このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
predictAndUpdateState
学習済み再帰型ニューラルネットワークを使用した応答の予測およびネットワークの状態の更新
構文
説明
1つのCPUまたは1つのGPUで学習済み深層学習ネットワークを使用して予測を実行できます。GPUを使用するには,并行计算工具箱™および以3.0计算能力上のCUDA®対応英伟达®GPUが必要です。名前と値のペアの引数“ExecutionEnvironment”を使用してハードウェア要件を指定します。
[は,学習済み再帰型ニューラルネットワークupdatedNet,YPred) = predictAndUpdateState (recNet,序列)recNetを使用して序列のデータの応答を予測し,ネットワークの状態を更新します。
この関数は,再帰型ニューラルネットワークのみをサポートしています。入力recNetには少なくとも1つの再帰層を含めなければなりません。
[は,前の構文のいずれかの引数と,1つ以上のペアの引数updatedNet,YPred) = predictAndUpdateState (___,名称,值)名称,值によって指定された追加オプションを使用します。たとえば,“MiniBatchSize”,27はサイズ27のミニバッチを使用して予測を実行します。
ヒント
長さが異なるシーケンスで予測を行うと,ミニバッチのサイズが,入力データに追加されるパディングの量に影響し,異なる予測値が得られることがあります。さまざまな値を使用して,ネットワークに最適なものを確認してください。ミニバッチのサイズとパディングのオプションを指定するには,“MiniBatchSize”および“SequenceLength”オプションをそれぞれ使用します。
例
予測およびネットワークの状態の更新
学習済み再帰型ニューラルネットワークを使用して応答を予測し,ネットワークの状態を更新します。
[1]および[2]で説明されているように日本元音データセットで学習させた事前学習済みの長短期記憶(LSTM)ネットワークJapaneseVowelsNetを読み込みます。このネットワークは,ミニバッチのサイズ27を使用して,シーケンス長で並べ替えられたシーケンスで学習させています。
负载JapaneseVowelsNet
ネットワークアーキテクチャを表示します。
网。层
ans x1 = 5层阵列层:1“sequenceinput”序列输入序列输入12维度2的lstm lstm lstm 100隐藏单位3 fc的完全连接9完全连接层4的softmax softmax softmax 5 classoutput的分类输出crossentropyex ' 1 ', 8其他类
テストデータを読み込みます。
[XTest,欧美]= japaneseVowelsTestData;
シーケンスのタイムステップについてループします。各タイムステップのスコアを予測し,ネットワークの状態を更新します。
X = XTest {94};numTimeSteps =大小(X, 2);为i = 1:numTimeSteps v = X(:,i);(净,分数)= predictAndUpdateState(净,v);分数(:,i) =分数;结束
予測スコアをプロットします。このプロットは,タイムステップ間で予測スコアがどのように変化するかを示します。
一会=字符串(net.Layers(结束). class);Figure lines = plot(scores');传说numTimeSteps xlim ([1]) (“类”+类名,“位置”,“西北”)包含(“时间步”) ylabel (“分数”)标题(“预测分数随时间的变化”)
正しいクラスのタイムステップ全体にわたる予測スコアを強調表示します。
trueLabel =欧美(94)
trueLabel =分类3.
行(trueLabel)。线宽= 3;
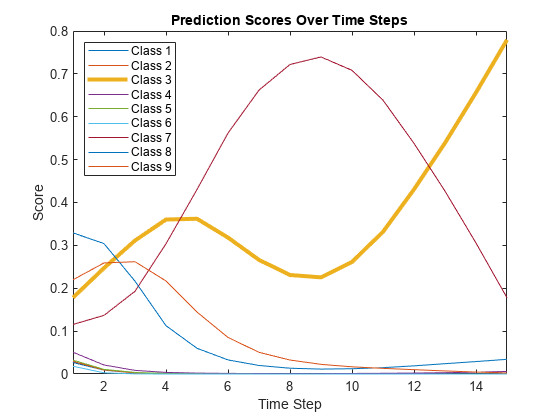
最終タイムステップの予測を棒グラフに表示します。
图酒吧(分数)标题(“最终预测评分”)包含(“类”) ylabel (“分数”)

入力引数
出力引数
アルゴリズム
深度学习工具箱™に含まれる深層学習における学習,予測,検証用のすべての関数は,単精度浮動小数点演算を使用して計算を実行します。深層学習用の関数にはtrainNetwork、预测、分类、激活などがあります。CPUとGPUの両方を使用してネットワークに学習させる場合,単精度演算が使用されます。
参照
工藤、富山、新保。“使用通过区域的多维曲线分类”。模式识别字母。第20卷,第11-13期,第1103-1111页。
[2] UCI机器学习知识库:日语元音数据集。https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
拡張機能
你也可以从以下列表中选择一个网站:
