COX比例危害默认建模概率
这个示例展示了如何使用消费者(零售)信用面板数据来可视化不同级别的已观察到的违约概率。它还展示了如何拟合Cox比例风险(PH)模型,也称为Cox回归,以预测pd。此外,它还展示了如何执行压力测试分析,以及如何建模生命周期的PDs和生命周期的预期信用损失(ECL)值。
一个类似的例子,使用面板数据对消费者信贷违约概率的压力测试,遵循相同的工作流程,但使用Logistic回归而不是Cox pH。两种方法的主要差异是:
模型适合:COX pH模型具有非参数基线危险率,可以比完全参数逻辑模型更紧密地匹配PDS中的图案。
在数据中超出观察到的年龄之外: Cox PH模型,因为它是建立在非参数基线危险率之上,不能推断出在数据集中没有观察到的贷款年龄。logistic模型将贷款的年龄视为一个连续变量,因此,它可以外推来预测数据集中未观察到的年龄的pd。
低概率情况:如果,对于一个特定的年龄,PD很小,并且在数据中没有观察到默认值,Cox PH模型预测PD为零。相反,logistic模型总是给出非零概率。
数据勘探与生存分析工具
从一些数据可视化开始,主要是作为年龄的函数的PDS的可视化,在此数据集中与多年同样相同(yob)。因为COX pH是一种生存分析模型,所以该示例讨论了一些生存分析工具和概念,并使用了经验累积分布功能(ecdf.)的功能,其中一些计算和可视化。
主数据集(数据)包含以下变量:
ID:贷款标识符。ScoreGroup:贷款开始时的信用评分,分为三组:高的风险,中等风险, 和低风险.yob.:在书上的年份。默认:默认指示灯。这是响应变量。一年: 公历年。
还有一个小的数据集(datamacro.)及相应历年的宏观经济数据:
一年: 公历年。GDP.:国内生产总值增长(年内)。市场:市场回报(年度)。
变量yob.,一年,GDP., 和市场在相应的历年年底进行。评分组是贷款开始时原始信用评分的离散化。的值1为默认意味着贷款违约在相应的日历年。
还有第三个数据集(dataMacrostress.)对于宏观经济变量的基线,不利和严重不利的情景。该表用于应力测试分析。
加载模拟数据。
负载RetailCreditPanelData.matdisp(头(数据,10))
ID分数yob默认年份___ ______________ _______ _____ _____ ____ 1低风险1 0 1997 1低风险2 1998 1低风险3 0 1999 1低风险5 0 2001 1低风险6 0 2002 1低风险72003 1 Low Risk 8 0 2004 2中等风险1 0 1997 2中等风险2998
预处理面板数据以将其格式化为预期的一些生存分析工具。
%使用Gransumarary将数据减少到每行一个ID,并跟踪贷款是否违约DataSurvival = Globanummary(数据,“ID”,'和','默认');disp(头(dataSurvival 10))
ID Groupcount sum_default _____________________ 1 8 0 2 8 0 3 8 0 4 6 0 5 7 0 6 7 0 7 8 0 8 6 0 9 7 0 10 8 0
%也可能从yob中观察到岁月,但在这里我们始终知道yob%从数据中的1开始,因此Groupcount等于最终yobdatasurvival.properties.variablenames {2} ='todowserved';datasurvival.properties.variablenames {3} ='默认';%如果没有默认值,这是一个审查的观察datasurvival.censored =〜datasurvival.default;disp(头(dataSurvival 10))
ID yearsobobserved Default Censored __ _____________ _______ ________ 1 8 0真2 8 0真3 8 0真4 6 0真5 7 0真6 7 0真7 8 0真8 6 0真9 7 0真10 8 0真
主要变量是观察每笔贷款的时间(DoadSserved.),这是“书中岁月”的最终值(yob.) 多变的。这是违约年份的年数,或直到观察期结束(八年),或直到贷款从样品中删除,例如,由于预付款。在此数据集中,yob信息与贷款的年龄相同,因为所有贷款都以yob开头1.对于其他数据集,这可能不是这种情况。在交易组合中,yob和年龄可能是不同的,因为在其生命中的第三年购买的贷款将有一个年龄3.,但yob值1.
第二个必需变量是审查变量(审查).在此分析中默认感兴趣的事件。如果观察到贷款,直到默认情况下,我们有关于默认情况的完整信息,因此终身信息是未经审查或完整的。或者,如果在观察期结束时,贷款未违约,则被认为是审查的或不完整的信息。这可能是因为贷款预付,或因为贷款未违约样本八年观察期结束。
将分数组和复古信息添加到数据。整个贷款寿命中,这些变量的值仍然是不变的。发起的分数决定了得分组,始发年度决定复古或队列。
%可以从YOB==1中得到ScoreGroup,因为我们知道在这个数据集中% YOB总是从1开始,并且在data和datassurvival中ID的顺序是相同的datasurvival.scoregroup = data.scoregroup(data.yob == 1);%定义葡萄酒基于贷款开始的年份,我们知道所有贷款%在该数据集中开始于他们生命的第一年dataSurvival。古董= data.Year (data.YOB = = 1);disp(头(dataSurvival 10))
ID YearsObserved默认截尾ScoreGroup老式__ _____________ _______ ________ ___________ _______ 1 8 0真低风险1997 2 8 0真中等风险1997 3 8 0真中等风险1997 4 6 0真中等风险1999 5 7 0真中等风险1998 6 7 0真正的中等风险1998 7 8 0真正的中等风险1997 8 6 0真正的中等风险1999 9 7 0真正的低风险1998 10 8 0真正的低风险1997
最后,比较原始数据集(面板数据格式)和聚合数据集(更传统的生存格式)的行数。
流('原始数据的行数:%d\n'、高度(数据));
行数原始数据:646724
流('行生存数据的数量:%d \ n'高度(dataSurvival));
存活数据的行数:96820
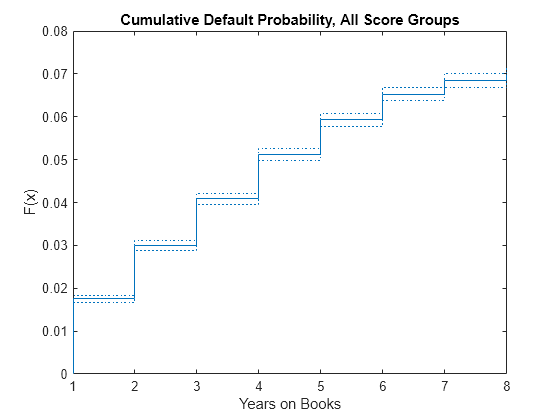
使用经验累积分布函数绘制整个投资组合(所有得分组和年份)针对YOB的累积违约概率(ecdf.)功能。
ecdf (dataSurvival。YearsObserved,'审查',datasurvival.censored,'界限',“上”) 标题(“所有得分组的累计违约概率”)xlabel(“年书”)
情节有条件为期一年的PD对yob。例如,yob的条件一年的PD为3的条件为贷款的条件为期PD,这些贷款在其第三年的生命中。在生存分析中,这被称为离散危险率,表示为h.计算h,获取累积危险功能输出,表示为H,并将其转换为风险函数h.
[h,x] = ecdf(datasurvival.yearsobserved,'审查',datasurvival.censored,...“函数”,'累积危险');因为它是离散时间,只需取H的diff,就得到了风险h =差异(h);x(1)= [];在这个例子中,观察到的时间(存储在变量x中)没有改变%不同的分数组,或训练与测试集。对于其他数据集,在对ECDF功能之前,可能需要检查x和h变量的x和h变量%绘制或连接结果(例如,如果在%特定年份的测试数据)。绘图(x,h,'*') 网格在标题(条件1年期PDs的)ylabel('PD')xlabel(“年书”)

你也可以直接用团体ummary使用原始面板数据格式。有关更多信息,请参见配套示例使用面板数据对消费者信贷违约概率的压力测试.或者您可以使用这些概率来计算grpstats使用原始面板数据格式。这些方法提供相同的一年有条件pd。
PDvsYOBByGroupsummary = groupsummary(数据,“小无赖”,'意思','默认');PDvsYOBByGrpstats = grpstats (data.Default data.YOB);PDvsYOB =表((1:8)、h、PDvsYOBByGroupsummary.mean_Default PDvsYOBByGrpstats,...“VariableNames”,{“小无赖”,“ECDF”,'gransummary','grpstats'});DISP(PDVSYOB)
YOB ECDF Groupsummary Grpstats ____________ ____________ _________ 1 0.017507 0.017507 0.017507 2 0.012704 0.012704 0.012704 3 0.011168 0.011168 0.011168 4 0.010728 0.010728 0.010728 5 0.0085949 0.0085949 0.0085949 6 0.006413 0.006413 0.006413 7 0.0033231 0.0033231 0.0033231 8 0.0016272 0.0016272 0.0016272
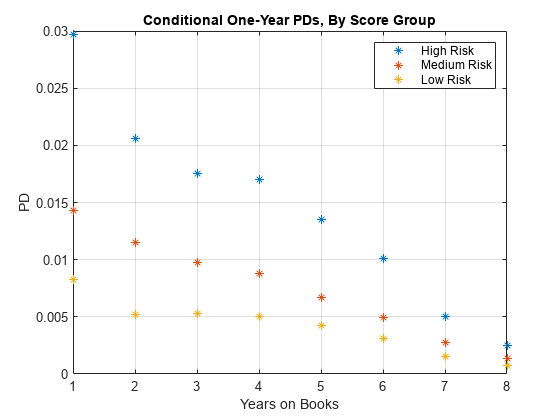
通过分数组分段数据以获取由分数组分列的PDS。
ScoreGroupLabels =类别(dataSurvival.ScoreGroup);NumScoreGroups =长度(ScoreGroupLabels);hSG = 0(长度(h)、NumScoreGroups);为ii=1:NumScoreGroups Ind = dataSurvival.ScoreGroup==ScoreGroupLabels{ii};H = ecdf (dataSurvival.YearsObserved(印第安纳州),'审查'dataSurvival.Censored(印第安纳州));hSG集团(:,(二)= diff (H);结束绘图(x,hsg,'*') 网格在标题(“有条件的1年pd,按分数分组”)xlabel(“年书”)ylabel('PD'传奇(ScoreGroupLabels)
您可以通过葡萄元分解PDS并以类似的方式进行相应的数据。您可以将这些PDS绘制yob或抵制日历年。要查看这些可视化,请参阅使用面板数据对消费者信贷违约概率的压力测试.
无宏观影响的Cox PH模型
本节介绍如何符合无宏信息的COX pH模型。为此,使用生存数据格式,并且该模型仅包括与时间无关的预测因子,即在贷款的整个寿命中保持不变的信息。只有贷款的发起的得分组被用作时间独立于时间的预测器,但是可以将其他这样的预测器添加到模型中(例如,复古信息)。
Cox比例风险回归是一种半参数方法,用于调整生存率估计,量化预测变量的影响。该方法将解释变量的影响表示为公共基线危险函数的乘数, .危险功能是Cox比例危险的非参数部分回归函数,而预测器变量的影响是一种记录回归。该Cox pH模型是
地点:
是预测的变量我对象。
系数是jth predictor变量。
危险率是多少t为 .
是基线危险率函数。
有关详细信息,请参见Coxphfit.或者Cox比例危险模型以及其中的参考文献。
基本的Cox PH模型假设预测值在贷款的整个生命周期中不发生变化。在我们的示例中,这是评分组的情况,因为它是在贷款开始时给予借款人的评分。在贷款的整个生命周期中,年份也是恒定的。
例如,如果每年更新信用评分信息,则可以使用时间依赖的分数。在这种情况下,您在COX pH模型中建模时间相关的预测器,类似于宏变量稍后在“COX pH模型与宏观效果”部分中的模型中添加到模型的方式。
为了评估模型的拟合,可视化模型的样本内和样本外拟合。首先,将数据分解为训练和测试子集,并利用训练数据拟合模型。
nids =高度(DataSurvival);numtring =地板(0.6 * nids);%使用60%的数据进行培训RNG(“默认”);为了重现性,重置rng状态NumTraining TrainIDInd = randsample (nIDs);TrainDataInd = ismember (dataSurvival.ID TrainIDInd);TestDataInd = ~ TrainDataInd;%分数是分类的,转换为dummyvar的二进制列x = dummyvar(DataSurvival.scoregroup(Traindataind));%删除第一列,以避免线性依赖,也称为“哑变量陷阱”。X (: 1) = [];%适合Cox pH模型[bCox ~, HCox] = coxphfit (X,...datasurvival.yearsobserved(Traindataind),...'审查'dataSurvival.Censored (TrainDataInd),...“基线”,0);
的第三个输出Coxphfit.功能是基线累积危险率H.这个累积危险率可以转换为危险率h和以前一样,除了一个额外的步骤。Cox PH模型假设观测时间是作为一个连续变量来测量的。在这里,时间是以离散的方式测量的,因为时间之间总是一个整数1和8.这Coxphfit.功能支持在时间变量金宝app中处理关系的方法(参见'ties'可选输入Coxphfit.).因为关系,所以H输出具有具有相同YOB值的多行,但是可以将其处理为只有惟一的YOB值那么多行,如下所示。
%进程基线HCOX考虑离散时间(删除时间线)HCoxDiscreteT =独特(HCox (: 1));HCoxDiscreteH = grpstats (HCox (:, 2), HCox (: 1),'最大限度');HCox = [hcoxdiscrete tet HCoxDiscreteH];%将基线转换为hxCox = HCox (: 1);hCox = diff ([0; hCox (:, 2)));
预测PDS,即基于模型适合的危险率。因为此模型仅使用在贷款的整个寿命中保持不变的初始分数组信息。所有具有相同初始分数组的贷款都具有相同的预测寿命PD。要获取投资组合的聚合预测PD,请计算每个分数组的危险率。然后根据训练数据中每个刻痕组中的贷款比例进行这些分数组的加权平均值。
将预测的PD与训练数据中观察到的PD进行比较。
%计算每个分数组的贷款比例ScoreGroupFraction = countcats (dataSurvival.ScoreGroup (TrainDataInd));ScoreGroupFraction = ScoreGroupFraction /笔(ScoreGroupFraction);%基线H是“高风险”的危险率,在第一列中%第2列和第3列分别有“中等”和“低”风险,由其COX模型的相应参数项调整的%hPredictedByScore = 0(长度(hCox), NumScoreGroups);hPredictedByScore (: 1) = hCox;为II = 2:NumScoreGroups HPRedItegRegrous(:,ii)= hcox * exp(bcox(ii-1));结束hPredicted = hPredictedByScore * ScoreGroupFraction;%获取培训数据的ecdfHTrain = ecdf (dataSurvival.YearsObserved (TrainDataInd),...'审查'dataSurvival.Censored (TrainDataInd),...“函数”,'累积危险');htrain = diff(htrain);情节(x, hPredicted,“o”,x,htrain,'*')xlabel(“年书”)ylabel('PD')传说('模型',“培训”) 标题(“模型拟合(训练数据)”) 网格在

比较预测的与观察到的测试数据中的PD。
分数重量= countcats(Datasurvival.scoregroup(testdataind));ScoreGroupFraction = ScoreGroupFraction /笔(ScoreGroupFraction);hPredicted = hPredictedByScore * ScoreGroupFraction;%获取培训数据的ecdfhtest = ecdf(datasurvival.yearsobserved(testdataind),...'审查'dataSurvival.Censored (TestDataInd),...“函数”,'累积危险');ht = diff (ht);情节(x, hPredicted,“o”, x, ht,'*')xlabel(“年书”)ylabel('PD')传说('模型',“测试”) 标题('模型适合(测试数据)') 网格在

Cox PH模型的非参数部分允许它与训练数据模式紧密匹配,即使只使用该模型中的评分组信息。样本外误差(模型与测试数据)也很小。
添加宏信息仍然很重要,因为压力测试和寿命PD投影都需要明确依赖宏信息。
具有宏观影响的Cox PH模型
本节介绍如何适应包括宏观信息的Cox pH模型,具体而言,本产品总额(GDP)增长和股票市场增长。宏变量的值每年更改,因此它们是时间依赖的预测因子。具有时间相关预测器的Cox pH功能的数据输入使用原始面板数据,并添加宏信息,以及每行的时间间隔。
将Cox比例风险模型扩展到考虑时变变量
地点:
的预测变量值我对象和j独立于时间的预测因素。
的预测变量值我对象和k时间依赖的预测器t。
系数是jTH时间独立的预测变量。
系数是k依赖于时间的预测器变量。
危险率是多少t为
是基线危险率函数。
有关详细信息,请参见Coxphfit.或者Cox比例危险模型以及其中的参考文献。
宏变量被视为时间依赖的变量。如果初始得分组等时代的信息,则通过贷款的生命提供基线风险水平,预计宏观条件可能会增加或减少周围的基线水平以及这种变化的风险是合理的如果宏观条件发生变化,将与一年不同。例如,经济增长低的年份应使所有贷款更加危险,独立于他们的初始得分组。
对于时变Cox PH分析,使用原始数据集的扩展作为时变分析的输入。
该工具期望时间间隔的规范,具有相应的预测器值。第一年,时间间隔为0到1,第二年时间间隔从1到2,等等。因此,每行的时间间隔范围是YOB-1 yob。
在贷款的历史记录中,时间无关的变量具有常量值,就像原始数据中的得分组信息一样。无需更改任何无缝的变量的任何内容。
对于时间依赖的变量,值从一个间隔变为下一个间隔。我们将GDP和市场变量添加为时间依赖于时间的预测因子。
这些工具还需要一个审查标志,这是对默认信息的否定。
数据。T我meInterval = [data.YOB-1 data.YOB]; data.GDP = dataMacro.GDP(data.Year-min(data.Year)+1); data.Market = dataMacro.Market(data.Year-min(data.Year)+1); data.Censored = ~data.Default; disp(head(data,10))
ID分数yob默认年份默认年份超时GDP市场审查________________ _______ _____________ ______________ 1低风险1 0 1997 0 1 2.72 7.61真实1低风险2 0 1998 1 2 1999 2 1999 2 1999 2 3 2.86 18.1真1低风险4 0 2000 3 4 2.43 3.19 3.19 3.19真1个低风险5 0 2001 4 5 1.26 -10.51 TRUE 1低风险6 0 2002 5 6 -0.59 -22.95 TRUE 1低风险7 0 2003 6 7 0.63 2.78 TRUE 1低风险8 0 2004 7 8 1.85 9.48真正的2中等风险1 0 1997 0 1 2.72 7.61真正的2中等风险2 0 1998 1 2 3.57 26.24真实
拟合时间相关模型。与以前相同的id属于训练或测试子集,但是索引是不同的,因为数据中的格式不同。
Traindataindtd = ISMember(Data.id,Raperidind);testdataindtd =〜traindataindtd;xtd = dummyvar(data.scoregroup(traindataindtd));XTD(:,1)= [];[bcoxtd,〜,hcoxtd] =...coxphfit ([XTD data.GDP (TrainDataIndTD) data.Market (TrainDataIndTD)],...data.timeinterval(traindataindtd,:),...'审查',data.censored(traindataindtd),...“基线”,0);%过程基线HCoxTD考虑离散时间(消除时间束缚)hcoxtddiscretet =唯一(hcoxtd(:,1));hcoxtddiscreteh = grpstats(hcoxtd(:,2),hcoxtd(:1),'最大限度');HCoxTD = [hcoxtddiscrete tet HCoxTDDiscreteH];%将累积基线转换为hcoxtdxCoxTD = HCoxTD (: 1);hCoxTD = diff ([0; hCoxTD (:, 2)));
要可视化样本拟合,请按行计算预测的PDS行。设置预测器矩阵,如拟合模型的当拟合时,然后施加Cox pH公式。
宏观效果有助于模型匹配观察到的默认率甚至更接近,并且与训练数据的匹配几乎看起来像宏模型的插值。
建立预测器矩阵Xpredict = [Dummyvar(Data.ScoreGroup(TrainDatainDTD)),Data.GDP(TrainDatainDTD),Data.Market(TrainDatainDTD)];XPREDICT(:,1)= [];%在行级别预测hPredictedTD = hCoxTD (data.YOB (TrainDataIndTD)。* exp (XPredict * bCoxTD);%每次点(yob)都采取预测的危险率的平均值HPREDITEDTD = GRPSTATS(HPREDITEDTD,DATA.YOB(TRAINDATAINDTD));plot(x,hprededettd,“o”,x,htrain,'*')xlabel(“年书”)ylabel('PD')传说('模型',“培训”) 标题(“宏观模型拟合(训练数据)”) 网格在

设想样本外匹配。
建立预测器矩阵xpredict = [dummyvar(data.scoregroup(testdataindtd)),data.gdp(testdataindtd),data.market(testdataindtd)];XPREDICT(:,1)= [];%在行级别预测hpredictedtd = hcoxtd(data.yob(testdataindtd))。* exp(xpredict * bcoxtd);%每次点(yob)都采取预测的危险率的平均值HPREDITEDTD = GRPSTATS(HPREDITEDTD,DATA.YOB(TESTDATAINDTD));plot(x,hprededettd,“o”, x, ht,'*')xlabel(“年书”)ylabel('PD')传说('模型',“测试”) 标题('宏模型适合(测试数据)') 网格在

为了在评分组水平上可视化样本内和样本外,在按评分组分割数据后执行相同的操作。
压力测试
本节介绍如何使用COX pH宏模型对PD进行应力测试分析。
假设以下是例如由调节器提供的宏观经济变量的应力场景。
disp (dataMacroStress)
GDP市场_____ ______基线2.27 15.02不利1.31 4.56严重-0.22 -5.64
为每个组和每个宏观方案预测给予yob的PD的危险率。此代码预测每个分数组和每个宏场景的PD。
为了可视化每个宏观场景,取分数组上的平均值,通过YOB将其聚合为单个PD。该图显示了预测的不利和严重不利宏观条件对每个YOB的平均PD的影响。
ScenarioLabels = dataMacroStress.Properties.RowNames;NumScenarios =长度(ScenarioLabels);PDScenarios = 0(长度(x), NumScenarios);为II = 1:NumScoreGroups得分=分数曲调{II};XpredictScore = ISMember(分数曲调(2:结束)',得分);pdscenariosgroup = zeros(长度(x),长度(场景));为jj=1: numscenario Scenario = Scenario label {jj};XPredictST = [XPredictScore dataMacroStress.GDP(Scenario) dataMacroStress.Market(Scenario)];hPredictedST = hCoxTD * exp (XPredictST * bCoxTD);PDScenariosGroup (:, jj) = hPredictedST;结束pdscenario = pdscenario + PDScenariosGroup/NumScoreGroups;结束图;标题栏(x, PDScenarios) (“压力测试,违约概率”)xlabel(“年书”)ylabel('PD')传说(“基线”,'不利','严重') 网格在

终身PD和ECL
本节将展示如何使用Cox PH宏观模型计算生命周期PDs,以及如何计算生命周期预期信贷损失(ECL)。
对于寿命建模,PD模型是相同的,但它被不同地使用。您需要预测的PDS不仅仅是一个时期,而且每年在整个每个特定贷款的整个生命中。这意味着您还需要在贷款的寿命中需要宏观方案。本节设置替代的长期宏观方案,计算每种情况下的寿命PD,以及相应的1年PD,边际PD和生存概率。在每个宏观场景下,每年都会可视化寿命和边缘PD。然后将ECL计算为每个场景和加权平均寿命ECL。
为具体起见,本节研究一笔为期8年的贷款在其第三年开始时的情况,并预测该贷款生命周期中从第3年到第8年的1年期PD。本节还计算贷款剩余期限内的生存概率。生存概率之间的关系 和1年的PDS或危险率 ,有时也叫向前PDs,是:
有关这方面的示例,请参见kaplan meier方法.
寿命PD(LPD)是贷款寿命的累积PD,由求生存概率的补充:
最后,另一个兴趣数量是边缘PD(MPD),这是连续两个时段之间的寿命PD的增加:
因此,边际PD也是连续时期之间存活概率的降低,以及危险率乘以存活概率:
具体说明三种宏观经济情景,一种基线预测,以及两种简单的基线增长值上调20%或下调20%的变化,分别称为“更快增长”和“更慢增长”。本例中的场景以及相应的概率只是用于说明目的的简单场景。使用计量经济学工具箱™或统计学和机器学习工具箱™,可以使用更强大的模型构建更全面的情景集;看到例如建模美国经济(计量经济学工具箱).自动化方法通常可以模拟大量的场景。在实践中,只需要少量的场景。结合定量工具和专家判断,选择这些情景和相应的概率。
CurrentAge = 3;%目前开始贷款三年成熟= 8;贷款在第8年底结束分数=“高风险”;%高风险yoblifetime =(截风:成熟)';numyearsremaining =长度(yoblifetime);tlifetime =(dataMacro.year(END)+1:DataMacro.year(END)+ NUMYEARSREMINATION)';tlifetime0 =(DataMacro.year(END):DataMacro.year(END)+ NUMYEARSREMINATION)';XpredictScore = ISMember(分数(2:结束)',分数组);XPREDICTSCORE = REPMAT(XPREDICTSCORE,NUMYEARSREMAINALE,1);gdppredict = [2.3;2.2;2.1;2.0; 1.9; 1.8]; GDPPredict = [0.8*GDPPredict GDPPredict 1.2*GDPPredict]; MarketPredict = [15; 13; 11; 9; 7; 5]; MarketPredict = [0.8*MarketPredict MarketPredict 1.2*MarketPredict]; ScenLabels = [“增长放缓”“基线”“更快的增长”];NumMacroScen =大小(GDPPredict, 2);%场景概率,用于计算生命周期ECLpscenario = [0.2;0.5;0.3];hpredict =零(大小(gdppredict));为ii = 1:NumMacroScen XPredictLifetime = [XPredictScore GDPPredict(:,ii) MarketPredict(:,ii)];hPredict(:,(二)= hCoxTD (YOBLifetime)。* exp (XPredictLifetime * bCoxTD);结束survivalLifetime =[(1、NumMacroScen);cumprod (1-hPredict)];PDLifetime = 1-survivalLifetime;PDMarginal = diff (PDLifetime);图;subplot(2,1,1) plot(tLifetime0,PDLifetime) xticks(tLifetime0) grid . subplot(2,1,1) plot(tLifetime0,PDLifetime在Xlabel(“年”)ylabel('终身pd') 标题('终身PD通过情景')传奇(场景,'地点',“最佳”)子plot(2,1,2) bar(tLifetime, pd边际)网格在Xlabel(“年”)ylabel('边缘PD') 标题(“边缘PD通过场景”)传奇(方案)

这些终身PD是方案的输入是计算寿命预期信用损失(ECL)的输入之一,这还需要给定默认(LGD)和默认(EAD)曝光的寿命值,以及每个场景以及方案概率.为简单起见,在该示例中,假设恒定的LGD和EAD值,但这些参数可能因场景而变化,并且在使用LGD和EAD模型时的时间段。
终身ECL的计算还需要有效的利率(EIR)进行折扣。在此示例中,折扣因子在时间段结束时计算,但可以使用其他折扣时间,例如,时间段之间的中点(即,折扣前一年的折扣金额为6个月折扣因素;折扣二年金额为1.5年折扣因素,等等)。
通过这些投入,预期的信用损失t的场景年代被定义为:
在哪里t表示时间段,年代表示一个场景,并且 .
对于每个场景,通过在分析中的拳头时间段中添加ECLS来计算终身ECL,从分析中的拳头时间段,到所用的产品的预期寿命T,在这个例子中,这是五年(简单贷款,五年剩下到期):
最后,在所有场景下,计算这些预期信贷损失的加权平均值,以得到单个生命周期的ECL值 为情景概率:
乐金显示器= 0.55;默认值损失EAD = 100;%曝光默认EIR = 0.045;%有效利率DiscTimes = tLifetime-tLifetime0 (1);DiscFactors = 1. / (1 + EIR)。^ DiscTimes;ECL_t_s = (PDMarginal *乐金显示器*含铅)。* DiscFactors;% ECL按年份和场景ECL_S = SUM(ECL_T_S);百分比eCL总计发射极耦合逻辑= ECL_s * PScenario;在所有场景中%ECL加权平均值%安排年度ECL以表格形式显示%附加每个场景的ECL总数和场景概率ECL_Disp = array2table ([ECL_t_s;ECL_s;PScenario ']);ECL_Disp.Properties。VariableNames = strcat (“设想_”,字符串(1:nummacroscen)');ecl_disp.properties.rowname = [strcat(“ECL_”,字符串(tlifetime),“_s”);“ecl_total_s”;“概率_s”];disp (ECL_Disp)
Scenario_1 Scenario_2 Scenario_3 __________ __________ __________ ECL_2005_s 0.94549 0.8921 0.84173 0.71543 ECL_2006_s 0.6789 0.64419 ECL_2007_s 0.53884 0.51412 0.49048 0.40169 ECL_2008_s 0.38527 0.36947 0.20849 ECL_2009_s 0.20098 0.19372 0.12339 ECL_2010_s 0.11952 0.11576 ECL_total_s 2.9333 2.7909 2.6554 0.2 Probability_s 0.5 0.3
流('终身ECL:%g \ n',ECL)
一生发射极耦合逻辑:2.77872
当LGD和EAD不依赖于场景(即使它们随时间而变化)时,可以采用寿命PD曲线的加权平均值来得到一个单一的平均寿命PD曲线。
PDLifetimeWeightedAvg = PDLifetime * PScenario;ECLByWeightedPD =总和(diff *乐金显示器* o (PDLifetimeWeightedAvg)。* DiscFactors);流(“生存期ECL,使用加权生存期PD: %g,由于LGD和EAD不变,结果相同。”,...ECLByWeightedPD)
寿命ECL,使用加权寿命PD:2.77872,同样的结果是恒定的LGD和EAD。
但是,当LGD和EAD值随着方案而更改时,必须首先在方案级别计算ECL值,然后找到ECL值的加权平均值。
结论
此示例显示了如何适合PDS的COX pH模型,如何对PDS进行压力测试,以及如何计算寿命PD和ECL。
一个类似的例子,使用面板数据对消费者信贷违约概率的压力测试,遵循相同的工作流程,但使用Logistic回归而不是Cox回归。可以使用逻辑模型来执行在该示例末尾的寿命PD和ECL的计算,并且对代码进行一些调整。
您可以修改这两个示例中的工作流,以使用其他模型公式。例如,您可以拟合逻辑模型,将年龄视为一个分类(离散时间)变量。在这种情况下,模型pd将更接近于观测到的pd,但将失去模型的外推能力。此外,除了logistic回归,其他广义线性模型(glm)支持金宝appfitglm也可以与代码的次要更改一起使用,例如概率模型或互补日志模型。因为所有这些模型都将贷款和宏观信息的年龄结合在一起,因为它们可用于压力测试和终身PD和ECL分析。
另请参阅
信心量|creditDefaultCopula|getScenarios|portfolioRisk|风险协调|模拟
相关的例子
更多关于
您还可以从以下列表中选择一个网站:
