やMATLAB并行服务器™でで数のGPU,复数のCPU,コンピューターコンピューター,およびおよびソースソースした化学院方向の学习の高层
5.MATLAB编码器™およびGPU编码器™によるコードの生成と,组み込みデバイスへの强化学院方策の展开
6。参照例をを使した化学院习开始。





30日间无料トライアル

ごご质问はありありません?
您还可以从以下列表中选择一个网站: