回归树的Bootstrap聚合(Bagging)使用TreeBagger
Statistics and Machine Learning Toolbox™提供了两个支持回归树引导聚合(bagging)的对金宝app象:TreeBagger由使用TreeBagger和RegressionBaggedEnsemble由使用fitrensemble.看到套袋式和套袋式的比较之间的差异TreeBagger和RegressionBaggedEnsemble.
这个例子展示了使用中的特性进行回归的工作流TreeBagger只有。
使用一个1985年进口汽车的数据库,包含205个观察值、25个预测值和1个响应,这是保险风险评级,或“象征”。前15个变量是数字变量,后10个变量是分类变量。符号索引接受从-3到3的整数值。
加载数据集并将其分解为预测器和响应数组。
负载进口- 85Y = X (: 1);X = X(:, 2:结束);isCategorical =[0(15日1);(大小(X, 2) -15年,1)];%分类变量标志
由于套袋使用随机数据图,其确切结果取决于初始随机种子。要重现本例中的结果,请使用随机流设置。
rng (1945“旋风”)
寻找最佳叶片大小
对于回归,一般规则是设置叶片大小为5,并选择三分之一的输入特征进行随机决策分割。在接下来的步骤中,通过比较不同叶片大小的回归得到的均方误差来验证最佳叶片大小。oobError计算MSE与已生长树木的数量。必须设置OOBPred来“上”以便以后得到超出预期的预测。
[5 10 20 50 100];坳=“rbcmy”;图保存在为i=1:length(leaf) b = TreeBagger(50,X,Y)“方法”,“回归”,...“OOBPrediction”,“上”,...“CategoricalPredictors”,找到(isCategorical = = 1),...“MinLeafSize”、叶(i));情节(oobError (b),坳(我))结束包含(“已长成的树的数量”) ylabel (的均方误差)({传奇“5”“十”“20”“50”“100”},“位置”,“东北”)举行从
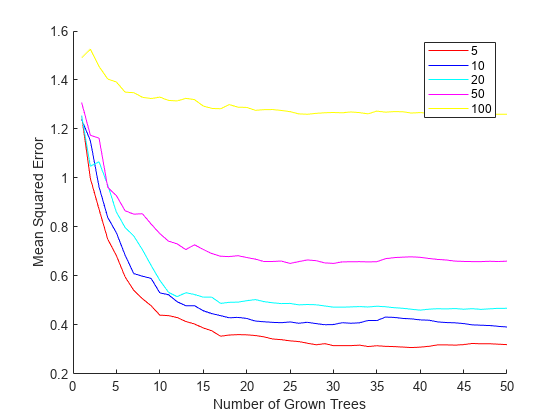
红色曲线(叶片大小5)产生最低的MSE值。
评估功能的重要性
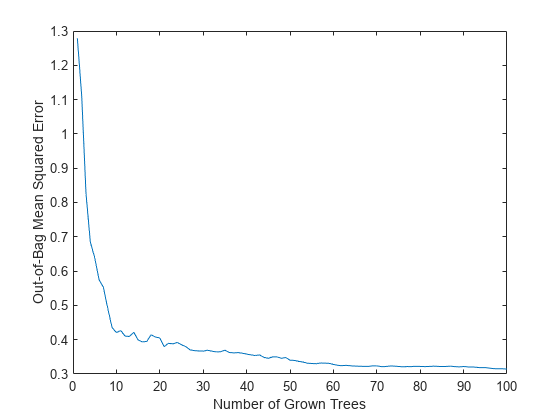
在实际应用中,您通常会种植数百棵树的集合。例如,前面的代码块使用50棵树来加快处理速度。现在你已经估算出了最优的叶子大小,种植一个更大的集合,有100棵树,并使用它来估计特征的重要性。
b = TreeBagger (100 X, Y,“方法”,“回归”,...“OOBPredictorImportance”,“上”,...“CategoricalPredictors”,找到(isCategorical = = 1),...“MinLeafSize”5);
再次检查误差曲线,以确保在训练期间没有任何错误。
图绘制(oobError (b))包含(“已长成的树的数量”) ylabel (“包外均方误差”)
预测能力应该更多地依赖于重要的特征而不是不重要的特征。您可以使用这个想法来衡量特性的重要性。
对于每个特征,在数据集中的每个观测值中排列该特征的值,并测量排列后的MSE变得有多差。您可以对每个特性重复此操作。
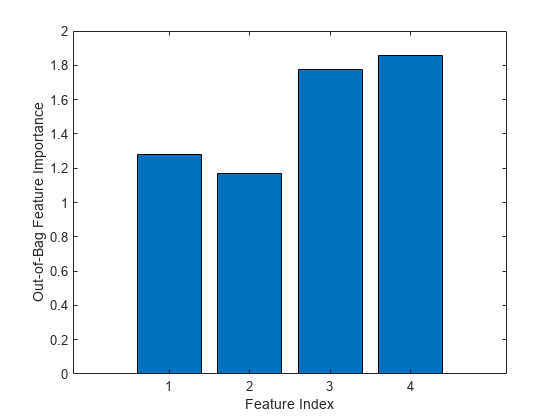
绘制MSE的增加,由于排列在每个输入变量的袋外观察。的OOBPermutedPredictorDeltaError数组存储每个变量的平均MSE增长除以所有树的标准差。这个值越大,这个变量就越重要。施加一个任意的0.7的截止值,您可以选择四个最重要的功能。
图酒吧(b.OOBPermutedPredictorDeltaError)包含(的数字特征) ylabel (“Out-of-Bag特性重要性”)
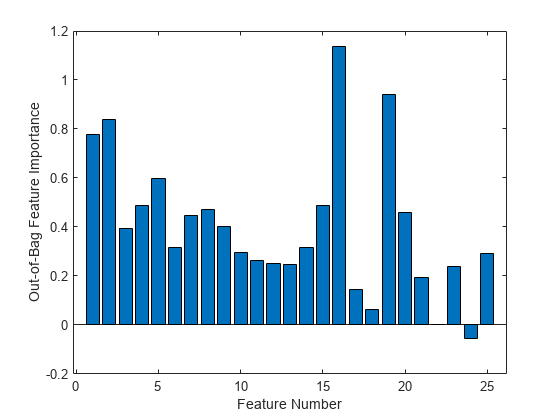
idxvar =找到(b.OOBPermutedPredictorDeltaError > 0.7)
idxvar =1×41 2 16 19
idxCategorical =找到(isCategorical (idxvar) = = 1);
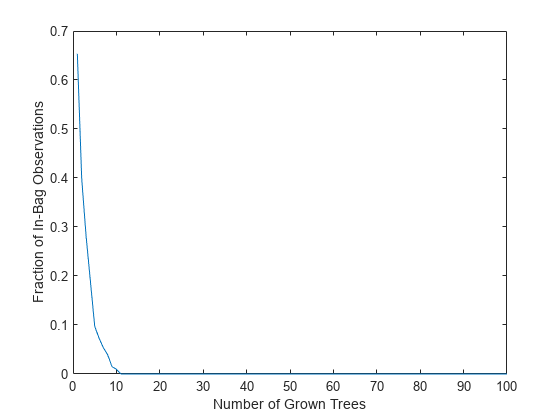
的OOBIndices的属性TreeBagger对哪些树的观测结果是不准确的。使用此属性,您可以监视训练数据中对所有树都适用的观测值。曲线从大约2/3开始,这是一个bootstrap副本选择的唯一观察值的比例,在大约10棵树时下降到0。
b.NTrees finbag = 0 (1);为t = 1: b。NTrees finbag (t) =(所有的总和(~ b.OOBIndices (:, 1: t), 2));结束finbag = finbag /大小(X, 1);图绘制(finbag)包含(“已长成的树的数量”) ylabel (“袋装观察的部分”)
在简化特征集上生长的树木
仅使用四个最强大的特征,确定是否有可能获得类似的预测能力。首先,只在这些特征上种植100棵树。四个选定的特征中的前两个是数字特征,后两个是分类特征。
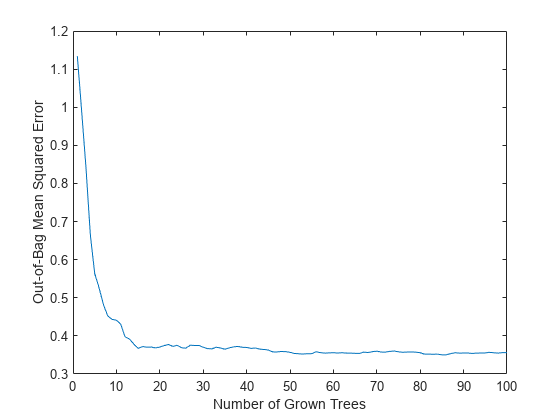
b5v = TreeBagger (100 X (:, idxvar), Y,...“方法”,“回归”,“OOBPredictorImportance”,“上”,...“CategoricalPredictors”idxCategorical,“MinLeafSize”5);图绘制(oobError (b5v))包含(“已长成的树的数量”) ylabel (“包外均方误差”)
图酒吧(b5v.OOBPermutedPredictorDeltaError)包含(“功能指数”) ylabel (“Out-of-Bag特性重要性”)
这四个最强大的特征给出了与完整集合相同的MSE,在简化集合上训练的集合对这些特征的排序相似。如果将特征1和特征2从简化集中移除,那么算法的预测能力可能不会显著下降。
发现异常值
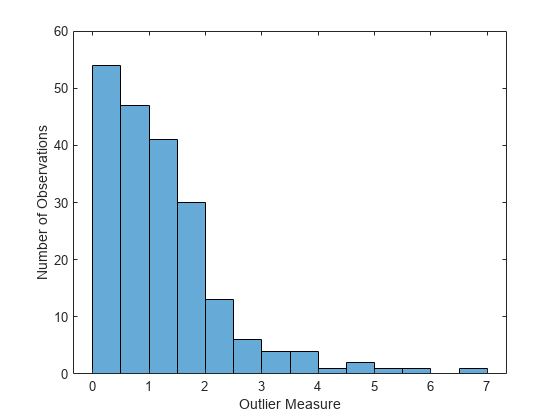
为寻找训练数据中的离群点,使用fillProximities.
b5v = fillProximities (b5v);
该方法通过减去整个样本的均值离群值来规范化这个度量。然后用这个差值的大小除以整个样本的绝对值中位数。
图直方图(b5v.OutlierMeasure)包含(离群值测量的) ylabel (“数量的观察”)
在数据中发现集群
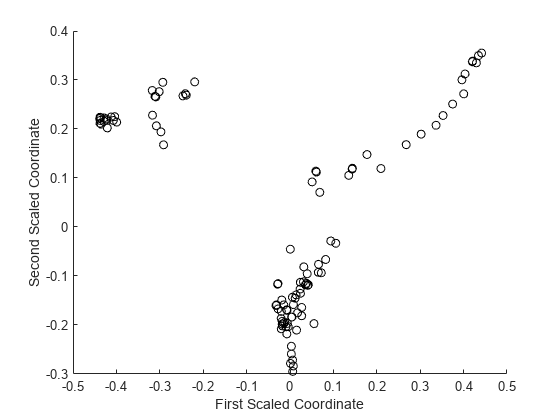
通过对计算的近似矩阵应用多维尺度,您可以检查输入数据的结构,并寻找可能的观察簇。的mdsProx方法返回计算的接近矩阵的比例坐标和特征值。如果你用颜色名称-值对参数,则此方法创建两个缩放坐标的散点图。
图[~,e] = mdsProx(b5v,“颜色”,“K”);包含(“第一比例协调”) ylabel (“第二个比例协调”)
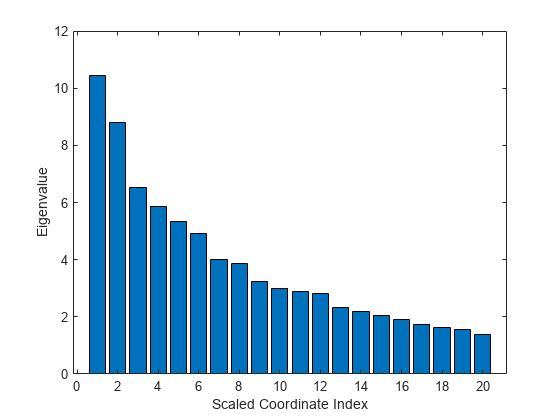
通过绘制前20个特征值来评估缩放轴的相对重要性。
图酒吧(e(1:20))包含(“按比例缩小的协调指数”) ylabel (“特征值”)
保存集成电路配置以供后续使用
要使用经过训练的集成来预测对不可见数据的响应,请将集成存储到磁盘中,然后再检索它。如果不希望计算出包数据的预测或以任何其他方式重用训练数据,则不需要存储集成对象本身。在这种情况下,保存集成的精简版本就足够了。从集合中提取紧致对象。
c =紧凑(b5v)
c = CompactTreeBagger集合与100袋决策树:方法:回归数字预测:4属性,方法
您可以保存结果CompactTreeBagger模型在*.mat文件。
另请参阅
TreeBagger|紧凑的|oobError|mdsprox|fillprox|fitrensemble
相关的话题
你也可以从以下列表中选择一个网站:
