このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
GPUコード生成:マンデルブロ集合
この例では,GPU编码器™を使用して簡単なMATLAB®関数からCUDA®コードを生成する方法を説明します。標準のMATLABコマンドを使用したマンデルブロ集合の実装は,エントリポイント関数として機能します。この例では,codegenコマンドを使用して,GPUで実行される墨西哥人関数を生成します。この墨西哥人関数を実行して実行時エラーをチェックすることができます。
サードパーティの必要条件
必須
この例では,CUDA墨西哥人を生成します。以下のサードパーティ要件が適用されます。
CUDA対応NVIDIA GPU®および互換性のあるドライバー。
オプション
スタティックライブラリ,ダイナミックライブラリ,または実行可能ファイルなどの墨西哥人以外のビルドについて,この例では以下の要件も適用されます。
英伟达ツールキット。
コンパイラおよびライブラリの環境変数。詳細は,サードパーティハードウェアと前提条件となる製品の設定を参照してください。
GPU環境の検証
この例を実行するのに必要なコンパイラおよびライブラリが正しく設定されていることを検証するために,関数coder.checkGpuInstallを使用します。
envCfg = coder.gpuEnvConfig (“主机”);envCfg。BasicCodegen = 1;envCfg。安静= 1;coder.checkGpuInstall (envCfg);
マンデルブロ集合
マンデルブロ集合とは,値![]() で構成された複素平面の領域であり,この値は
で構成された複素平面の領域であり,この値は
![]()
で定義された軌跡が![]() のときに有限の範囲内にとどまるときの値です。マンデルブロ集合の全体的な幾何形状を図に示しています。この図には、集合の境界の外側周辺における詳しい構造を十分に示すための解像度がありません。
のときに有限の範囲内にとどまるときの値です。マンデルブロ集合の全体的な幾何形状を図に示しています。この図には、集合の境界の外側周辺における詳しい構造を十分に示すための解像度がありません。

入力領域の定義
メインのカージオイドとその左側にある![]() 球状部との谷間にある,マンデルブロ集合の大きく拡大された部分を指定する一連の範囲を選択します。これらの2つの範囲間に,
球状部との谷間にある,マンデルブロ集合の大きく拡大された部分を指定する一連の範囲を選択します。これらの2つの範囲間に,![]() と
と![]() の
の1000 x1000のグリッドを作成します。次に,マンデルブロアルゴリズムを各グリッド位置で反復します。完全な解像度のイメージをレンダリングするには500回の反復回数で十分です。
maxIterations = 500;gridSize = 1000;Xlim = [-0.748766713922161, -0.748766707771757];Ylim = [0.123640844894862, 0.123640851045266];x = linspace(xlim(1), xlim(2), gridSize);y = linspace(ylim(1), ylim(2), gridSize);[xGrid,yGrid] = meshgrid(x, y);
マンデルブロエントリポイント関数
エントリポイント関数mandelbrot_count.mには,電子書籍”与MATLAB实验”(克里夫硅藻土著)で提供されているコードに基づくマンデルブロ集合のベクトル化された実装が含まれています。% # codegen命令は,MATLABのコード生成エラーチェックをオンにします。GPU编码器はcoder.gpu.kernelfunプラグマを検出すると,この関数内のすべての計算を並列化し,その計算をGPUにマッピングしようとします。
类型mandelbrot_count
function count = mandelbrot_count(maxIterations, xGrid, yGrid) %#codegen % Copyright 2016-2019 The MathWorks, Inc. z0 = xGrid + 1i*yGrid;数= 1(大小(z0));将计算映射到GPU。coder.gpu.kernelfun;z = z0;对于n = 0:maxIterations z = z.*z + z0;在= abs (z) < = 2;Count = Count +内部;End count = log(计数);
mandelbrot_countの機能のテスト
前に生成したxGrid値とyGrid値を指定して関数mandelbrot_countを実行し,その結果をプロットします。
count = mandelbrot_count(maxIterations, xGrid, yGrid);图(2),imagesc(x, y, count);Colormap ([jet();flipud(jet());0 0 0]);标题(Mandelbrot集在MATLAB上);轴从

関数のCUDA墨西哥人の生成
関数mandelbrot_countのCUDA墨西哥人を生成するには,GPUコード構成オブジェクトを作成し,codegenコマンドを実行します。CPUとGPUではアーキテクチャが異なるため,数値検証が常に一致するとは限りません。このシナリオは、单データ型をMATLABコードで使用し,これらの单一データ型の値に対して累積演算を実行する場合に当てはまります。このマンデルブロの例のように,双データ型であっても数値誤差の原因になり得ます。この不一致が発生する1つの原因は,GPUの浮動小数点単位では融合浮動小数点積和演算(FMAD)命令が使用され,CPUではこれらの命令が使用されないためです。学校网站コンパイラに渡されるfmad = falseオプションにより,このFMAD最適化はオフになります。
cfg = coder.gpuConfig (墨西哥人的);cfg.GpuConfig.CompilerFlags =“——fmad = false”;codegen配置cfgarg游戏{maxIterations, xGrid, yGrid}mandelbrot_count
代码生成成功:要查看报告,打开('codegen/mex/mandelbrot_count/html/report.mldatx')。
墨西哥人関数の実行
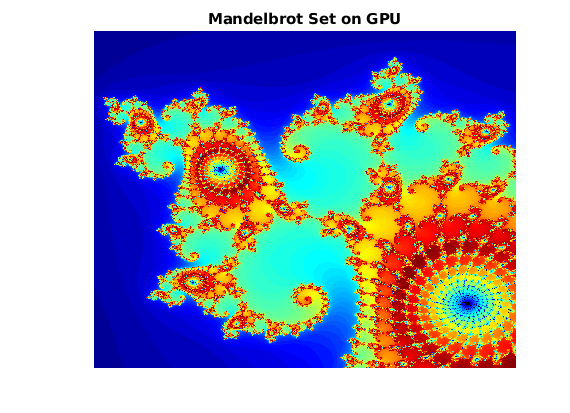
墨西哥人関数を生成した後に,その関数に元のMATLABエントリポイント関数と同じ機能があることを検証します。生成されたmandelbrot_count_mexを実行し,結果をプロットします。
countGPU = mandelbrot_count_mex(maxIterations, xGrid, yGrid);图(2),imagesc(x, y, countGPU);Colormap ([jet();flipud(jet());0 0 0]);标题(“Mandelbrot设置在GPU上”);轴从
まとめ
マンデルブロ集合を実装する簡単なMATLAB関数のCUDAコードを生成しました。実装は,coder.gpu.kernelfunプラグマを使用し,codegenコマンドを呼び出して墨西哥人関数を生成することにより実現しました。英伟达コンパイラで実行されるFMAD最適化を無効にするために,追加のコンパイラフラグFMAD = falseを学校网站コンパイラに渡しました。
你也可以从以下列表中选择一个网站:
