サポートベクターマシン(SVM)は,信号处理医疗アプリケーションや自然言语处理,音声および画像认识などの多くの分类と回帰の问题に使用される教师あり学习アルゴリズムです。
SVMアルゴリズムの目的は,あるクラスのデータ点を,别のクラスのデータ点から,可能な限り分离する超平面を见つけることです。「最适」は,2つのクラス间で最大のマージンを持つ超平面を指します。以下の図では,これをプラスとマイナスで表しています。マージンとは,内部にデータ点を持たない超平面に平行なスラブの最大幅を意味します。线形分离可能な问题でのみ,そのアルゴリズムはそのような超平面を见つけることができます。ほとんどの现実的な问题では,アルゴリズムは少数の误分类を许容しながら,ソフトマージンを最大化します。
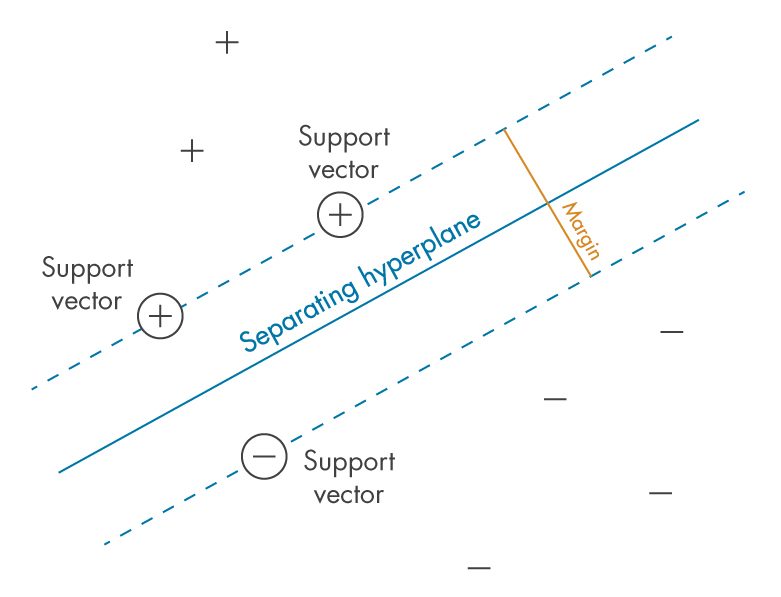
クラス间の「マージン」の定义 - SVMが最适化しようとする基准。
サポートベクターは,学习用観测データの一部で,それを用いて分离超平面の位置を一意に定めることができるものを指します。基本となるSVMアルゴリズムは,バイナリ分类问题用に定式化されたものであるため,マルチクラス分类问题は一般的に,一连のバイナリ分类问题に分解されます。
数学的な详细までより深く掘り下げると,サポートベクターマシンはカーネル法と呼ばれる机械学习アルゴリズムの种类に属します。これは特徴量をカーネル关数を使用して変换することができます。カーネル关数は,この変换によってクラス同士が分离しやすくなると期待して,このデータを别の空间(多くの场合,高次元空间)にマッピングします。その结果,复雑な非线形决定境界は,マッピング后の高次元の特徴空间において,线形决定境界へと単纯化される可能性があります。このプロセスでは,データを明示的に変换する必要はないため,计算コストがかかります。これは,一般的にカーネルトリックとして知られています。
马铃薯®では,次のカーネルに対応しています。
| SVMの种类 | マーサーカーネル | 说明 |
|---|---|---|
| ガウス基底关数または放射基底关数(RBF) | \(K(X_1,X_2)= \ EXP \左( - \压裂{\ | X_1 - X_2 \ | ^ 2} {2 \西格玛^ 2} \右)\) | 1クラス学习。\(\西格玛\)はカーネルの幅 |
| 线形 | \(K(X_1,X_2)= X_1 ^ {\ mathsf【T}} X_2 \) |
バイナリクラス学习。 |
| 多项式 | \(K(X_1,X_2)= \左(X_1 ^ {\ mathsf【T}} X_2 + 1 \右)^ {\ RHO} \) |
\(\ RHO \)は多项式の次数 |
| シグモイド | \(K(X_1,X_2)= \的tanh \左(\ beta_ {0} X_1 ^ {\ mathsf【T}} X_2 + \ beta_ {1} \右)\) |
特定の\(\ beta_ {0} \)和\(\ beta_ {1} \)値のみのマーサーカーネル |
サポートベクターマシンの学习は,クラス间のソフトマージンを最小化するような超平面をあてはめる二次最适化问题を解くことに相当します。変换される特徴量の数は,サポートベクターの数によって决まります。
主なポイント:
- サポートベクターマシンは広く利用されており,多くの分类タスクや回帰タスクで优れた実绩を上げています。
- サポートベクターマシンはバイナリ分类向けに定式化されていますが,复数のバイナリ分类器を组み合わせてマルチクラスSVMを构筑します。
- カーネルによってSVMの柔软性が高まり,非线形问题にも対応できます。
- 决定面を构筑するのに必要なのは,学习データから选択されたサポートベクターのみです。一度学习すると,学习データの残りの部分は不要になるため,自动コード生成に适したコンパクトなモデルを表现できます。
例
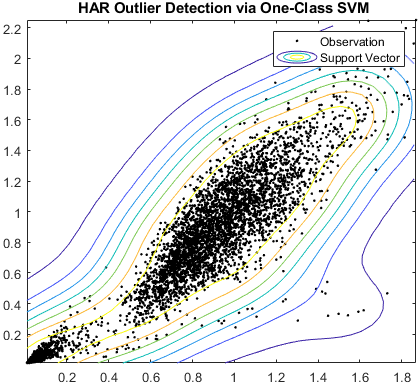
サポートベクターマシンは异常検出にも使用できます。そのためには,决定境界で,外れ値のしきい値を使用してオブジェクトが「通常」クラスに属するかどうかを决定する1クラスSVMを构筑します。この例では,MATLABが,次のように,パラメーターとして外れ値の対象となる割合に基づき,すべてのデータを1つののクラスにマップします..fitcsvm(样本,那些(...),“OutlierFraction”,...)このグラフは,人间行动の分类タスクのデータのOutlierFractionsの范囲の分离超平面を示しています。