bm25Similarity
与BM25算法的文档相似度
句法
描述
使用bm25Similarity计算文档相似之处。
默认情况下,此函数计算BM25的相似之处。计算BM11,BM15或BM25 +相似之处,使用“DocumentLengthScaling”和'DocumentLengthCorrection'论点。
相似之处= bm25similarity(___那名称,价值)'DocumentLengthCorrection'选项为非零值。
例子
文档之间的相似度
创建一系列令牌文档。
textData = ["那只敏捷的棕色狐狸跳过了那只懒狗"“快速的棕色狐狸跳过懒狗”“懒狗坐在那里,没有什么”“其他动物坐在那里观看”];文档= tokenizeddocument(textdata)
文档= 4x1令牌Document:9令牌:快速的棕色狐狸跳过懒狗9令牌:快速的棕色狐狸跳过懒狗8令牌:懒狗坐在那里,没有什么6令牌:其他动物坐在那里
计算它们之间的相似之处bm25Similarity功能。输出是稀疏矩阵。
相似性= bm25Similarity(文件);
在热图中可视化文档的相似之处。
图热图(相似之处);Xlabel(“文档”) ylabel (“文档”) 标题(“BM25相似之处”)
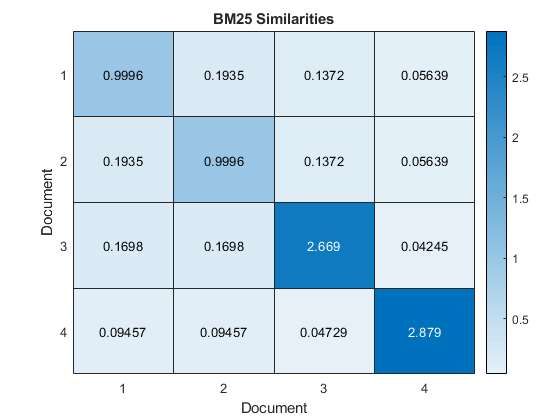
前三个文件具有最高的成对相似性,这表明这些文件最相似。最后一份文档与其他文档相对低的成对相似性,这表明本文档不像其他文档。
与查询的相似之处
创建一个输入文档数组。
str = ["那只敏捷的棕色狐狸跳过了那只懒狗""快狐狸跳过了懒狗"“狗坐在那里,没什么”“其他动物坐在那里观看”];文件= tokenizedDocument (str)
文档= 4x1令牌Document:9令牌:快速的棕色狐狸跳过懒狗8令牌:快速狐狸跳过懒狗7令牌:狗坐在那里,没有什么6令牌:其他动物坐在那里看
创建一系列查询文档。
str = ["一只棕色狐狸跳过了那只懒狗"“另一只狐狸跳过狗”];查询= tokenizeddocument(str)
查询= 2x1令牌地区:8令牌:棕色狐狸跳过懒狗6令牌:另一只狐狸跳过狗
方法计算输入文档和查询文档之间的相似性bm25Similarity功能。输出是稀疏矩阵。得分相似之处(I,J)表示文档(我)和查询(j).
相似之处= BM25SIMILARY(文件,查询);
在热图中可视化文档的相似之处。
图热图(相似之处);Xlabel(“查询文档”) ylabel (“输入文件”) 标题(“BM25相似之处”)

在这种情况下,第一个输入文档最像是第一个查询文档。
使用词汇袋模型的文档相似性
从文本数据中创建一个单词袋式模型Sonnets.csv..
filename =.“sonnets.csv”;tbl = readtable(文件名,'texttype'那'细绳');textdata = tbl.sonnet;文档= tokenizeddocument(textdata);BAG = BAGOFWORDS(文件)
BAG =具有属性的BagofWords:Counts:[154x3527双]词汇表:[1x3527字符串] num字:3527 numfocuments:154
计算十四行诗之间的相似性使用bm25Similarity功能。输出是稀疏矩阵。
相似之处= BM25SIMILARY(袋);
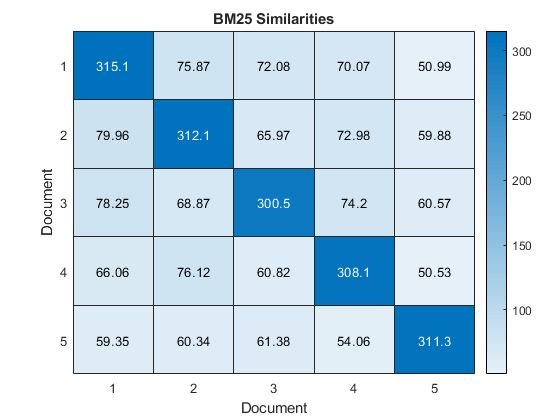
在热图中可视化前五个文档之间的相似性。
图热图(相似之处(1:5,1:5));Xlabel(“文档”) ylabel (“文档”) 标题(“BM25相似之处”)
评估BM25 +文档相似度
BM25+算法解决了BM25算法的一个限制:根据文档长度的术语频率规范化的分量不是适当的下界。由于这种限制,与查询词不匹配的长文档通常会被BM25不公平地评分,因为它们与不包含查询词的短文档具有类似的相关性。
BM25 +通过使用文档长度校正因子(值的值)来解决此限制“DocumentLengthScaling”名称值对)。此因素可防止算法过度惩罚长文档。
创建两个令牌化文档数组。
textdata1 = ["那只敏捷的棕色狐狸跳过了那只懒狗""快狐狸跳过了懒狗"“狗坐在那里,没什么”“其他动物坐在那里观看”];documents1 = tokenizeddocument(textdata1)
译文:那只敏捷的棕色狐狸跳过了那只懒狗。译文:那只敏捷的狐狸跳过了那只懒狗
textdata2 = ["一只棕色狐狸跳过了那只懒狗"“另一只狐狸跳过狗”];documents2 = tokenizeddocument(textdata2)
documents2 = 2x1 tokenizeddocument:8令牌:棕色狐狸跳过懒狗6令牌:另一只狐狸跳过狗
要计算BM25+文件的相似性,使用bm25Similarity函数,并设置'DocumentLengthCorrection'选项为非零值。在本例中,设置'DocumentLengthCorrection'选择1。
相似之处= BM25SIMILARY(Document1,Document2,'DocumentLengthCorrection'1);
在热图中可视化文档的相似之处。
图热图(相似之处);Xlabel(“询问”) ylabel (“文档”) 标题(“BM25 +相似之处”)
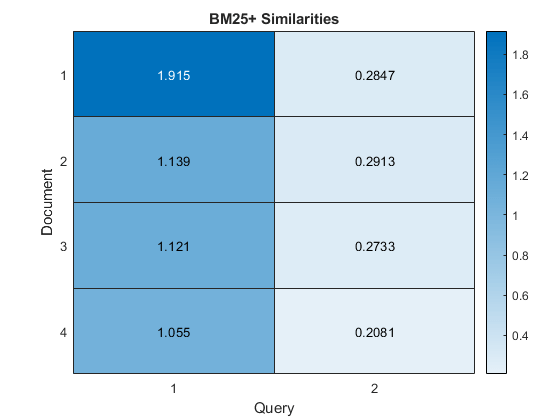
在这里,与示例相比文档之间的相似度,分数显示输入文档和第一个查询文档之间的更多相似性。
输入参数
输出参数
提示
BM25算法通过术语频率(TF)和基于逆文档频率(IDF)选项来聚合并使用来自输入数据中的所有文档的信息。此行为意味着当函数给出不同的文档集合时,相同的文件可以产生不同的BM25相似度分数。
BM25算法在比较文档时可以输出不同的分数。这种行为是由于在BM25算法中使用了IDF权重和文档长度。
算法
参考
[1]罗伯逊,斯蒂芬,雨果萨拉戈萨。《概率关联框架:BM25及其后》信息检索的基础和趋势®3,不。4(2009):333-389。
[2] Barrios, Federico, Federico López, Luis Argerich, Rosa Wachenchauzer。自动文摘中TextRank相似函数的变化。ARXIV预印刷arxiv:1602.03606(2016)。
也可以看看
bleuevaluationscore.|casinediepilarity.|摘录|lexrankscores.|mmrscores.|rougeevaluationscore.|textrankScores|tokenizedDocument
话题
你也可以从以下列表中选择一个网站:
