このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
分類学習器アプリを使用した決定木の学習
この例では,分類学習器を使用してさまざまな分類木を作成および比較する方法と,新しいデータについて予測を行うために学習済みのモデルをワークスペースにエクスポートする方法を示します。
データに対する応答を予測するように分類木を学習させることができます。応答を予測するには,ツリーのルート(開始)ノードから葉ノードの方向に意思決定を行います。葉ノードには応答が含まれます。
统计和机器学习工具箱™のツリーは二分木です。予測の各段階では1つの予測子(変数)について値のチェックが行われます。たとえば,次の図は単純な分類木を示しています。
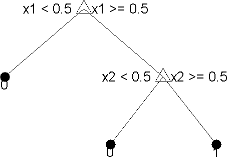
このツリーでは2つの予測子x1とx2に基づいて分類を予測します。予測は最上位のノードから始まります。各決定では,予測子の値をチェックして,どの分岐に進むかを決定します。分岐がリーフノードに達すると,データは0または1のタイプに分類されます。
MATLAB®で,
fisheririsデータセットを読み込みます。このデータセットの変数から,分類に使用する測定予測子(特徴)のテーブルを作成しますfishertable = readtable (“fisheriris.csv”);[アプリ]タブの[機械学習および深層学習]グループで[分類学習器]をクリックします。
[分類学習器]タブの[ファイル]セクションで,(新規セッション],[ワークスペースから]をクリックします。

[ワークスペースからの新規セッション]ダイアログボックスで,[データセット変数)のリストから表
fishertableを選択します(必要な場合)。データ型に基づいて応答および予測子変数が選択されていることを確認します。花弁とがく片の長さおよび幅は予測子,種は分類対象の応答です。この例では,選択を変更しないでください。
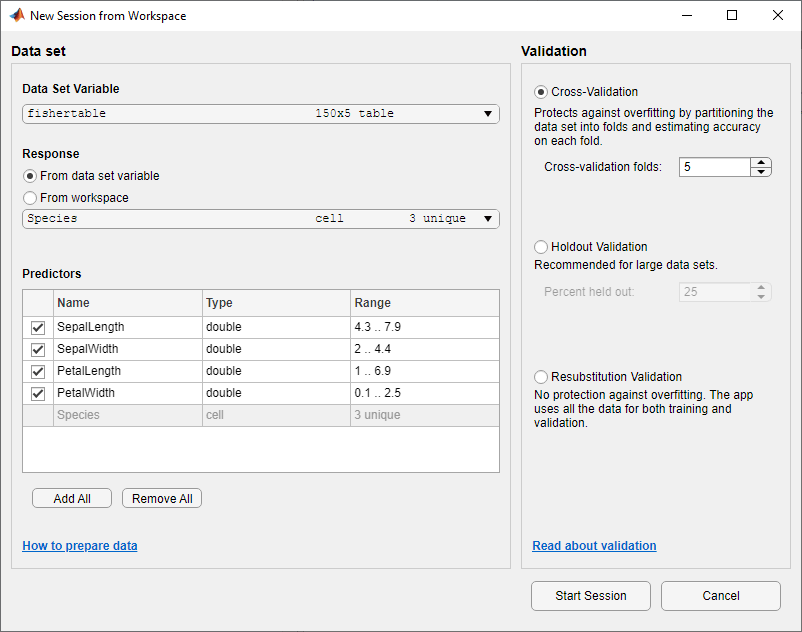
既定の検証方式をそのまま使用して続行するため,[セッションの開始)をクリックします。既定の検証オプションは,過適合を防止する交差検証です。
データの散布図が作成されます。
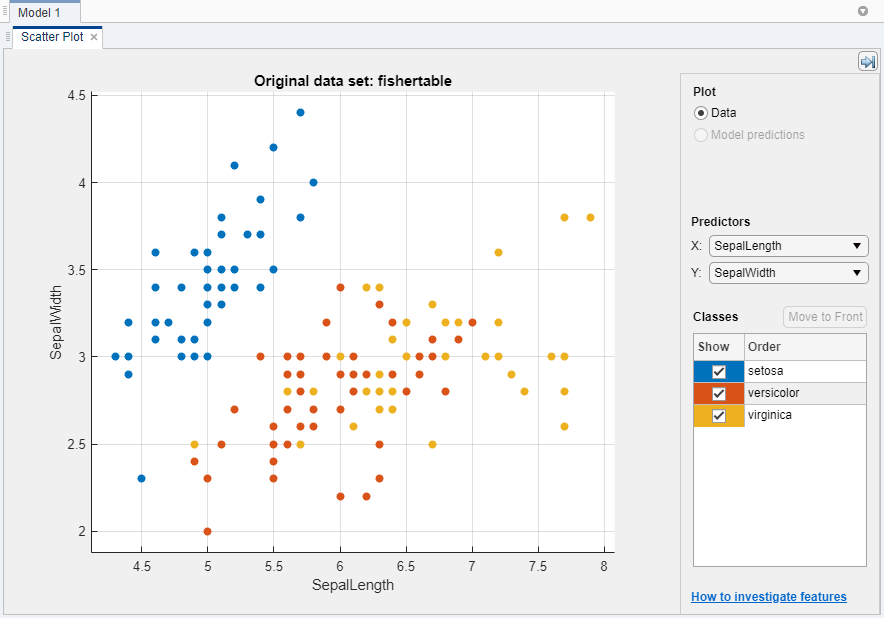
散布図を使用して,どの変数が応答の予測に有用であるかを調べます。[予測子]の[X]および[Y]のリストで異なるオプションを選択して,種と測定値の分布を可視化します。種の色が最も明確に分離されるのはどの変数であるかを調べます。
4つの予測子すべてに関して
setosa種(青い点)が他の2つの種から容易に分離されることを確認します。多色的種とvirginica種はどの予測子の測定値でも接近しており,特にがく片の長さと幅をプロットした場合は重なります。setosaは,他の2つの種よりも予測が容易です。分類木モデルを作成するため,[分類学習器]タブの[モデルタイプ]セクションで下矢印をクリックしてギャラリーを展開してから(粗い木)をクリックします。次に,[学習]をクリックします。
単純な分類木が作成され,結果がプロットされます。
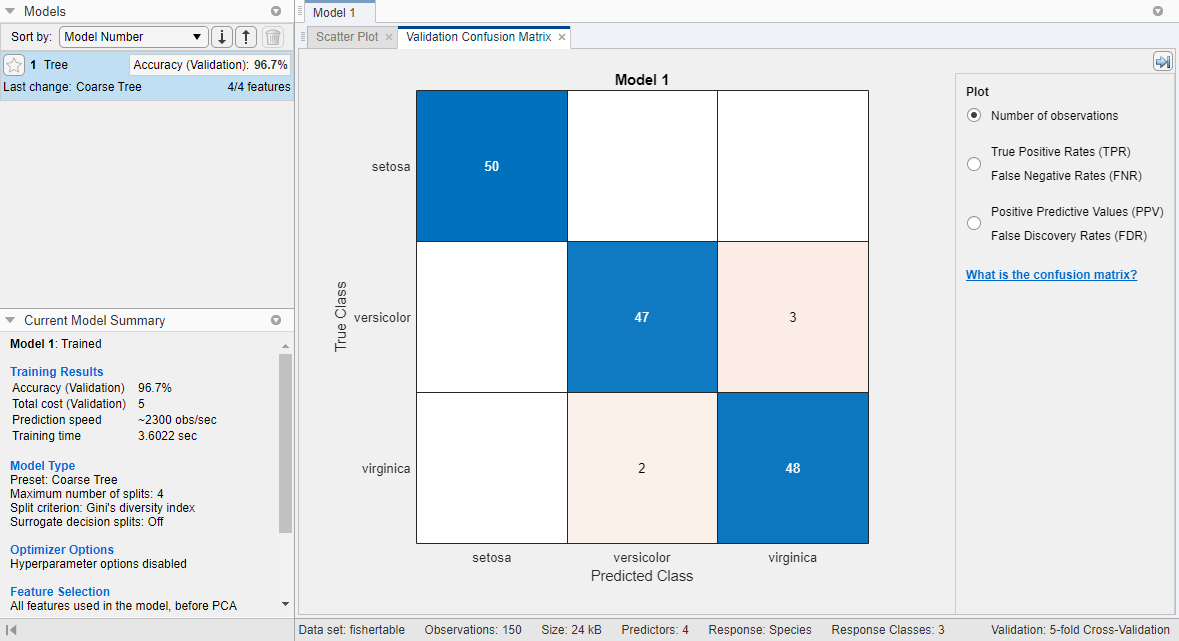
[モデル]ペインで(粗い木)モデルを確認します。モデル検証スコアを[精度 (検証)]ボックスで確認します。このモデルは良好に機能しました。
メモ
検定の結果には無作為性があるので,実際のモデル検定スコアはここに示されている結果と異なる場合があります。
散布図を確認します。Xは誤分類された点を示しています。青い点(
setosa種)はすべて正しく分類されていますが,他の2つの種は一部が誤分類されています。[プロット]で[データ]と[モデル予測]を切り替えます。正しくない点(X)の色を確認します。または、モデル予測をプロットするときに、正しくない点のみを表示するため、[正]チェックボックスをクリアします。比較のため,別のモデルを学習させます。(中程度の木)をクリックしてから[学習]をクリックします。
[学習]をクリックすると,新しいモデルが[モデル]ペインに表示されます。
[モデル]ペインで(中程度の木)モデルを確認します。モデル検定スコアは,粗い木のスコアと変わりません。最適なモデルの[精度 (検証)]スコアの概要がボックスに表示されます。[モデル]ペインで各モデルをクリックして,結果を表示および比較します。
(中程度の木)モデルの散布図を確認します。(中程度の木)では、前の [粗い木] と同じ数の点が正しく分類されます。過適合を回避する必要があり、粗い木は適切に機能するので、以後のすべてのモデルで粗い木を基準にします。
[モデル]ペインで(粗い木)を選択します。モデルを改善するため,別の機能をモデルに含めてみます。予測力が低い特徴量を削除するとモデルを改善できるかどうか調べます。
[分類学習器]タブの[特徴量]セクションで[特徴選択]をクリックします。
予測子から除外するため,[特徴選択]ダイアログボックスで(PetalLength)と(PetalWidth)のチェックボックスをクリアします。粗い木に基づく新しいドラフトモデルが,2/4の特徴量という新しい設定で[モデル]ペインに表示されます。
新しい予測子のオプションを使用して新しい木モデルに学習をさせるため,[学習]をクリックします。
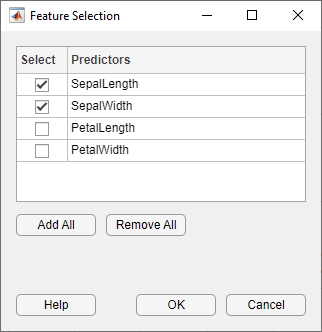
[モデル]ペインで3番目のモデルを確認します。これも(粗い木)モデルで4つの予測子のうち2つだけを学習に使用しています。除外した予測子の数が表示されます。どの予測子が含まれているかをチェックするには,[モデル]ペインでモデルをクリックし,[特徴選択]ダイアログボックスのチェックボックスを確認します。がく片の測定値のみが含まれているモデルは,花弁のみのモデルより精度のスコアがはるかに低くなります。
花弁の測定値のみが含まれている別のモデルを学習させます。(特徴選択]ダイアログボックスの選択を変更して[学習]をクリックします。
花弁の測定値のみを使用して学習させたモデルは,すべての予測子が含まれているモデルと同程度に機能します。すべての測定値を使用した場合でも花弁の測定値のみを使用した場合でも、モデルによる予測に変わりはありません。データの収集が高価または困難な場合、一部の予測子がなくても十分に機能するモデルが好ましい可能性があります。
幅の測定値のみが含まれているモデルと長さの測定値のみが含まれているモデルについて学習を繰り返します。いくつかのモデルでは,スコアに大きい違いがありません。
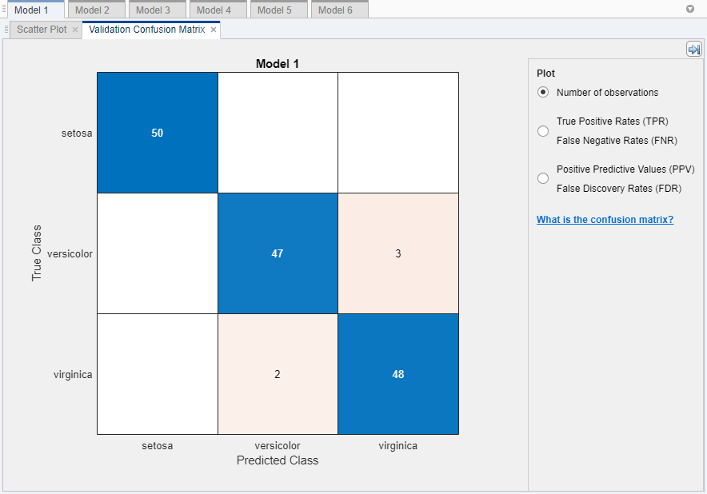
各クラスの性能を調べて,類似したスコアの中から最適なモデルを選択します。すべての予測子が含まれている粗い木を選択します。各クラスにおける予測子の精度を調べるには,[分類学習器]タブの[プロット]セクションで[混同行列]をクリックし,(検証データ]を選択します。このプロットを使用すると,現在選択している分類器が各クラスでどのように機能したかを理解できます。真のクラスと予測したクラスの結果が含まれている行列が表示されます。
分類器が十分には機能しなかった領域を探すには,数値が大きく赤で表示されている対角線外のセルを確認します。このような赤いセルでは,真のクラスと予測したクラスが一致していません。データ点は誤分類されています。
メモ
検定では結果に無作為性があるので,実際の混同行列の結果はここに示されているものと異なる場合があります。
この図で,中央の行の3番目のセルを確認します。このセルの真のクラスは
多色的ですが,点がvirginicaに誤分類されています。このモデルでは2つが誤分類されたことがセルに示されています(結果は異なる場合があります)。観測値の数ではなく比率を表示するには,[プロット]のコントロールで[真陽性率]を選択します。この情報は,目標に最適なモデルを選択するために役立てることができます。このクラスの偽陽性が分類問題にとって非常に重要な場合は,このクラスを最適に予測するモデルを選択します。このクラスの偽陽性があまり重要ではなく,予測子が少ないモデルの方が他のクラスで良好に機能する場合は,全体的な精度の優先度を多少低くするために一部の予測子を除外したモデルを選択し,将来のデータ収集を容易にします。
[モデル]ペインに含まれている各モデルについて混同行列を比較します。どの予測子が各モデルに含まれているか調べるには,[特徴選択]ダイアログボックスを確認します。
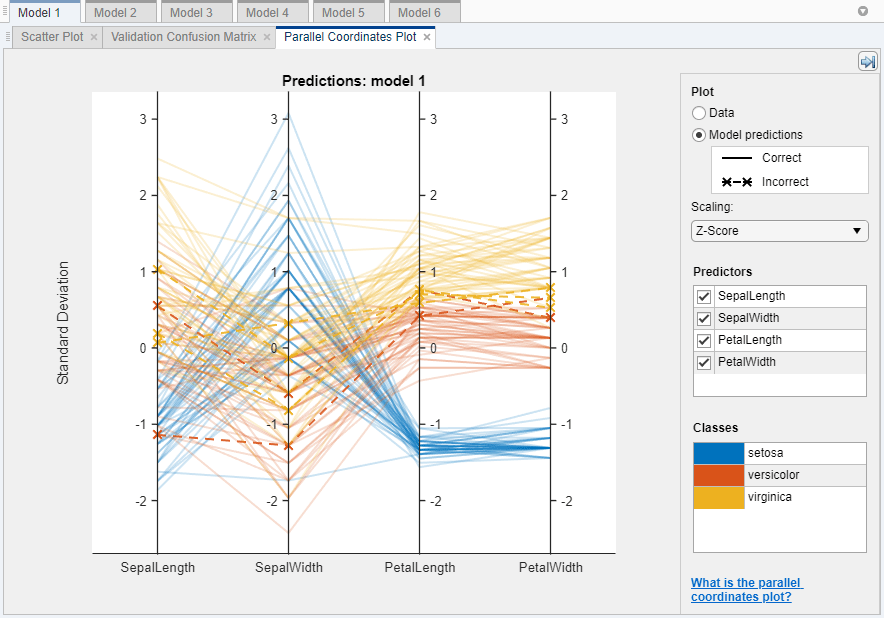
追加または除外する特徴量を調べるには,散布図と平行座標プロットを使用します。[分類学習器]タブの[プロット]セクションで,[平行座標]をクリックします。クラスを最適に分離する特徴は花弁の長さと花弁の幅であることがわかります。
モデルの設定を調べるには,[モデル]ペインでモデルを選択し,詳細設定を表示します。[モデルタイプ]ギャラリーの最適化不可能なモデルオプションは事前設定された開始点であり,さらに設定を変更できます。[分類学習器]タブの[モデルタイプ]セクションで[詳細設定]をクリックします。[モデル]ペインに含まれている単純な木のモデルと中程度の木のモデルを比較し,[ツリーの詳細オプション]ダイアログボックスで違いを調べます。ツリーの深さは,[最大分割数]の設定により制御されます。
粗い木のモデルをさらに改善するには,[最大分割数]の設定を変更してから[学習]をクリックして新しいモデルに学習をさせます。
[現在のモデルの概要)ペインまたは[詳細設定]ダイアログボックスで,選択した学習済みモデルの設定を確認します。
最適な学習済みのモデルをワークスペースにエクスポートするため,[分類学習器]タブの[エクスポート]セクションで[モデルのエクスポート]をクリックします。[モデルのエクスポート]ダイアログボックスで(好的)をクリックすると,既定の変数名
trainedModelがそのまま使用されます。結果に関する情報はコマンドウィンドウに出力されます。
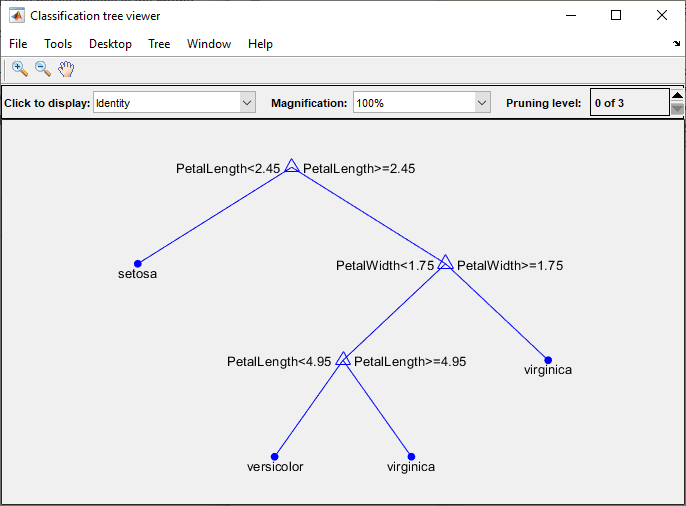
決定木モデルを可視化するには,次のように入力します。
视图(trainedModel。ClassificationTree,“模式”,“图”)
エクスポートした分類器を使用して,新しいデータに対して予測を行うことができます。たとえば,ワークスペースにある
fishertableのデータについて予測を行うには,次のように入力します。出力のyfit = trainedModel.predictFcn (fishertable)
yfitには,データ点ごとのクラスの予測が含まれています。新しいデータを使用して同じ分類器を学習させる処理を自動化したり,プログラムで分類器を学習させる方法について調べるには,このアプリでコードを生成します。最適な学習済みモデルのコードを生成するには,[分類学習器]タブの[エクスポート]セクションで[関数の生成)をクリックします。
コードがモデルから生成され,ファイルがMATLABのエディターに表示されます。詳細については,新しいデータでモデルに学習をさせるMATLABコードの生成を参照してください。








この例では,フィッシャーによる1936個のアヤメのデータを使用します。このアヤメのデータには,3種の標本について花弁の長さ,花弁の幅,がく片の長さ,がく片の幅という花の測定値が含まれています。予測子の測定値に基づいて種を予測するように分類器を学習させます。
このワークフローを使用すると,分類学習器で学習させることができる他のタイプの分類器を評価および比較できます。
選択したデータセットに対して使用できる事前設定済みの最適化不可能な分類器モデルをすべて試すには,次のようにします。
[モデルタイプ]セクションの右端にある矢印をクリックして分類器のリストを展開します。
[すべて]をクリックしてから[学習]をクリックします。

他の分類器のタイプについては,分類学習器アプリにおける分類モデルの学習を参照してください。
関連するトピック
你也可以从以下列表中选择一个网站:
