Dlgradient.
使用自动差异计算自定义训练环路的渐变
描述
采用Dlgradient.计算使用自动分化进行自定义训练循环计算衍生物。
小费
对于大多数深度学习任务,您可以使用备用网络并将其调整到您自己的数据。出于一个示例,展示了如何使用传输学习培育卷积神经网络以对新一组图像进行分类,请参阅火车深学习网络分类新形象.或者,您可以使用从头开始创建和培训网络layerGraph与对象trainNetwork和trainingOptions功能。
如果是trainingOptions功能不提供您需要的培训选项,然后您可以使用自动差异创建自定义训练循环。要了解更多信息,请参阅定义深学习网络定制培训循环.
[返回梯度dydx1,...,dydxk] = dlgradient(y那X1,...,XK)y关于变量X1通过XK..
称呼Dlgradient.从内部功能传递给dlfeval..看使用自动差异计算梯度和使用自动分化深度学习工具箱.
[使用一个或多个名称值对返回梯度和指定的附加选项。例如,dydx1,...,dydxk] = dlgradient(y那X1,...,XK那名称,价值)dydx = dlgradient(y,x,'retaindata',true)使梯度保留中间值以供后续重用Dlgradient.呼叫。此语法可以节省时间,但使用更多内存。有关更多信息,请参阅提示.
例子
使用自动差异计算梯度
的ROSENBROCK的功能是优化标准的测试功能。这rosenbrock.m辅助函数计算功能值,并使用自动微分来计算其梯度。
类型rosenbrock.m
函数[y,就要]=。(x) y = 100 * (x - x(1)(2)。^ 2)。²+ (1 - x(1))²;就要= dlgradient (y、x);结尾
要在点评估的ROSENBROCK的功能及其梯度[-1,2], 创建一个dlarray.点,然后调用dlfeval.在功能手柄@rosenbrock..
X0 = dlarray([ - 1,2]);[FVAL,gradval] = dlfeval(@的ROSENBROCK,X0)
FVAL = 1x1的dlarray 104
Gradval = 1x2 Dlarray 396 200
或者,将RosenBrock的功能定义为两个输入的函数,X1和x2.
类型罗森布罗克2.M.
函数[y,dydx1,dydx2] = rosenbrock2(x1,x2) y = 100*(x2 - x1.^2)²+ (1 - x1)²;[dydx1, dydx2] = dlgradient (y, x1, x2);结尾
称呼dlfeval.评估rosenbrock2两dlarray.表示的输入参数-1和2.
x1 = dlarray(-1);x2 = dlarray(2);[fval,dydx1,dydx2] = dlfeval(@ rosenbrock2,x1,x2)
FVAL = 1x1的dlarray 104
Dydx1 = 1x1美元396
dydx2 = 1x1的dlarray 200
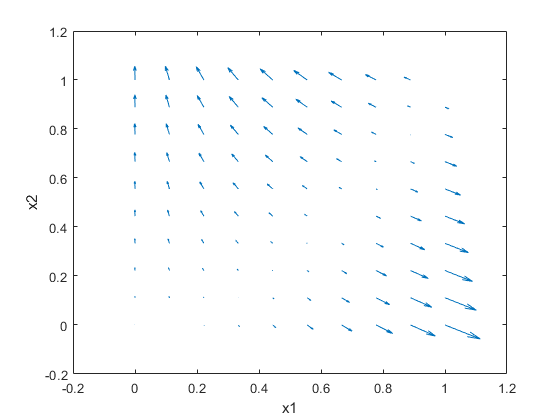
绘制RosenBrock函数的渐变,在单位广场中的几个点。首先,初始化表示评估点和函数输出的阵列。
[x1 x2] = meshgrid(linspace(0,1,10));x1 = dlarray(x1(:));x2 = dlarray(x2(:));y = dlarray(零(尺寸(x1)));dydx1 = y;dydx2 = y;
评估在一个循环的功能。绘制使用结果颤动.
为了i = 1:长度(x1)[y(i),dydx1(i),dydx2(i)] = dlfeval(@ rosenbrock2,x1(i),x2(i));结尾颤动(ExtractData由(X1),ExtractData由(X2),ExtractData由(DYDX1),ExtractData由(DYDX2))xlabel('X1')ylabel('X2')
输入参数
输出参数
限制
这
DLGRIPREDENT.功能不支持计算时计算高阶导数金宝appdlnetwork包含自定义后向后函数的自定义图层的对象。这
DLGRIPREDENT.功能不支持计算时计算高阶导数金宝appdlnetwork对象含有以下层:格拉勒lstmLayerbilstmLayer
这
Dlgradient.函数不支持计算依赖于以下功能的高阶导金宝app数:GRULSTM.嵌入prodinterp1
更多关于
提示
一种
Dlgradient.呼叫必须在函数内。要获得渐变的数值,必须使用函数评估使用dlfeval.,函数的论点必须是一个dlarray..看使用自动分化深度学习工具箱.为了使梯度,在正确评价
y参数必须使用仅支持的功能金宝appdlarray..看与dlarray支持功能列表金宝app.如果你设置了
'etaindata'名称 - 值对参数真的,该软件保留了追踪的持续时间dlfeval.函数调用,而不是衍生计算后立即删除的痕迹。这种防护可能会导致后续Dlgradient.在同一范围内调用dlfeval.调用更快地执行,但使用更多内存。例如,在训练对抗性网络时,'etaindata'设置是有用的,因为两个网络在培训期间共享数据和功能。看火车生成对抗网络(GaN).当你只需要计算一阶导数,确保
'EnableHigherDerivatives'选项是错误的因为这是通常更快,需要较少的存储器。
也可以看看
您还可以从以下列表中选择一个网站:
