回声消除(AEC)
这个例子展示了如何将自适应滤波器应用于声学回波抵消(AEC)。
作者:Scott C. Douglas
介绍
当需要同步通信(或全双工传输)时,声学回波消除对于音频电话会议是很重要的。在声学回波消除技术中,被测量的传声器信号 包含两个信号:
包含两个信号:
近端语音信号

远端回声语音信号



其目的是从麦克风信号中去除远端回声语音信号,以便只传输近端语音信号。这个例子有一些声音剪辑,所以你现在可能想要调整你的电脑的音量。
房间的冲动反应
首先需要对扬声器所在位置的扬声器到麦克风信号路径的声学进行建模。用一个长有限脉冲响应滤波器来描述房间的特性。下面的代码产生了一个随机的脉冲响应,这与会议室所展示的没什么不同。假设系统采样率为16000hz。
fs = 16000;M = fs/2 + 1;frameSize = 2048;[B,A] = cheby2(4,20,[0.1 0.7]);impulseResponseGenerator = dsp。IIRFilter (“分子”, (0 (1,6) B),...“分母”,);FVT = fvtool (impulseResponseGenerator);%分析过滤器FVT。Color = [1 1 1];

roomImpulseResponse = impulseResponseGenerator (...(日志兰德(1米)+(0.99 * 0.01)。*标志(randn(1米)。* exp (-0.002 * (1: M))) ');roomImpulseResponse = roomImpulseResponse /规范(roomImpulseResponse) * 4;房间= dsp。FIRFilter (“分子”roomImpulseResponse ');无花果=图;情节(0:1 / fs: 0.5, roomImpulseResponse);包含(“时间(s)”);ylabel (“振幅”);标题(“房间脉冲响应”);fig.Color = [1 1 1];

近端语音信号
电话会议系统的用户通常位于系统麦克风附近。下面是男性在麦克风前讲话的声音。
负载nearspeech球员= audioDeviceWriter (“金宝appSupportVariableSizeInput”,真的,...“BufferSize”, 512,“SampleRate”fs);nearSpeechSrc = dsp。SignalSource (“信号”v,“SamplesPerFrame”, frameSize);nearSpeechScope = timescope (“SampleRate”fs,“TimeSpanSource”,“属性”,...“时间间隔”, 35岁,“TimeSpanOverrunAction”,“滚动”,...“YLimits”(-1.5 - 1.5),...“BufferLength”长度(v),...“标题”,近端语音信号的,...“ShowGrid”,真正的);流处理循环而(~结束(nearSpeechSrc))%从输入信号中提取语音样本nearSpeech = nearSpeechSrc ();%将语音样本发送到输出音频设备球员(nearSpeech);%绘制信号nearSpeechScope (nearSpeech);结束释放(nearSpeechScope);

远端语音信号
在电话会议系统中,声音从扬声器传出,在房间里来回跳动,然后被系统的麦克风接收。在没有近端演讲的情况下,通过麦克风听演讲的声音。
负载farspeechfarSpeechSrc = dsp。SignalSource (“信号”, x,“SamplesPerFrame”, frameSize);farSpeechSink = dsp.SignalSink;farSpeechScope = timescope (“SampleRate”fs,“TimeSpanSource”,“属性”,...“时间间隔”, 35岁,“TimeSpanOverrunAction”,“滚动”,...“YLimits”(-0.5 - 0.5),...“BufferLength”长度(x),...“标题”,“远端语音信号”,...“ShowGrid”,真正的);流处理循环而(~结束(farSpeechSrc))%从输入信号中提取语音样本farSpeech = farSpeechSrc ();在远端语音信号中添加房间效果farSpeechEcho =房间(farSpeech);%将语音样本发送到输出音频设备球员(farSpeechEcho);%绘制信号farSpeechScope (farSpeech);记录信号以作进一步处理farSpeechSink (farSpeechEcho);结束释放(farSpeechScope);

麦克风信号
麦克风的信号包含了近端讲话和远端讲话,并在整个房间内回荡。声学回声消除器的目的是抵消远端语音,这样只有近端语音被传输回远端听众。
重置(nearSpeechSrc);farSpeechEchoSrc = dsp。SignalSource (“信号”, farSpeechSink。缓冲区,...“SamplesPerFrame”, frameSize);micSink = dsp.SignalSink;micScope = timescope (“SampleRate”fs,“TimeSpanSource”,“属性”,...“时间间隔”, 35岁,“TimeSpanOverrunAction”,“滚动”,...“YLimits”[1],...“BufferLength”长度(x),...“标题”,“麦克风信号”,...“ShowGrid”,真正的);流处理循环而(~结束(farSpeechEchoSrc))麦克风信号=回声远端+近端+噪声micSignal = farspeech hechosrc () + nearspeech hsrc () +...0.001 * randn (frameSize, 1);%将语音样本发送到输出音频设备球员(micSignal);%绘制信号micScope (micSignal);%记录信号micSink (micSignal);结束释放(micScope);

频域自适应滤波器
本例中的算法是频域自适应滤波器(FDAF).当待辨识系统的脉冲响应较长时,该算法非常有用。FDAF使用一种快速卷积技术来计算输出信号和滤波器更新。该计算在MATLAB®中执行迅速。通过频仓步长归一化,该算法具有较快的收敛性能。为滤波器选择一些初始参数,看看远端语音在错误信号中被抵消的情况如何。
%构造频域自适应滤波器echoCanceller = dsp。FrequencyDomainAdaptiveFilter (“长度”, 2048,...“StepSize”, 0.025,...“InitialPower”, 0.01,...“AveragingFactor”, 0.98,...“方法”,“无约束FDAF”);AECScope1 = timescope(4, fs,...“LayoutDimensions”(4,1),“TimeSpanSource”,“属性”,...“时间间隔”, 35岁,“TimeSpanOverrunAction”,“滚动”,...“BufferLength”长度(x));AECScope1。ActiveDisplay = 1;AECScope1。ShowGrid = true;AECScope1。YLimits = [-1.5 1.5];AECScope1。Title =近端语音信号的;AECScope1。ActiveDisplay = 2;AECScope1。ShowGrid = true;AECScope1。YLimits = [-1.5 1.5];AECScope1。Title =“麦克风信号”;AECScope1。ActiveDisplay = 3;AECScope1。ShowGrid = true;AECScope1。YLimits = [-1.5 1.5];AECScope1。Title ='声回波消除器输出mu=0.025';AECScope1。ActiveDisplay = 4;AECScope1。ShowGrid = true;AECScope1。YLimits = [0 50];AECScope1。YLabel =“ERLE (dB)”;AECScope1。Title ='回波回波损耗增强mu=0.025';近端语音信号释放(nearSpeechSrc);nearSpeechSrc。SamplesPerFrame = frameSize;远端语音信号释放(farSpeechSrc);farSpeechSrc。SamplesPerFrame = frameSize;远端语音信号在房间里回荡释放(farSpeechEchoSrc);farSpeechEchoSrc。SamplesPerFrame = frameSize;
回波损耗增强(ERLE)
因为你可以访问近端和远端语音信号,你可以计算回波损耗增强,它是对回波衰减量(以dB为单位)的平滑度量。从图中可以看出,在收敛期结束时,ERLE达到了大约35 dB。
diffAverager = dsp。FIRFilter (“分子”的(1024));farEchoAverager =克隆(diffAverager);setfilter (FVT diffAverager);micSrc = dsp。SignalSource (“信号”, micSink。缓冲区,...“SamplesPerFrame”, frameSize);%流处理环路自适应滤波步长= 0.025而(~isDone(nearSpeech hsrc)) nearSpeech = nearSpeech hsrc ();farSpeech = farSpeechSrc ();farSpeechEcho = farSpeechEchoSrc ();micSignal = micSrc ();%应用FDAF[y,e] = echoCanceller(farSpeech, micSignal);%将语音样本发送到输出音频设备球员(e);%计算ERLEerle = diffAverager ((e-nearSpeech) ^ 2)。/ farEchoAverager (farSpeechEcho。^ 2);erledB = -10 * log10 (erle);%绘制近端、远端、麦克风、AEC输出和ERLEAECScope1(nearSpeech, micSignal, e, erledB);结束释放(AECScope1);


不同步长值的影响
为了更快地收敛,可以尝试使用更大的步长值。然而,这种增加会导致另一种影响:近端扬声器说话时,自适应滤波器“失调”。听一下当你选择比之前大60%的步长时会发生什么。
%修改FDAF中的步长值重置(echoCanceller);echoCanceller。StepSize = 0.04;AECScope2 =克隆(AECScope1);AECScope2。ActiveDisplay = 3;AECScope2。Title ='声回波消除器输出mu=0.04';AECScope2。ActiveDisplay = 4;AECScope2。Title ='回波回波损耗增强mu=0.04';重置(nearSpeechSrc);重置(farSpeechSrc);重置(farSpeechEchoSrc);重置(micSrc);重置(diffAverager);重置(farEchoAverager);%流处理环路自适应滤波步长= 0.04而(~isDone(nearSpeech hsrc)) nearSpeech = nearSpeech hsrc ();farSpeech = farSpeechSrc ();farSpeechEcho = farSpeechEchoSrc ();micSignal = micSrc ();%应用FDAF[y,e] = echoCanceller(farSpeech, micSignal);%将语音样本发送到输出音频设备球员(e);%计算ERLEerle = diffAverager ((e-nearSpeech) ^ 2)。/ farEchoAverager (farSpeechEcho。^ 2);erledB = -10 * log10 (erle);%绘制近端、远端、麦克风、AEC输出和ERLEAECScope2(nearSpeech, micSignal, e, erledB);结束释放(nearSpeechSrc);释放(farSpeechSrc);释放(farSpeechEchoSrc);释放(micSrc);释放(diffAverager);释放(farEchoAverager);释放(echoCanceller);释放(AECScope2);
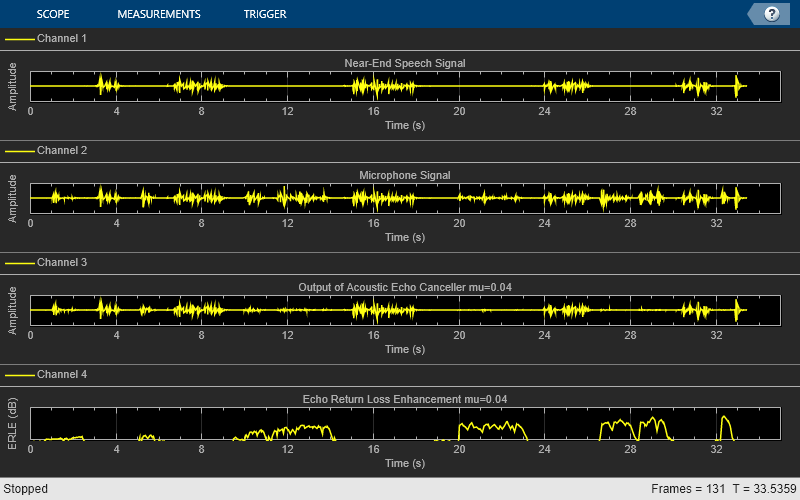
回波损耗增强比较
在步长较大时,由于近端语音引入的误差,ERLE性能不佳。为了解决这一性能难题,声学回波消除器包括一个检测方案,以告诉何时近端语音存在,并降低这些周期的步长值。从ERLE图中可以看出,如果没有这样的检测方案,较大步长时的系统性能不如前者。
使用分区降低延迟
对于长脉冲响应,传统的FDAF在数值上比时域自适应滤波更有效,但它带来了高延迟,因为输入帧的大小必须是指定滤波器长度的倍数。对于许多实际应用程序来说,这是不可接受的。通过使用分区FDAF可以减少延迟,该方法将滤波器脉冲响应划分为更短的段,对每个段应用FDAF,然后合并中间结果。这种情况下的帧大小必须是分区(块)长度的倍数,因此大大减少了长脉冲响应的延迟。
%减少帧大小从2048到256frameSize = 256;nearSpeechSrc。SamplesPerFrame = frameSize;farSpeechSrc。SamplesPerFrame = frameSize;farSpeechEchoSrc。SamplesPerFrame = frameSize;micSrc。SamplesPerFrame = frameSize;%将回声消除器切换到分区约束FDAFechoCanceller。方法=“分区限制FDAF”;%设置块长度为frameSizeechoCanceller。BlockLength = frameSize;流处理循环而(~isDone(nearSpeech hsrc)) nearSpeech = nearSpeech hsrc ();farSpeech = farSpeechSrc ();farSpeechEcho = farSpeechEchoSrc ();micSignal = micSrc ();%应用FDAF[y,e] = echoCanceller(farSpeech, micSignal);%将语音样本发送到输出音频设备球员(e);%计算ERLEerle = diffAverager ((e-nearSpeech) ^ 2)。/ farEchoAverager (farSpeechEcho。^ 2);erledB = -10 * log10 (erle);%绘制近端、远端、麦克风、AEC输出和ERLEAECScope2(nearSpeech, micSignal, e, erledB);结束

你也可以从以下列表中选择一个网站: