이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
지수 모델
지수 모델 소개
이 툴박스는 다음과 같이 지정되는 1항 지수 모델과 2항 지수 모델을 제공합니다.
지수는 어떤 수량의 변화율이 그 수량의 초기 크기에 비례하는 경우에 자주 사용됩니다. b 및/또는 d와 연관된 계수가 음수인 경우 y는 지수적 감쇠를 나타냅니다. 계수가 양수이면 y는 지수적 증가를 나타냅니다.
예를 들어, 핵종의 단일 방사성 붕괴 방식은 1항 지수식으로 설명됩니다. a는 핵의 초기 개수로 해석되고, b는 붕괴 상수이고, x는 시간이고, y는 일정한 시간이 흐른 뒤에 남아 있는 핵의 개수입니다. 붕괴 방식이 2개 존재한다면 2항 지수 모델을 사용해야 합니다. 두 번째 붕괴 방식에 대해서는 모델에 또 하나의 지수 항을 추가해야 합니다.
지수적 성장의 예로는 치료법이 없는 전염성 질환의 확산, 포식이나 환경 요인으로 인해 제약을 받지 않는 생물 개체수의 성장 등을 들 수 있습니다.
대화형 방식으로 지수 모델 피팅하기
cftool을 입력하여 곡선 피팅 앱을 엽니다. 또는 앱 탭에서 곡선 피팅을 클릭합니다.곡선 피팅 앱에서 곡선 데이터(X 데이터와Y 데이터또는 인덱스에 대한Y 데이터만)를 선택합니다.
곡선 피팅 앱은 디폴트 곡선 피팅인
다항식을 만듭니다.모델 유형을
다항식에서지수로 변경합니다.

다음 옵션을 지정할 수 있습니다.
exp1또는exp2를 피팅할 하나 또는 두 개의 항을 선택합니다.결과창에서 모델 항, 계수의 값, 적합도 통계량을 확인할 수 있습니다.
(선택 사항)피팅 옵션을 클릭하여 데이터에 적합한 계수 시작값과 제약 조건 경계를 지정하거나 알고리즘 설정을 변경합니다.
이 툴박스는 현재 데이터 세트에 따라 지수 피팅을 위한 최적화된 시작점을 계산합니다. 피팅 옵션 대화 상자에서 사용자가 직접 값을 지정하여 시작점을 재정의할 수 있습니다.
단일 항 지수의 피팅 옵션이 다음에 나와 있습니다. 계수 시작값과 제약 조건은 인구 조사 데이터에 해당하는 것입니다.

데이터에 적합한 시작값을 지정하는 예제는지수적 배경에서의 가우스 피팅항목을참조하십시오。
설정에 대한 자세한 내용은피팅 옵션 및 최적화된 시작점 지정하기항목을참조하십시오。

适合함수를 사용하여 지수 모델 피팅하기
이예제에서는适合함수를 사용하여 지수 모델을 데이터에 피팅하는 방법을 보여줍니다.
지수 라이브러리 모델은适合함수와适合type함수의 입력 인수입니다. 모델 유형을'exp1'또는'exp2'로 지정합니다.
단일 항 지수 모델 피팅하기
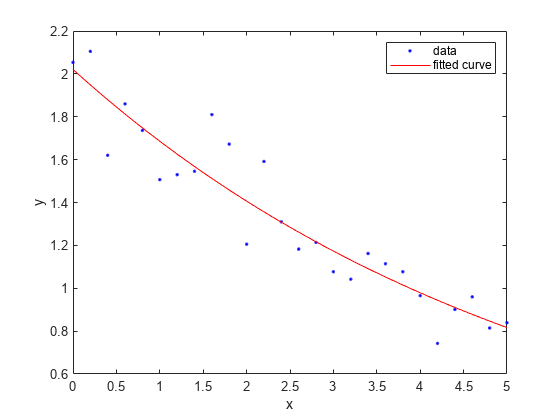
지수적 추세를 갖는 데이터를 생성하고 단일 항 지수를 사용하여 데이터를 피팅합니다. 피팅과 데이터를 플로팅합니다.
x = (0:0.2:5)'; y = 2*exp(-0.2*x) + 0.1*randn(size(x)); f = fit(x,y,'exp1')
f = General model Exp1: f(x) = a*exp(b*x) Coefficients (with 95% confidence bounds): a = 2.021 (1.89, 2.151) b = -0.1812 (-0.2104, -0.152)
plot(f,x,y)
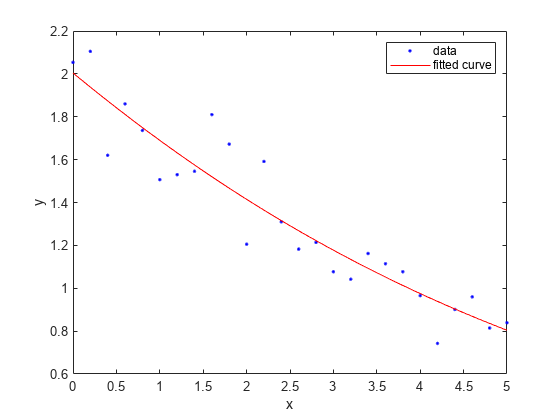
2항 지수 모델 피팅하기
f2 = fit(x,y,'exp2')
f2 = General model Exp2: f2(x) = a*exp(b*x) + c*exp(d*x) Coefficients (with 95% confidence bounds): a = 2443 (-1.229e+12, 1.229e+12) b = -0.2574 (-1.87e+04, 1.87e+04) c = -2441 (-1.229e+12, 1.229e+12) d = -0.2575 (-1.872e+04, 1.872e+04)
plot(f2,x,y)
시작점 설정하기
이 툴박스는 현재 데이터 세트에 따라 지수 피팅을 위한 최적화된 시작점을 계산합니다. 사용자가 직접 값을 지정하여 시작점을 재정의할 수 있습니다.
coeffnames함수를 사용하여 첫 번째 모델(f)의 계수의 순서를 확인합니다.
coeffnames(f)
ans =2x1 cell{'a'} {'b'}
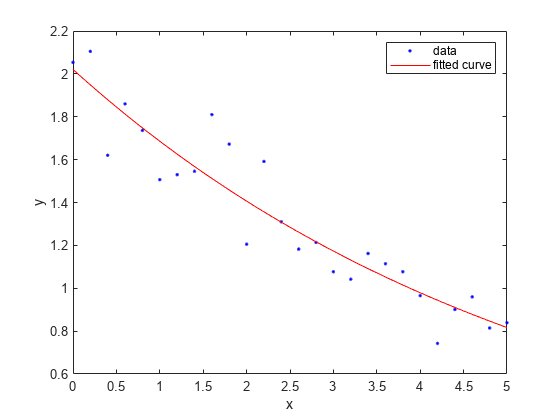
시작점을 지정하는 경우 데이터에 적합한 값을 선택하십시오. 그렇지 않은 경우의 예를 보기 위해 계수a와b에 대해 임의의 시작점을 설정해 보겠습니다.
f = fit(x,y,'exp1','StartPoint',[1,2])
f = General model Exp1: f(x) = a*exp(b*x) Coefficients (with 95% confidence bounds): a = 2.021 (1.89, 2.151) b = -0.1812 (-0.2104, -0.152)
plot(f,x,y)
지수 피팅 옵션 검토하기
데이터에 적합한 계수 시작값과 제약 조건 경계와 같은 피팅 옵션을 수정하거나 알고리즘 설정을 변경하려면 피팅 옵션을 검토하십시오. 이러한 옵션에 대한 자세한 내용은适合options함수 도움말 페이지에서 NonlinearLeastSquares에 대한 속성 표를 참조하십시오.
适合options('exp1')
ans = Normalize: 'off' Exclude: [] Weights: [] Method: 'NonlinearLeastSquares' Robust: 'Off' StartPoint: [1x0 double] Lower: [1x0 double] Upper: [1x0 double] Algorithm: 'Trust-Region' DiffMinChange: 1.0000e-08 DiffMaxChange: 0.1000 Display: 'Notify' MaxFunEvals: 600 MaxIter: 400 TolFun: 1.0000e-06 TolX: 1.0000e-06
참고 항목
관련 항목
You can also select a web site from the following list:
Americas
- América Latina(Español)
- Canada(English)
- United States(English)
Europe
- Belgium(English)
- Denmark(English)
- Deutschland(Deutsch)
- España(Español)
- Finland(English)
- France(Français)
- Ireland(English)
- Italia(Italiano)
- Luxembourg(English)
- Netherlands(English)
- Norway(English)
- Österreich(Deutsch)
- Portugal(English)
- Sweden(English)
- Switzerland
- United Kingdom(English)