このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
fitSVMPosterior
事後確率の近似
構文
説明
ScoreSVMModel= fitSVMPosterior (SVMModel)ScoreSVMModelを返します。
スコアから事後確率への変換関数は,支持向量机分類器SVMModelを使用して近似されます。また,保存されている予測子データ(SVMModel。X)とクラスラベル(SVMModel。Y)を使用して交差検証が実行されます。この変換関数は,観測値が陽性のクラス(SVMModel.Classnames (2))に分類される事後確率を計算します。
クラスが不可分な場合,変換関数はシグモイド関数です。
クラスが完全に可分な場合,変換関数はステップ関数です。
2クラス学習では,クラスの一方の相対的頻度が0の場合,変換関数は定数関数です。
fitSVMPosteriorは1クラス学習には適していません。SVMModelがClassificationSVM分類器である場合,最適な変換関数は10分割交差検証を使用して推定されます([1]を参照してください)。それ以外の場合,SVMModelはClassificationPartitionedModel分類器でなければなりません。SVMModelは交差検証の方法を指定します。最適な変換関数が
ScoreSVMModel。ScoreTransformに格納されます。
ScoreSVMModel= fitSVMPosterior (SVMModel,资源描述,ResponseVarName)SVMModelから,変換関数が含まれている学習済みのサポートベクター分類器を返します。スコア変換関数は,テーブル资源描述内の予測子データとクラスラベル资源描述。ResponseVarNameを使用して推定されます。
ScoreSVMModel= fitSVMPosterior (SVMModel,资源描述,Y)SVMModelから,変換関数が含まれている学習済みのサポートベクター分類器を返します。スコア変換関数は,テーブル资源描述内の予測子データとクラスラベルYを使用して推定されます。
ScoreSVMModel= fitSVMPosterior (SVMModel,X,Y)SVMModelから,変換関数が含まれている学習済みのサポートベクター分類器を返します。予測子データXとクラスラベルYを使用してスコア変換関数が推定されます。
SVMModelがClassificationSVM分類器である場合,<年代pan id="d123e385349" itemprop="syntax">ScoreSVMModel= fitSVMPosterior (<年代pan class="argument_placeholder">___,名称,值)名称,值ペアの引数で指定された追加オプションを使用します。たとえばk分割交差検証で使用する分割の数を指定できます。
さらに,<年代pan id="d123e385374" itemprop="syntax">[は,上記の構文の入力引数のいずれかを使用して,変換関数のパラメーター(ScoreSVMModel,ScoreTransform) = fitSVMPosterior (<年代pan class="argument_placeholder">___)ScoreTransform)を返します。
例
可分クラスについてのスコアから事後確率への変換関数の近似
フィッシャーのアヤメのデータセットを読み込みます。花弁の長さと幅を使用して分類器に学習させ,データからvirginica種を削除します。
负载<年代pan style="color:#A020F0">fisheririsclassKeep = ~ strcmp(物种,<年代pan style="color:#A020F0">“virginica”);X =量(classKeep 3:4);y =物种(classKeep);gscatter (X (: 1) X (:, 2), y);标题(<年代pan style="color:#A020F0">“虹膜测量散点图”)包含(<年代pan style="color:#A020F0">“花瓣长度”) ylabel (<年代pan style="color:#A020F0">“花瓣宽度”)传说(<年代pan style="color:#A020F0">“Setosa”,<年代pan style="color:#A020F0">“多色的”)
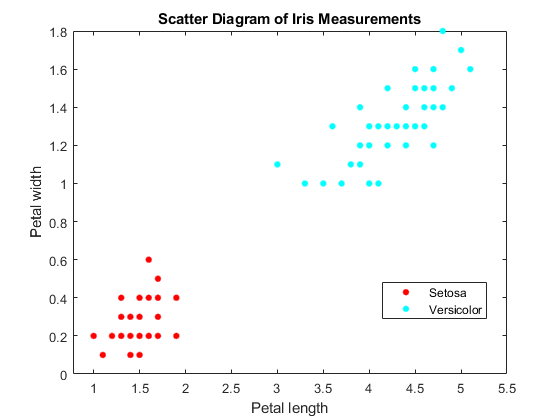
クラスは完全に可分です。そのため,スコア変換関数はステップ関数です。
データを使用してSVM分類器に学習させます。10分割交差検証 (既定) を使用して分類器を交差検証します。
rng (1);CVSVMModel = fitcsvm (X, y,<年代pan style="color:#A020F0">“CrossVal”,<年代pan style="color:#A020F0">“上”);
CVSVMModelは学習させたClassificationPartitionedModel支持向量机分類器です。
スコアを事後確率に変換するステップ関数を推定します。
[ScoreCVSVMModel, ScoreParameters] = fitSVMPosterior (CVSVMModel);
警告:类是完全分离的。最优积分后验变换是一个阶跃函数。
fitSVMPosteriorは次のことを行います。
CVSVMModelに格納されたデータを使用して変換関数を近似します。クラスが可分な場合に警告を表示します。
ステップ関数を
ScoreCSVMModel。ScoreTransformに格納します。
スコア関数の種類とそのパラメーター値を表示します。
ScoreParameters
ScoreParameters =<年代pan class="emphasis">结构体字段:类型:'step' LowerBound: -0.8431 UpperBound: 0.6897 PositiveClassProbability: 0.5000
ScoreParametersは構造体配列であり,次の4つのフィールドがあります。
スコア変換関数の種類(
类型)陰性のクラスの境界に対応するスコア(
下界)陽性のクラスの境界に対応するスコア(
UpperBound)陽性のクラスの確率(
PositiveClassProbability)
クラスは可分なので,ステップ関数はスコアを0または1に変換します。これは,観測値が杂色的種のアヤメである事後確率です。
不可分クラスについてのスコアから事後確率への変換関数の近似
电离层データセットを読み込みます。
负载<年代pan style="color:#A020F0">电离层
このデータセットのクラスは不可分です。
支持向量机分類器を学習させます。10分割交差検証を使用して交差検証します (既定の設定)。予測子を標準化してクラスの順序を指定することをお勧めします。
rng (1)<年代pan style="color:#228B22">%的再现性CVSVMModel = fitcsvm (X, Y,<年代pan style="color:#A020F0">“类名”, {<年代pan style="color:#A020F0">“b”,<年代pan style="color:#A020F0">‘g’},<年代pan style="color:#A020F0">“标准化”,真的,<年代pan style="color:#0000FF">...“CrossVal”,<年代pan style="color:#A020F0">“上”);ScoreTransform = CVSVMModel。ScoreTransform
ScoreTransform = '没有'
CVSVMModelは学習させたClassificationPartitionedModel支持向量机分類器です。陽性のクラスは‘g’です。ScoreTransformプロパティは没有一个。
観測スコアを,‘g’として分類される観測の事後確率にマッピングするために最適なスコア関数を推定します。
[ScoreCVSVMModel, ScoreParameters] = fitSVMPosterior (CVSVMModel);ScoreTransform = ScoreCVSVMModel。ScoreTransform
ScoreTransform = ' @ (S)乙状结肠(e-01 e-01年代,-9.481799,-1.218494)的
ScoreParameters
ScoreParameters =<年代pan class="emphasis">结构体字段:类型:'sigmoid'斜率:-0.9482截距:-0.1218
ScoreTransformは最適なスコア変換関数です。ScoreParametersにはスコア変換関数,勾配の推定値,切片の推定値が格納されています。
ScoreCVSVMModelをkfoldPredictに渡すと,検定標本の事後確率を推定することができます。
検定標本の事後確率の推定
SVMアルゴリズムの検定セットの陽性クラス事後確率を推定します。
电离层データセットを読み込みます。
负载<年代pan style="color:#A020F0">电离层
支持向量机分類器を学習させます。20%のホールドアウト標本を指定します。予測子を標準化してクラスの順序を指定することをお勧めします。
rng (1)<年代pan style="color:#228B22">%的再现性CVSVMModel = fitcsvm (X, Y,<年代pan style="color:#A020F0">“坚持”, 0.2,<年代pan style="color:#A020F0">“标准化”,真的,<年代pan style="color:#0000FF">...“类名”, {<年代pan style="color:#A020F0">“b”,<年代pan style="color:#A020F0">‘g’});
CVSVMModelは学習させたClassificationPartitionedModel交差検証分類器です。
観測スコアを,‘g’として分類される観測の事後確率にマッピングするために最適なスコア関数を推定します。
ScoreCVSVMModel = fitSVMPosterior (CVSVMModel);
ScoreSVMModelは学習させたClassificationPartitionedModel交差検証分類器で,学習データから推定された最適スコア変換関数が含まれます。
標本外の陽性クラス事後確率を推定します。最初の10件の標本外観測の結果を表示します。
[~, OOSPostProbs] = kfoldPredict (ScoreCVSVMModel);indx = ~ isnan (OOSPostProbs (:, 2));hoObs =找到(indx);<年代pan style="color:#228B22">%抵抗观察数字OOSPostProbs = [hobs, OOSPostProbs(indx,2)];表(OOSPostProbs (1:10, 1), OOSPostProbs (1:10), 2),<年代pan style="color:#0000FF">...“VariableNames”, {<年代pan style="color:#A020F0">“ObservationIndex”,<年代pan style="color:#A020F0">“PosteriorProbability”})
ans =<年代pan class="emphasis">10×2表ObservationIndex PosteriorProbability ________________ ____________________ 6 0.17379 7 0.89638 8 0.0076606 9 0.91603 16 0.026714 22 4.6086e-06 23 0.9024 24 2.4131e-06 38 0.00042687 41 0.86427
入力引数
出力引数
詳細
ヒント
以下は,陽性クラスの事後確率を予測する方法の1つです。
データを
fitcsvmに渡し,支持向量机分類器を学習させます。この結果,SVMModelなどの学習済みSVM分類器が生成され,データが格納されます。スコア変換関数プロパティ(SVMModel。ScoreTransformation)が没有一个に設定されます。学習させたSVM分類器
SVMModelをfitSVMPosteriorまたはfitPosteriorに渡します。結果(たとえばScoreSVMModel)はSVMModelと同じ学習済みSVM分類器ですが,最適なスコア変換関数がScoreSVMModel。ScoreTransformationとして設定される点が異なります。最適なスコア変換関数が格納されている学習済みSVM分類器(
ScoreSVMModel)と予測子データ行列を预测に渡します。预测の2番目の出力引数の2列目には,予測子データ行列の各行に対応する陽性クラスの事後確率が格納されます。手順2を省略した場合,
预测は陽性のクラスの事後確率ではなく,陽性のクラスのスコアを返します。
事後確率をあてはめた後で,新しいデータについてラベルを予測するC / c++コードを生成できます。C / c++コードの生成には<年代pan>MATLAB<年代up>®编码器™が必要です。詳細については、コード生成の紹介を参照してください。
アルゴリズム
スコアから事後確率への変換関数を再度推定した場合,つまり,ScoreTransformプロパティが没有一个ではないSVM分類器をfitPosteriorまたはfitSVMPosteriorに渡した場合は,以下の処理が実行されます。
警告が表示されます。
新しい変換関数を推定する前に,元の変換関数が
“没有”にリセットされます。
参照
[1] Platt, J. <支持向量机的概率输出和与正则似然方法的比较>。金宝app在:大边距分类器的进步。麻省理工学院出版社,2000年,61-74页。
参考
ClassificationSVM|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">CompactClassificationSVM|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">ClassificationPartitionedModel|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">fitcsvm|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">预测|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">fitPosterior|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">fitPosterior|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">kfoldPredict
选择网站
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:<年代trong class="recommended-country">.
选择<年代pan class="recommended-country">网站你也可以从以下列表中选择一个网站:
