BM25相似性
文档与BM25算法的相似性
语法
描述
使用BM25相似性计算文档相似性。
缺省情况下,该函数计算BM25的相似度。要计算BM11, BM15,或BM25+的相似性,使用“文档长度缩放”和“DocumentLengthCorrection”参数。
相似之处= bm25Similarity (___,名称,值)“DocumentLengthCorrection”选项为非零值。
例子
文件之间的相似性
创建一个标记化文档数组。
文本数据=[“敏捷的棕色狐狸跳过了懒狗”"快速的棕色狐狸跳过了懒狗"这只懒狗坐在那里什么也不做。“其他动物坐在那里观看”];文件= tokenizedDocument (textData)
译文:这只敏捷的棕色狐狸跳过了那只懒狗。译文:懒狗坐在那里什么也不做,其他的动物坐在那里观看
计算它们之间的相似点BM25相似性函数。输出是一个稀疏矩阵。
相似性=BM25相似性(文件);
在热图中可视化文档的相似之处。
图的热图(相似性);包含(“文档”)伊拉贝尔(“文档”)标题(“BM25相似之处”)
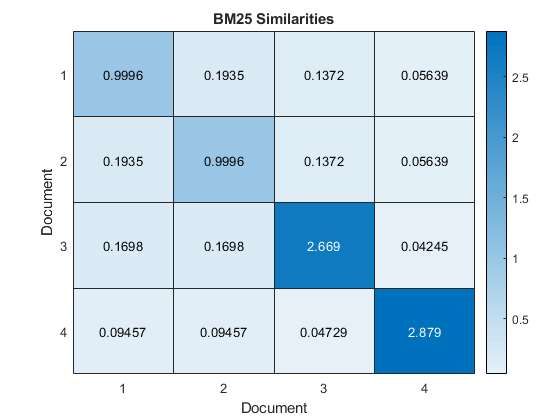
前三个文档具有最高的成对相似性,这表明这些文档是最相似的。最后一个文档与其他文档的两两相似度较低,说明该文档与其他文档的相似度较低。
相似性查询
创建一个输入文档数组。
str=[“敏捷的棕色狐狸跳过了懒狗”“快狐狸跳过了懒狗”"狗坐在那里什么也不做"“其他动物坐在那里观看”]; 文档=标记化文档(str)
这只灵巧的棕色狐狸跳过了那只懒狗。这只灵巧的狐狸跳过了那只懒狗
创建一个查询文档数组。
str=[“一只棕色的狐狸跳过了那只懒狗”"另一只狐狸跳过了那只狗"];查询= tokenizedDocument (str)
8个代币:一只棕色的狐狸跳过了懒狗。6个代币:另一只狐狸跳过了懒狗
使用BM25相似性函数。输出是一个稀疏矩阵。的分数相似性(i, j)表示之间的相似性文件(一)和查询(j).
相似性= bm25Similarity(文档、查询);
在热图中可视化文档的相似之处。
图的热图(相似性);包含(“查询文档”)伊拉贝尔(“输入文件”)标题(“BM25相似之处”)

在本例中,第一个输入文档与第一个查询文档非常相似。
使用词袋模型的文档相似性
从文本数据中创建一个单词袋模型sonnets.csv.
文件名=“十四行诗.csv”;台= readtable(文件名,“TextType”,“字符串”);textData = tbl.Sonnet;文件= tokenizedDocument (textData);袋= bagOfWords(文档)
单词:["From" " fairrest " "creatures" "we"…NumWords: 3527 NumDocuments: 154
使用BM25相似性函数。输出是一个稀疏矩阵。
相似性= bm25Similarity(袋);
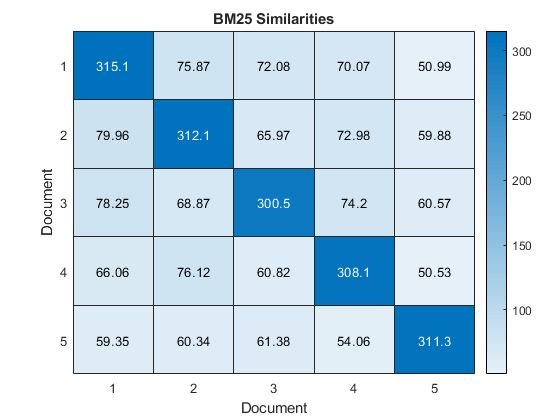
在热图中可视化前五个文档之间的相似之处。
图的热图(相似性(1:5,1:5));包含(“文档”)伊拉贝尔(“文档”)标题(“BM25相似之处”)
评估BM25+文件相似性
BM25+算法解决了BM25算法的一个局限性:根据文档长度进行的术语频率规范化的分量没有适当的下限。由于这个局限性,与查询术语不匹配的长文档通常会被BM25不公平地评分,因为它们与不匹配的较短文档具有相似的相关性在查询术语中输入。
BM25+通过使用文档长度校正因子(值“文档长度缩放”名称-值对)。这个因素可以防止算法过分惩罚长文档。
创建两个标记化文档数组。
textData1 = [“敏捷的棕色狐狸跳过了懒狗”“快狐狸跳过了懒狗”"狗坐在那里什么也不做"“其他动物坐在那里观看”];documents1 = tokenizedDocument (textData1)
文档1=4x1标记文档:9个标记:敏捷的棕色狐狸跳过了懒狗8个标记:敏捷的狐狸跳过了懒狗7个标记:狗坐在那里什么也不做6个标记:其他动物坐在那里观看
textData2 = [“一只棕色的狐狸跳过了那只懒狗”"另一只狐狸跳过了那只狗"];documents2 = tokenizedDocument (textData2)
8个代币:一只棕色的狐狸跳过了那只懒狗。6个代币:另一只狐狸跳过了那只狗
要计算BM25+文档的相似性,请使用BM25相似性函数并设置“DocumentLengthCorrection”选项设置为非零值。在这种情况下,设置“DocumentLengthCorrection”选项1。
相似性= bm25Similarity (documents1 documents2,“DocumentLengthCorrection”,1);
在热图中可视化文档的相似之处。
图的热图(相似性);包含(“查询”)伊拉贝尔(“文档”)标题(“BM25 +相似之处”)
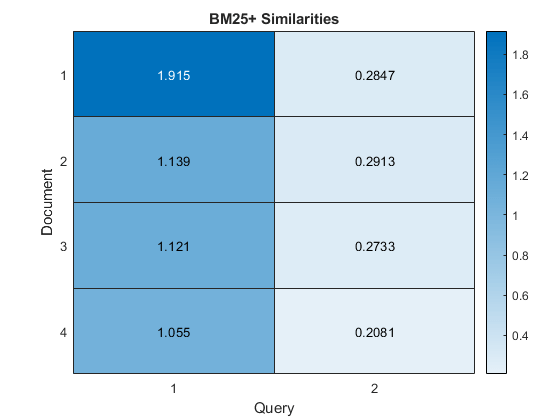
这里,与示例进行比较文件之间的相似性,得分显示输入文档与第一个查询文档之间的相似性更多。
输入参数
输出参数
提示
BM25算法通过基于术语频率(TF)和反向文档频率(IDF)的选项聚合和使用来自输入数据中所有文档的信息。这种行为意味着,当给函数提供不同的文档集合时,同一对文档可以产生不同的BM25相似性分数。
BM25算法在比较文档时可以输出不同的分数。这种行为是由于在BM25算法中使用了IDF权重和文档长度。
算法
参考文献
[1] 《概率相关性框架:BM25及以后》信息检索的基础与趋势3,没有。4(2009): 333 - 389。
[2] 巴里奥斯、费德里科、费德里科·洛佩斯、路易斯·阿格里奇和罗莎·瓦钦乔泽。“用于自动摘要的TextRank相似性函数的变体。”arXiv预印本arXiv: 1602.03606(2016).
另请参阅
标记化文档|bleuEvaluationScore|rougeEvaluationScore|cosineSimilarity|textrankScores|lexrankScores|mmrScores|extractSummary
您还可以从以下列表中选择网站:
