fitlda
拟合潜在狄利克雷分配(LDA)模型
描述
潜在Dirichlet分配(LDA)模型是一种主题模型,它发现文档集合中的底层主题,并推断主题中的单词概率。如果模型适合使用n-g包模型,那么软件将n-g作为单个单词处理。
例子
适合LDA模型
要重现本例中的结果,请设置RNG.到“默认”.
rng (“默认”)
加载示例数据。文件sonnetsPreprocessed.txt包含了经过预处理的莎士比亚十四行诗。该文件每行包含一首十四行诗,单词之间用空格分隔。将文本从sonnetsPreprocessed.txt,将文本拆分为换行符的文档,然后授权文档。
文件名=“sonnetsPreprocessed.txt”;str = inthelfiletext(filename);textdata = split(str,newline);文档= tokenizeddocument(textdata);
创建一个词袋模型使用Bagofwords..
袋= bagOfWords(文档)
BAG =具有属性的BagofWords:计数:[154x3092双]词汇:[1x3092字符串] numwords:3092 numfocuments:154
适合四个主题的LDA模型。
numTopics = 4;numTopics mdl = fitlda(袋)
初始主题分配的采样时间为0.142331秒。===================================================================================== | 迭代每个相对| | |时间培训|主题| | | | | |迭代变化困惑浓度浓度| | | | | |(秒)日志(L) | | |迭代 | =====================================================================================| 0 | 0.41 | 1.000 | 1.215 e + 03 | | 0 | | 1 | 0.02 | 1.0482 e-02 e + 03 | 1.128 | 1.000 | 0 | | 2 | 0.02 | 1.7190 e 03 e + 03 | 1.115 | 1.000 | 0 | | 3 | 0.02 | 4.3796 e-04 e + 03 | 1.118 | 1.000 | 0 | | 4 | 0.01 | 9.4193 e-04 e + 03 | 1.111 | 1.000 | 0 | | 5 | 0.02 | 3.7079 e-04 e + 03 | 1.108 | 1.000 | 0 | | 6 | 0.01 | 9.5777 e-05 e + 03 | 1.107 | 1.000 | 0 |=====================================================================================
mdl = ldaModel with properties: 1 WordConcentration: 1 TopicConcentration: 1 corpustopicprobability: [0.2500 0.2500 0.2500 0.2500 0.2500] documenttopicprobability: [154x4 double] topicwordprobability: [3092x4 double]
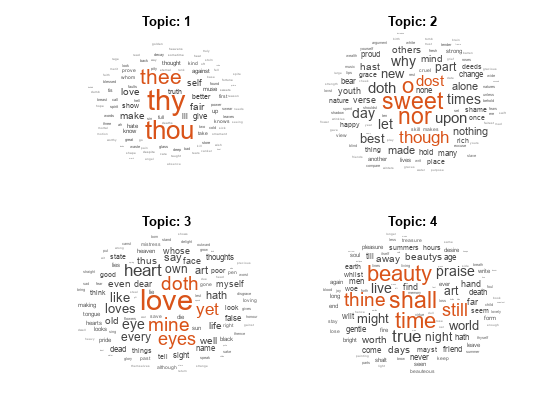
使用词汇云将主题形象化。
数字为topicIdx = 1:4 subplot(2,2,topicIdx) wordcloud(mdl,topicIdx);标题(主题:“+ topicIdx)结束
将LDA模型与字数矩阵进行匹配
将LDA模型适用于由单词计数矩阵表示的文档集合。
要重现此示例的结果,请设置RNG.到“默认”.
rng (“默认”)
加载示例数据。sonnetscounts.mat包含一个单词计数矩阵和相应的词汇预处理版本的莎士比亚十四行诗。的值计数(i, j)对应于次数j词汇表中的单词出现在我文档。
负载sonnetscounts.mat尺寸(计数)
ans =1×2154 3092
拟合7个主题的LDA模型。要抑制verbose输出,请设置“详细”为0。
numtopics = 7;mdl = fitlda(计数,numtopics,“详细”,0);
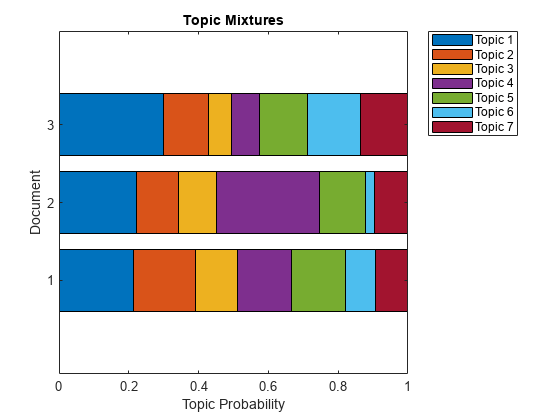
使用堆叠条形图可视化多个主题混合物。可视化前三个输入文档的主题混合。
topicMixtures =变换(mdl计数(1:3,:));图barh (topicMixtures,“堆叠”) xlim([0 1]) title(“主题混合”)xlabel(“主题概率”)ylabel(“文档”) 传奇(“话题 ”+字符串(1:numtopics),'地点',“northeastoutside”)
预测文档的顶级LDA主题
要重现本例中的结果,请设置RNG.到“默认”.
rng (“默认”)
加载示例数据。文件sonnetsPreprocessed.txt包含了经过预处理的莎士比亚十四行诗。该文件每行包含一首十四行诗,单词之间用空格分隔。将文本从sonnetsPreprocessed.txt,将文本拆分为换行符的文档,然后授权文档。
文件名=“sonnetsPreprocessed.txt”;str = inthelfiletext(filename);textdata = split(str,newline);文档= tokenizeddocument(textdata);
创建一个词袋模型使用Bagofwords..
袋= bagOfWords(文档)
BAG =具有属性的BagofWords:计数:[154x3092双]词汇:[1x3092字符串] numwords:3092 numfocuments:154
拟合具有20个主题的LDA模型。
numTopics = 20;numTopics mdl = fitlda(袋)
初始主题任务的采样时间为0.042481秒。===================================================================================== | 迭代每个相对| | |时间培训|主题| | | | | |迭代变化困惑浓度浓度| | | | | |(秒)日志(L) | | |迭代 | =====================================================================================| 0 | 0.01 | 5.000 | 1.159 e + 03 | | 0 | | 1 | 0.03 | 5.4884 e-02 e + 02 | 8.028 | 5.000 | 0 | | 2 | 0.03 | 4.7400 e 03 e + 02 | 7.778 | 5.000 | 0 | | 3 | 0.03 | 3.4597 e 03 e + 02 | 7.602 | 5.000 | 0 | | 4 | 0.03 | 3.4662 e 03 e + 02 | 7.430 | 5.000 | 0 | | 5 | 0.03 | 2.9259 e 03 e + 02 | 7.288 | 5.000 | 0 | | 6 | 0.03 | 6.4180 e-05 e + 02 | 7.291 | 5.000 | 0 |=====================================================================================
mdl = ldaModel with properties: NumTopics: 20 WordConcentration: 1 TopicConcentration: 5 corpustopicprobability: [1x20 double] documenttopicprobability: [154x20 double] documenttopicprobability: [154x20 double] topicwordprobability: [3092x20 double]
预测新文档数组的顶级主题。
newDocuments = tokenizedDocument ([“名字有什么关系呢?”玫瑰不管叫什么名字都一样芳香。”“如果音乐成为爱的食物,就会扮演。”]);newDocuments topicIdx =预测(mdl)
topicidx =.2×119日8
使用词云可视化预测的主题。
图形子图(1,2,1)WordCloud(MDL,TopicIDX(1));标题(“话题 ”+ topicidx(1))子图(1,2,2)WordCloud(MDL,TopicIDX(2));标题(“话题 ”+ TopicIDX(2))

输入参数
输出参数
更多关于
潜在狄利克雷分配
一个潜在狄利克雷分配(LDA)模型是一种文档主题模型,它发现文档集合中的底层主题,并推断主题中的单词概率。LDA对集合进行建模D文档作为主题混合物 ,在K以单词概率向量为特征的主题 .该模型假设主题混合 和主题 服从带有浓度参数的狄利克雷分布 和 分别。
主题混音
概率向量的长度是多少K,在那里K是主题的数量。条目
题目的概率是多少我中出现的d文档。主题混合对应的行DocumentTopicProbabilities.财产的ldaModel目的。
的话题
概率向量的长度是多少V,在那里V是词汇表中的单词数。条目
对应的概率v中出现的单词我主题。的话题
对应于该列的列主题点心财产的ldaModel目的。
考虑到主题 之前和狄利克雷 对于主题混合,LDA假设文档的生成过程如下:
样本一个主题混合物 .随机变量 是长度的概率向量吗K,在那里K是主题的数量。
对于文档中的每个单词:
示例主题索引 .随机变量z是从1到整数吗K,在那里K是主题的数量。
样一个词 .随机变量w是从1到整数吗V,在那里V是词汇表中的单词数,并表示词汇表中的相应单词。
在这个生成过程中,文档与文字的联合分布 ,主题混合物 ,并附有主题索引 是(谁)给的
在哪里N为文档中的字数。求和联合分布z然后对 生成文件的边缘分布w:
下图将LDA模型描述为一个概率图形模型。阴影节点为观测变量,未阴影节点为潜变量,无轮廓节点为模型参数。箭头突出了随机变量之间的相关性,而板块则表示重复的节点。

兼容性考虑因素
参考文献
[1] Foulds, James, Levi Boyles, Christopher DuBois, Padhraic smith, and Max Welling。"潜在狄利克雷分配的随机坍塌变分贝叶斯推断"在第19届美国计算机学会SIGKDD知识发现和数据挖掘国际会议论文集,pp.446-454。ACM,2013。
[2] Hoffman, Matthew D., David M. Blei, Chong Wang和John Paisley。“随机变分推理”。机器学习研究杂志14日,没有。1(2013): 1303 - 1347。
[3]格里菲斯,托马斯L.和Mark Steyvers。“寻找科学主题。”国家科学院的诉讼程序101,没有。4(2004):5228-5235。
Asuncion, Arthur, Max Welling, Padhraic Smyth, and Yee Whye Teh。"关于主题模型的平滑和推理"在第25届人工智能不确定性会议论文集,pp。27-34。奥海新闻,2009年。
Teh, Yee W., David Newman, Max Welling。"潜在狄利克雷分配的失效变分贝叶斯推理算法"在神经信息处理系统的进展, 1353 - 1360页。2007.
你也可以从以下列表中选择一个网站:
