このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
gpuArray
GPUに格納される配列
説明
gpuArrayオブジェクトはGPUに格納される配列を表します。gpuArrayオブジェクトを扱うには,GPU対応のMATLAB®関数を使用します。この配列は直接計算したり,GPUで実行されるCUDAカーネルで使用したりできます。詳細については,GPUでのMATLAB関数の実行を参照してください。
GPUから配列を取得する場合は(gpuArrayオブジェクトをサポートしていない関数を使用する場合など),関数收集を使用します。
メモ
GPUを使用できない場合は,gpuArrayデータが含まれる垫ファイルをメモリ内配列として読み込めます。GPUがない状態で読み込まれたgpuArrayには制限があり,計算には使用できません。GPUがない状態で読み込まれたgpuArrayを使用するには,收集を使用して内容を取得します。
作成
gpuArrayを使用して,MATLABワークスペース内の配列をgpuArrayオブジェクトに変換します。MATLAB関数の多くは、gpuArrayオブジェクトを直接作成することもできます。詳細については,GPUでの配列の確立を参照してください。
入力引数
オブジェクト関数
gpuArrayオブジェクトの特性を調べるためのメソッドがいくつかあります。そのほとんどは同名のMATLAB関数と同様に動作します。
existsOnGPU |
GPUでgpuArrayまたはCUDAKernelが使用可能かどうかを判別する |
isequal |
配列の等価性を判別 |
isnumeric |
入力が数値配列かどうかを判別 |
issparse |
入力がスパースかどうかを判別 |
isUnderlyingType |
入力に基となるデータ型が指定されているかどうかを判別 |
长度 |
最大の配列の次元の長さ |
ndims |
配列の次元数 |
大小 |
配列サイズ |
underlyingType |
配列の動作を決定する基となるデータの型 |
gpuArrayオブジェクト用のその他のメソッドは多すぎるため,ここには記載しません。その多くは,同名のMATLAB関数に似ており,動作も同じです。GPUでのMATLAB関数の実行を参照してください。
例
GPUでのMATLAB関数の使用
この例では,GPU対応のMATLAB関数を使用してgpuArrayを処理する方法を説明します。関数gpuDeviceを使用してGPUのプロパティをチェックできます。
gpuDevice
ans = CUDADevice属性:名称:“GeForce 1080 GTX公司”指数:1 ComputeCapability:“6.1”SupportsDouble: 1 Drive金宝apprVersion: 10.1000 ToolkitVersion: 10.1000 MaxThreadsPerBlock: 1024 MaxShmemPerBlock: 49152 MaxThreadBlockSize: [1024 1024 64] MaxGridSize: [2.1475 e + 09年65535 65535]SIMDWidth: 32 TotalMemory: 8.5899 e + 09 AvailableMemory:6.9012e+09 MultiprocessorCount: 20 ClockRateKHz: 1733500 ComputeMode: 'Default' GPUOverlapsTransfers: 1 KernelExecutionTimeout: 1 CanMapHostMemory: 1 Device金宝appSupported: 1 DeviceSelected: 1
-15 ~ 15の値を繰り返す行ベクトルを作成します。GPUに転送してgpuArrayを作成するには,関数gpuArrayを使用します。
X = [-15:15 0 -15:15 0 -15:15];gpuX = gpuArray (X);谁gpuX
Name Size Bytes Class Attributes gpuX 1x95 4 gpuArray . Name Size Bytes Class Attributes
gpuArrayを処理するには,GPU対応のMATLAB関数を使用します。MATLABは自動的に計算をGPUで実行します。詳細については,GPUでのMATLAB関数の実行を参照してください。たとえば,诊断接头、expm、国防部、轮、腹肌およびfliplrを組み合わせて使用します。
gpuE = expm(diag(gpuX,-1)) * expm(diag(gpuX,1));gpuM =国防部(圆(abs (gpuE)), 2);gpuF = gpuM + fliplr(gpuM);
結果をプロットします。
显示亮度图像(gpuF);colormap(翻转(灰色));

GPUからデータを転送して収集する必要がある場合は,收集を使用します。CPUへの収集は高コストの可能性があるため,gpuArrayをサポートしていない関数で結果を処理する必要がある場合を除いて,一般的に収集は不要です。
结果=收集(gpuF);谁结果
Name Size Bytes Class Attributes result 96x96 73728 double
一般的に,コードをCPUで実行する場合には,GPUとCPUの数値の精度およびアルゴリズムの違いにより結果に差異が生じることがあります。CPUおよびGPUでの解は両方とも,真の解析結果に対して等しく有効な浮動小数点数の近似ですが,計算中に異なる丸めが行われていることがあります。この例の結果は整数であり,轮により丸め誤差が除去されています。
GPU対応関数を使用したモンテカルロ積分の実行
この例では,MATLABの関数と演算子をgpuArraysと共に使用し,モンテカルロ積分法で関数の積分を計算する方法を説明します。
サンプリングする点数を定義します。関数の領域,つまりx座標およびy座標の両方の区間[1]に関数兰德でランダムな点を作成し,その点をサンプリングします。GPU上に乱数の配列を直接作成するには,関数兰德を使用し,“gpuArray”を指定します。詳細については,GPUでの配列の確立を参照してください。
n = 1 e6;x = 2 *兰德(n, 1,“gpuArray”) 1;y = 2 *兰特(n, 1,“gpuArray”) 1;
被積分関数を定義し,それにモンテカルロ積分の式を使用します。この関数は,単位円内の点をサンプリングすることにより の値を近似します。このコードはGPU対応の関数と演算子をgpuArrayに使用するため,計算は自動的にGPUで実行されます。MATLAB配列が使用するものと同じ構文を使用して,要素単位の乗算などの二項演算を実行できます。GPU対応関数の詳細については,GPUでのMATLAB関数の実行を参照してください。
F = x ^2 + y ^2 <= 1;结果= 4 * 1 / n * f ' * (n, 1,“gpuArray”)
结果= 3.1403
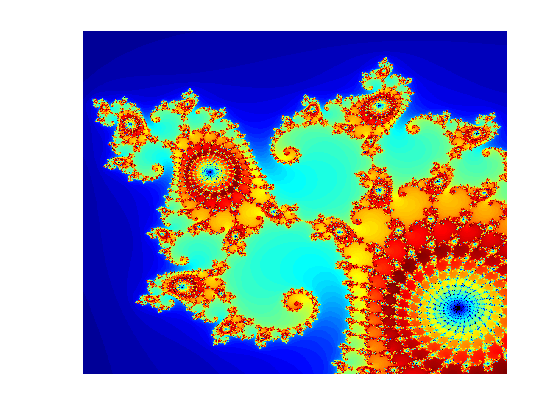
GPU対応関数を使用したマンデルブロ集合の計算
この例では,GPU対応のMATLAB関数を使用して,有名な数学的構成であるマンデルブロ集合を計算する方法を説明します。関数gpuDeviceを使用してGPUをチェックしてください。
パラメーターを定義します。実数部および虚数部のグリッド上にマンデルブロアルゴリズムが反復されます。次のコードは反復回数,グリッドサイズおよびグリッドの範囲を定義します。
maxIterations = 500;gridSize = 1000;Xlim = [-0.748766713922161, -0.748766707771757];Ylim = [0.123640844894862, 0.123640851045266];
関数gpuArrayを使用してデータをGPUに転送し,gpuArrayを作成できます。また,GPU上で直接配列を作成することもできます。gpuArrayはlinspaceなどのデータ配列を作成するために使用できる多くの関数のGPUバージョンを提供します。詳細については,GPU配列の直接作成を参照してください。
xlim x = gpuArray.linspace (xlim (1), (2), gridSize);ylim y = gpuArray.linspace (ylim (1), (2), gridSize);谁xy
Name Size Bytes Class Attributes x 1x1000 4 gpuArray y 1x1000 4 gpuArray
多くのMATLAB関数がgpuArraysをサポートしています。GPU対応関数にgpuArray引数を渡すと,その関数は自動的にGPUで実行されます。詳細については,GPUでのMATLAB関数の実行を参照してください。アルゴリズム用に複素数のグリッドを作成し,結果用に配列数を作成します。GPU上でこの配列を直接作成するには,関数的を使用し,“gpuArray”を指定します。
[xGrid, yGrid] = meshgrid (x, y);z0 =复杂(xGrid yGrid);数= 1(大小(z0),“gpuArray”);
次のコードはGPU対応関数を使用してマンデルブロアルゴリズムを実装しています。このコードはgpuArrayを使用しているため,計算はGPU上で実行されます。
z = z0;为n = 0:maxIterations z = z.*z + z0;内部= abs(z) <= 2;Count = Count +内部;结束数=日志(数);
計算の終了後に結果をプロットします。
Imagesc (x,y,count) colormap([jet();flipud(jet());0 0 0]);轴从
ヒント
パフォーマンスを向上させる必要がある場合,または関数がGPUで使用できない場合,
gpuArrayは次のオプションをサポートしています。gpuArrayオブジェクトに関する純粋に要素単位のコードをプリコンパイルして実行するには,関数arrayfunを使用します。CUDA®デバイスコードまたはライブラリ呼び出しを含むc++コードを実行するには,墨西哥人関数を使用します。詳細については,CUDAコードを含む墨西哥人関数の実行を参照してください。
CUDA c++で記述された既存のGPUカーネルを実行するには,MATLAB CUDAKernelインターフェイスを使用します。詳細については,GPUでのCUDAまたはPTXコードの実行を参照してください。
MATLABコードからCUDAコードを生成するには,GPU编码器™を使用します。詳細については,GPU编码器入門(GPU编码器)を参照してください。
gpurngを使用して,GPUでの乱数ストリームを制御できます。次のいずれも
intmax(“int32”)を超えてはなりません。密配列の要素数。
スパース配列の非ゼロ要素数。
指定された次元のサイズ。たとえば,
0 (0 3 e9 gpuArray)は許可されません。
代替方法
一部のMATLAB関数では,gpuArray出力を指定することにより,gpuArrayオブジェクトを作成することもできます。次の表は,gpuArrayオブジェクトの直接作成に使用できるMATLAB関数の一覧です。
|
|
|
|
|
|
|
gpuArray。结肠 |
|
gpuArray。freqspace |
|
gpuArray。linspace |
|
gpuArray。logspace |
gpuArray。speye |
接頭辞gpuArrayの付く関数について,クラス固有のヘルプを表示するには次を入力します。
帮助gpuArray.functionname
ここで,functionnameはメソッドの名前です。たとえば,结肠のヘルプを表示するには,次のように入力します。
帮助gpuArray.colon
参考
你也可以从以下列表中选择一个网站: