使用强化学习调节PI控制器
这个例子展示了如何使用双延迟深度确定性策略梯度(TD3)强化学习算法来调整PI控制器。将调谐控制器的性能与用该方法调谐的控制器的性能进行了比较控制系统调谐器应用程序。使用控制系统调谐器应用程序在Simulink®中调优控制器需要Simul金宝appink Control Design™软件。
对于具有少量可调参数的相对简单的控制任务,基于模型的调优技术与基于模型的rl方法相比,可以获得较好的效果,且调优过程更快。然而,RL方法更适合于高度非线性系统或自适应控制器整定。
为了便于比较控制器,既调谐方法使用线性二次高斯(LQG)的目标函数。
这个例子使用了一个强化学习(RL)代理来计算PI控制器的增益。关于用神经网络控制器代替PI控制器的例子,请参见创建Simul金宝appink环境和培训代理.
环境模型
本例的环境模型是一个水箱模型。这个控制系统的目的是保持水箱内的水位与参考值相匹配。
Open_System(“watertankLQG”)

该模型包含了具有方差的过程噪声 .
在尽量减少控制的同时保持水位u,本例中的控制器使用以下LQG准则。
为了模拟这种模式控制器,你必须指定仿真时间特遣部队控制器采样时间TS.在几秒钟内。
t = 0.1;Tf = 10;
有关水箱型号的更多信息,请参见watertank仿金宝app真软件模型(金宝app仿真软件控制设计).
调PI控制器使用控制系统优化
要调谐在Simulink控制器使用金宝app控制系统调谐器时,必须指定控制器块作为调谐块并定义用于调谐过程的目标。有关使用的详细信息控制系统调谐器,请参阅使用控制系统调谐器调整控制系统(金宝app仿真软件控制设计).
对于本例,打开保存的会话ControlSystemTunerSession.mat使用控制系统调谐器.中的PID Controller块watertankLQG模型作为调优块,并包含一个LQG调优目标。
controlSystemTuner(“ControlSystemTunerSession”)
调整控制器,在调音选项卡上,单击调优.
调谐的比例增益和积分增益分别约为9.8和1e-6。
Kp_CST = 9.80199999804512;Ki_CST = 1.00019996230706 e-06;
为培训代理创建环境
为了定义训练RL agent的模型,请按照以下步骤修改水箱模型。
删除PID控制器。
插入RL Agent块。
创建观测向量 在哪里 , 油箱的高度是多少 是基准高度。连接观测信号到RL代理块。
将RL代理的奖励函数定义为消极的LQG成本,即 .所述RL剂最大化这种奖励,从而最小化LQG成本。
得到的模型是rlwatertankPIDTune.slx.
mdl =“rlwatertankPIDTune”;open_system (mdl)

创建环境接口对象。要做到这一点,使用localCreatePIDEnv函数的定义。
[env, obsInfo actInfo] = localCreatePIDEnv (mdl);
提取此环境的观察和操作的尺寸。
numObservations = obsInfo.Dimension (1);numActions = prod (actInfo.Dimension);
修复随机发生器种子以进行再现性。
rng (0)
创建TD3代理
鉴于观察,一个TD3代理决定使用一个演员表示要采取的行动。要创建的演员,首先要创建与观察输入和输出的行动深深的神经网络。有关更多信息,请参阅rlDeterministicActorRepresentation.
可以将PI控制器建模为与误差和误差积分观测一个全连接层中的神经网络。
在这里:
u是演员神经网络的输出。Kp和Ki为神经网络权值的绝对值。, 油箱的高度是多少 是基准高度。
梯度下降优化可以带动权重为负值。为了避免负权重,取代正常fullyConnectedLayer与一个fullyConnectedPILayer.该层确保了权重是正通过实现功能
.这个层定义在fullyConnectedPILayer.m.
空间initialGain =单([1E-3 2]);actorNetwork = [featureInputLayer(numObservations,'正常化',“没有”,“名字”,“状态”) fullyConnectedPILayer (initialGain'行动'));actorOptions = rlRepresentationOptions(“LearnRate”1 e - 3,“GradientThreshold”1);演员= rlDeterministicActorRepresentation (actorNetwork obsInfo actInfo,…“观察”, {“状态”},'行动', {'行动'},actorOptions);
一个TD3剂接近长期回报给予意见,并使用两个评论家价值函数表示的动作。要创建的批评,首先要创建有两个输入,观察和行动,以及一个输出的深层神经网络。有关创建深度神经网络值函数表示的更多信息,请参阅创建策略和值函数表示.
要创造批评家,就要使用localCreateCriticNetwork函数的定义。对这两种批评表示使用相同的网络结构。
criticNetwork = localCreateCriticNetwork (numObservations numActions);criticOpts = rlRepresentationOptions (“LearnRate”1 e - 3,“GradientThreshold”1);摘要= rlQValueRepresentation (criticNetwork obsInfo actInfo,…“观察”,“状态”,'行动',“行动”, criticOpts);critic2 = rlQValueRepresentation (criticNetwork obsInfo actInfo,…“观察”,“状态”,'行动',“行动”, criticOpts);[批评家];
使用以下选项配置代理。
设置代理使用控制器样本时间
TS..将小批量大小设置为128个经验样本。
设置体验缓冲区长度1E6。
设置勘探模型和目标政策平滑模型使用高斯噪声的方差0.1。
使用以下方法指定TD3代理选项rlTD3AgentOptions.
agentOpts = rlTD3AgentOptions (…'采样时间'Ts,…'minibatchsize', 128,…“ExperienceBufferLength”1 e6);agentOpts.ExplorationModel.Variance = 0.1;agentOpts.TargetPolicySmoothModel.Variance = 0.1;
创建使用指定的演员表示,批评者表示,与代理选项TD3剂。有关更多信息,请参阅rlTD3AgentOptions.
代理= rlTD3Agent(演员、评论家、agentOpts);
火车代理
为了培养剂,先指定下列培训选项。
运行最多每次培训
1000发作,每次发作持续至多100时间的步骤。在章节管理器中显示培训进度(设置
绘图选项)并禁用命令行显示(设置详细的选项)。当代理在100个连续的事件中获得平均累积大于-355的奖励时,停止训练。此时,药剂可以控制水箱内的水位。
有关更多信息,请参阅rlTrainingOptions.
maxepisodes = 1000;maxsteps =装天花板(Tf / Ts);trainOpts = rlTrainingOptions (…'maxepisodes'maxepisodes,…'MaxStepsPerEpisode'maxsteps,…“ScoreAveragingWindowLength”, 100,…'verbose'假的,…“阴谋”,“训练进步”,…“StopTrainingCriteria”,'AverageReward',…“StopTrainingValue”,-355);
使用列车上的代理火车功能。培训本剂是一种计算密集型过程,需要几分钟才能完成。要在运行此示例的同时节省时间,请通过设置加载预制代理doTraining来假.自己训练代理人,设置doTraining来真正的.
doTraining = false;如果doTraining培训代理商。Trainstats =火车(代理,env,训练);其他的%负载净化代理。负载(“WaterTankPIDtd3.mat”,'代理人')结束

验证训练有素的代理
通过仿真验证了该模型的有效性。
simOpts = rlSimulationOptions ('MaxSteps', maxsteps);经验= sim (env,代理,simOpts);
PI控制器的积分和比例增益是演员表示的绝对权重。为了获得权重,第一次提取从演员的可以学习的参数。
演员= getActor(代理);参数= getLearnableParameters(演员);
获取控制器增益。
Ki = abs(参数{1}(1))
Ki =单0.3958
Kp = abs(参数{1}(2))
Kp =单8.0822
应用来自RL剂到原始PI控制器块获得的增益和运行一个阶跃响应仿真。
mdlTest =“watertankLQG”;open_system (mdlTest);set_param ([mdlTest/ PID控制器的],“P”num2str (Kp) set_param ([mdlTest/ PID控制器的],'一世'num2str (Ki) sim (mdlTest)
提取阶跃响应信息,LQG成本,并为模拟稳定裕度。为了计算稳定裕度,使用localStabilityAnalysis函数的定义。
rlStep = simout;rlCost =成本;rlStabilityMargin = localStabilityAnalysis(mdlTest);
应用使用所获得的收益控制系统调谐器,并运行阶跃响应仿真。
set_param ([mdlTest/ PID控制器的],“P”num2str (Kp_CST) set_param ([mdlTest/ PID控制器的],'一世',num2str(Ki_CST)) sim(mdlTest) cstStep = simout;cstCost =成本;cstStabilityMargin = localStabilityAnalysis (mdlTest);
控制器的性能比较
绘制每个系统的阶跃响应。
图绘制(cstStep)在图(rlStep)网格在传奇(“控制系统优化”,'RL',“位置”,'东南') 标题(的阶跃响应)
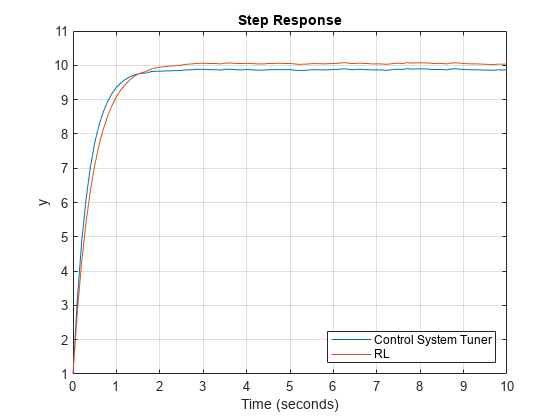
分析两种仿真的阶跃响应。
rlStepInfo = stepinfo (rlStep.Data rlStep.Time);cstStepInfo = stepinfo (cstStep.Data cstStep.Time);stepInfoTable = struct2table([cstStepInfo rlStepInfo]);stepInfoTable = removevars (stepInfoTable, {…'SettlingMin',“SettlingMax”,“脱靶”,“PeakTime”});stepInfoTable.Properties.RowNames = {“控制系统优化”,'RL'};stepInfoTable
stepInfoTable =2×5表上升时间TransientTime SettlingTime过冲峰值________ _____________ ____________ _________ ______控制系统调谐器0.77737 1.3594 1.3278 0.33125 9.9023 0.98024 RL 1.7408 1.7073 0.40451 10.077
分析两个仿真的稳定性。
stabitymargintable = struct2table([cstStabilityMargin rlStabilityMargin]);stabilityMarginTable = removevars (stabilityMarginTable, {…'GMFrequency',“PMFrequency”,“DelayMargin”,“DMFrequency”});stabilityMarginTable.Properties.RowNames = {“控制系统优化”,'RL'};stabilityMarginTable
stabilityMarginTable =2×3表控制系统调谐器8.1616 84.124真RL 9.9226 84.242真
比较两个控制器的累计LQG成本。rl调谐控制器产生了稍微更优的解决方案。
rlCumulativeCost =总和(rlCost.Data)
rlCumulativeCost = -375.9135
cstCumulativeCost =总和(cstCost.Data)
cstCumulativeCost = -376.9373
两个控制器产生稳定的响应,控制器调谐使用控制系统调谐器产生更快的响应。然而,RL调优方法产生更高的增益裕度和更优的解决方案。
本地函数
命令功能,创建水箱RL环境。
函数[env, obsInfo actInfo] = localCreatePIDEnv (mdl)%定义观察规范obsInfo和操作规范actInfo。obsInfo = rlNumericSpec([2 1]);obsInfo。Name =“意见”;obsInfo。描述=“综合误差和错误”;actInfo = rlNumericSpec([1 1]);actInfo。Name =“PID输出”;%构建环境接口对象。(mdl env金宝app = rlSimulinkEnv (mdl,' / RL代理', obsInfo actInfo);%设置一个自定义重置函数,随机化模型的参考值。env。ResetFcn = @(在)localResetFcn (, mdl);结束
函数随机参考信号和初始高度的水箱在每集开始。
函数在= localResetFcn(在,MDL)%随机化参考信号BLK = sprintf的([MDL' /期望\ nWater水平']);hRef = 10 + 4*(rand-0.5);在= setBlockParameter(黑色,“价值”,num2str(HREF));%随机化初始高度hInit = 0;黑色= [mdl“水箱系统/ H”];在= setBlockParameter(黑色,“InitialCondition”num2str (hInit));结束
函数用于线性化和计算SISO水箱系统的稳定裕度。
函数余量= localStabilityAnalysis(MDL)10(1)=的LiNiO([MDL' / Sum1 '), 1“输入”);IO(2)=的LiNiO([MDL/水箱系统的), 1“openoutput”);op = operpoint (mdl);op.Time = 5;linsys =线性化(mdl io, op);利润= allmargin (linsys);结束
命令功能,创建评论家网络。
函数statePath = [featureInputLayer(numObservations, numActions),'正常化',“没有”,“名字”,“状态”) fullyConnectedLayer (32,“名字”,“fc1”));actionPath = [featureInputLayer(numActions,'正常化',“没有”,“名字”,“行动”) fullyConnectedLayer (32,“名字”,“取得”));commonPath = [concatenationLayer(1,2,)]“名字”,“concat”) reluLayer (“名字”,“reluBody1”) fullyConnectedLayer (32,“名字”,“fcBody”) reluLayer (“名字”,“reluBody2”)全康连接层(1,“名字”,“qvalue”));criticNetwork = layerGraph ();criticNetwork = addLayers (criticNetwork statePath);criticNetwork = addLayers (criticNetwork actionPath);criticNetwork = addLayers (criticNetwork commonPath);criticNetwork = connectLayers (criticNetwork,“fc1”,“concat /三机一体”);criticNetwork = connectLayers (criticNetwork,“取得”,“concat / in2”);结束
另请参阅
相关的话题
你也可以从以下列表中选择一个网站: