聚类算法
基于密度的噪声应用空间聚类(DBSCAN)
语法
描述
例子
对输入数据执行DBSCAN
使用具有默认欧氏距离度量的DBSCAN对二维圆形数据集进行聚类。同时,比较使用DBSCAN和DBSCAN对数据集进行聚类的结果K-表示用平方欧氏距离度量聚类。
生成包含两个噪声圆的合成数据。
rng(“默认”)%为了再现性%数据生成的参数N = 300;%每个群集的大小r1 = 0.5;第一个圆的半径r2 = 5;%第二个圆的半径θ= linspace(0, 2 *π,N) ';X1 = r1*[cos(theta,sin)]+ rand(N,1);X2 = r2*[cos(),sin()]+ rand(N,1);X = (X1, X2);%嘈杂的二维圆形数据集
可视化数据集。
散射(X (: 1), (2):,)
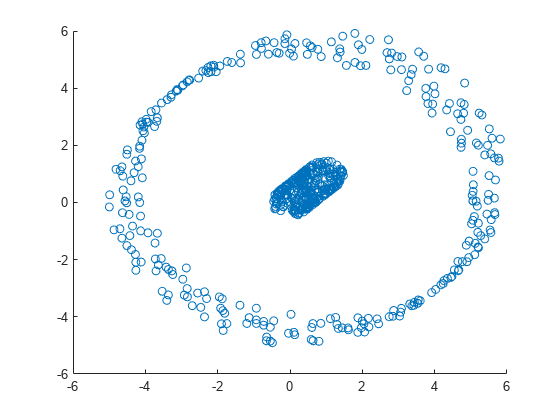
图中显示数据集包含两个不同的集群。
对数据执行DBSCAN群集。指定ε值为1和a明普茨5的价值。
idx = dbscan (X 1 5);%默认距离度量是欧几里德距离
可视化集群。
gscatter (X (: 1) X (:, 2), idx);标题(“使用欧几里得距离度量的DBSCAN”)
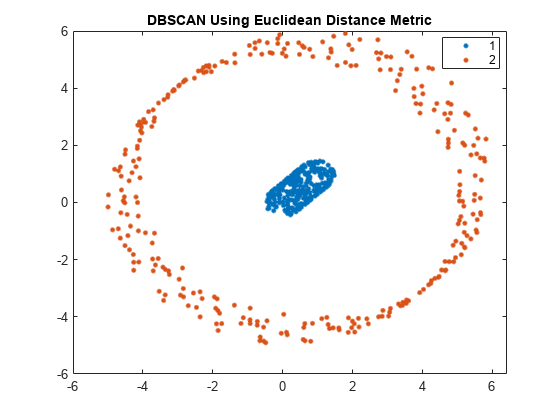
使用欧几里德距离度量,DBSCAN可以正确识别数据集中的两个簇。
使用平方欧氏距离度量进行DBSCAN聚类。指定一个ε值为1和a明普茨5的价值。
idx2 = dbscan (X 1 5“距离”,“squaredeuclidean”);
可视化集群。
gscatter(X(:,1),X(:,2),idx2);标题(“DBSCAN使用平方欧几里德距离度量”)
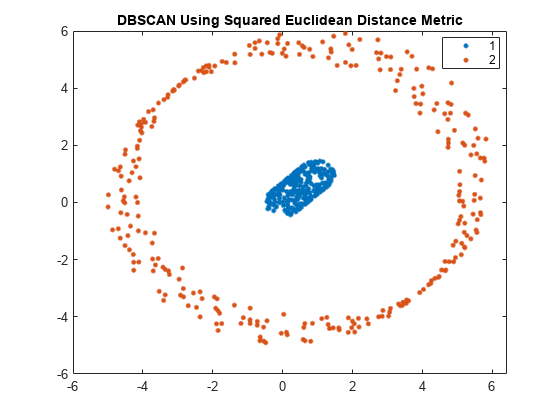
使用平方欧几里德距离度量,DBSCAN可以正确识别数据集中的两个簇。
表演K-表示使用平方欧氏距离度量进行聚类。指定K=2簇。
kidx = kmeans (X, 2);默认距离度量是欧几里得距离的平方
可视化集群。
gscatter (X (: 1) X (:, 2), kidx);标题(“使用平方欧几里德距离度量的K-均值”)
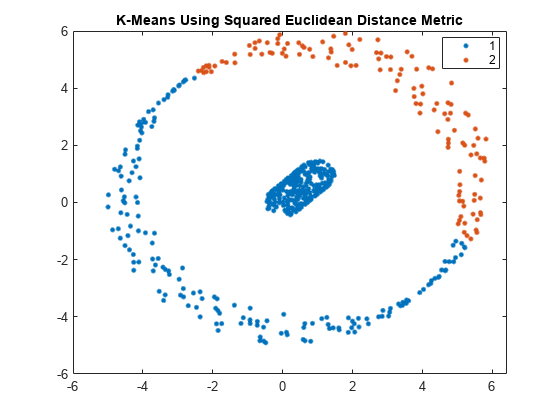
使用平方欧几里德距离度量,K-表示无法正确识别数据集中的两个集群。
在成对距离上执行DBSCAN
使用观测值之间的成对距离矩阵作为数据库的输入,执行DBSCAN聚类聚类算法函数,并查找异常值和核心点的数量。数据集是一个激光雷达扫描,存储为三维点的集合,其中包含车辆周围物体的坐标。
加载x、 y,z物体的坐标。
负载(“lidar_subset.mat”)loc=激光雷达_子集;
要突出显示车辆周围的环境,请将感兴趣的区域设置为车辆左右各20米,车辆前后各20米,以及道路表面上方的区域。
xBound = 20;%在米yBound=20;%在米zLowerBound=0;%在米
裁剪数据以仅包含指定区域内的点。
指数= loc (: 1) < = xBound & loc (: 1) > = -xBound...& loc(:,2) <= yBound & loc(:,2) >= -yBound...& loc(:,3) > zLowerBound;loc = loc(指数:);
将数据可视化为二维散点图。注释该图以突出显示车辆。
散射(loc (: 1), loc (:, 2),'.'); 注释(“椭圆”,[0.48 0.48 .1 .1],“颜色”,“红色”)
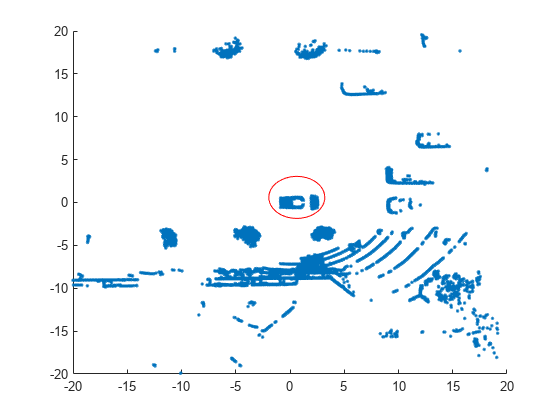
点集的中心(红色圆圈)包含车辆的车顶和发动机罩。所有其他点都是障碍物。
预先计算一个成对距离矩阵D通过使用pdist2作用
D=pdist2(loc,loc);
使用聚类算法成对的距离。指定一个ε2和a的值明普茨价值50。
[idx,corepts]=dbscan(D,2,50,“距离”,“预算”);
可视化结果并注释图形以突出显示特定簇。
gscatter(loc(:,1),loc(:,2),idx);注释(“椭圆”,[0.54 0.41 .07 .07],“颜色”,“红色”网格)
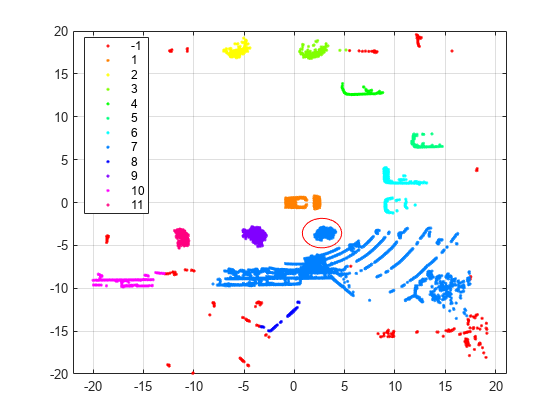
如散点图所示,聚类算法识别11个簇并将车辆放置在单独的簇中。
聚类算法指定以红色圆圈(并以红色圆圈为中心)表示的点组(3、4))到与绘图东南象限中的点组相同的簇(组7)。我们的期望是,这些组应该在单独的集群中。您可以尝试使用较小的值ε将大簇分开,并进一步分割点。
该函数还识别出一些异常值(anidx价值1)在数据中,找到聚类算法识别异常值。
总和(idx = = 1)
ans = 412
聚类算法在19070个观测值中识别出412个异常值。
找出那个点的个数聚类算法确定为核心点。Acorepts价值1.表示核心点。
总和(corepts==1)
ans=18446
聚类算法将18446项观察确定为核心点。
看见确定DBSCAN参数的值举一个更广泛的例子。
输入参数
输出参数
更多关于
提示
如果你使用
pdist2预计算D,不指定“最小的”或“最大”的名称-值对参数pdist2选择或排序的列D.选择少于N距离会导致错误,因为聚类算法预计D成为一个方阵。对每列中的距离进行排序D导致解释上的缺失D并且在使用时,会给出无意义的结果聚类算法作用为了有效地使用内存,请考虑通过
D作为逻辑矩阵而不是数字矩阵聚类算法当D很大。默认情况下,MATLAB®使用8字节(64位)将每个值存储在数字矩阵中,使用1字节(8位)将每个值存储在逻辑矩阵中。选择的值
明普茨,考虑一个大于或等于输入数据的维数加上一个[1]的值。例如,对于anN——- - - - - -P矩阵X设置“明普特”等于P+1或更大。选择值的一种可能的策略
ε就是生成一个K——远程图X.每一点X,求距离K最近的点,并根据这个距离画出已排序的点。通常,图中包含一个膝盖。与膝盖对应的距离通常是一个很好的选择ε,因为它是点开始拖尾到离群(噪声)区域[1]的区域。
算法
DBSCAN是一种基于密度的聚类算法,旨在发现数据中的聚类和噪声。该算法识别出三种点:核心点、边界点和噪声点[1]。的指定值
ε和明普茨这个聚类算法函数实现算法如下:从输入数据集
X,选择第一个未标记的观测值x1.作为当前点,并初始化第一个集群标签C为1。找到epsilon邻域内的点集
ε当前点的。这些点是相邻的。如果邻居数量小于
明普茨,然后将当前点标记为噪声点(或离群值)。请转步骤4。笔记
聚类算法如果噪声点稍后满足由ε和明普茨从另一个角度来看X.这种重新分配点的过程发生在集群的边界点上。否则,将当前点标记为属于集群的核心点C.
迭代每个邻居(新的当前点)并重复步骤2,直到没有发现可以标记为属于当前集群的新邻居C.
在中选择下一个未标记的点
X作为当前点,并将群集计数增加1。重复步骤2-4,直到所有点都到位
X都贴上了标签。
如果两个星团密度不同且彼此接近,即两个边界点(每个星团一个)之间的距离小于
ε然后聚类算法可以将两个集群合并为一个。每个有效的集群可能不包含至少
明普茨观察。例如,聚类算法可以识别属于两个相互靠近的群集的边界点。在这种情况下,算法将边界点分配给第一个发现的群集。因此,第二个群集仍然是有效群集,但其数量可以少于明普茨观察。
工具书类
[1] Ester, M., h . p .克里格尔,J.桑达,肖伟。“一种基于密度的算法,用于在有噪声的大型空间数据库中发现集群。”在第二届数据库知识发现和数据挖掘国际会议论文集,226-231。波特兰,或:AAAI出版社,1996年。
您还可以从以下列表中选择网站:
