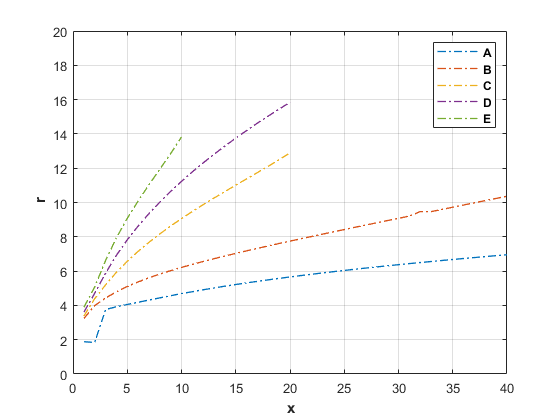
你想适应这些曲线使用一些非线性模型。但是你甚至没有说你想用什么模型,它将允许你将所有曲线的数据在你的家庭选择模型。
它看起来像每个曲线可能通过1 x = = 0。我想如果你考虑一些基本模型,也许:
日志(r = 1 + x + 1)
然后我们可以查看每个曲线re-scaled版本,也许一般家庭:
r (x, a, b) = 1 + *日志(b * x + 1)
每个曲线仍有相同的属性,在x = = 0时,它会有r (0, a, b) = 1。在曲线的家人,我们可以假设任何你想要的日志基础。使用log10如果你感觉更舒适,或自然对数,即便log2,这很好。无论看起来最合适就好。
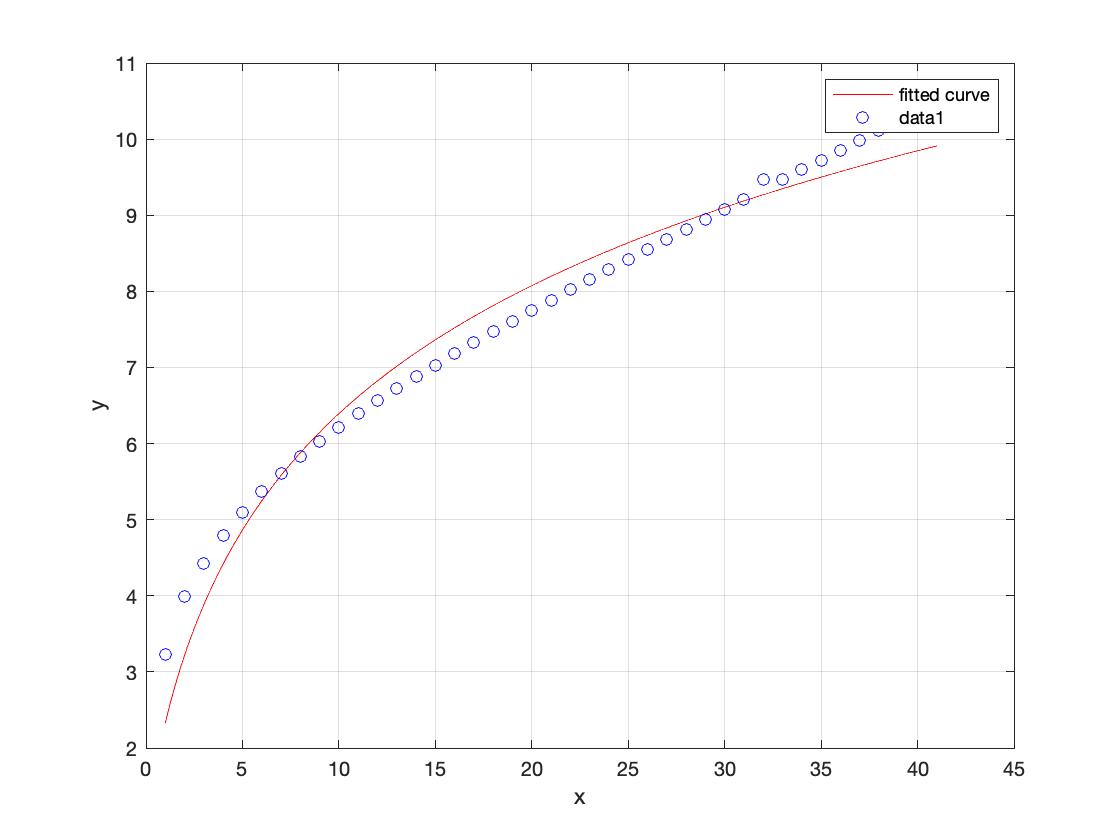
你不提供任何数据,所以很难确定,模型将是合适的,但是它应该显示的一般形状。现在你需要做的是使用工具像曲线拟合工具箱。你也可以使用nlinfit,如果你有统计结核病或lsqcurvefit,如果你有优化结核。恕我直言,CFTB稍微更好的在我看来对于这类问题,因为接口的目的是解决这类问题很自然。CFTB还直接给你参数的不确定性,人们似乎喜欢看到它们。其他TBs甚至远程难以使用。
对于每个曲线,您将执行健康,使用fittype的形式:
英国《金融时报》= fittype (“1 + *日志(b * x + 1)”,“它”,“x”);
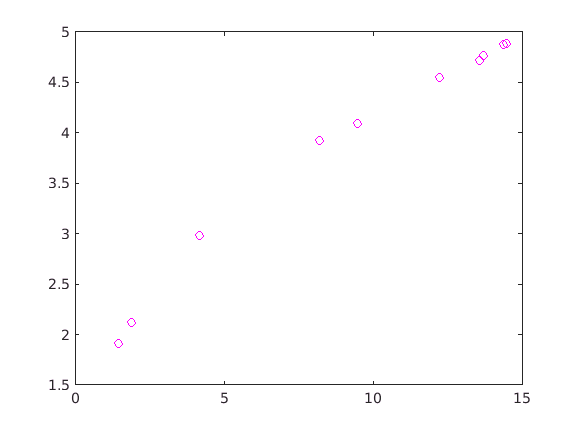
然后您将使用函数适合估计从每个曲线a和b。所以每个曲线a和b的值,特定于该曲线。再次,因为我缺乏你的数据,我不能直接显示这可能是如何工作的。这里是一些敷衍了事,假数据。
x = [1.4631 1.9048 4.1775 8.2032 9.4854 12.221 13.587 - 13.701 14.363 - 14.473);
r = [1.9164 2.1207 2.9809 3.9242 4.0916 4.5444 4.7152 - 4.7689 4.8723 - 4.8862);
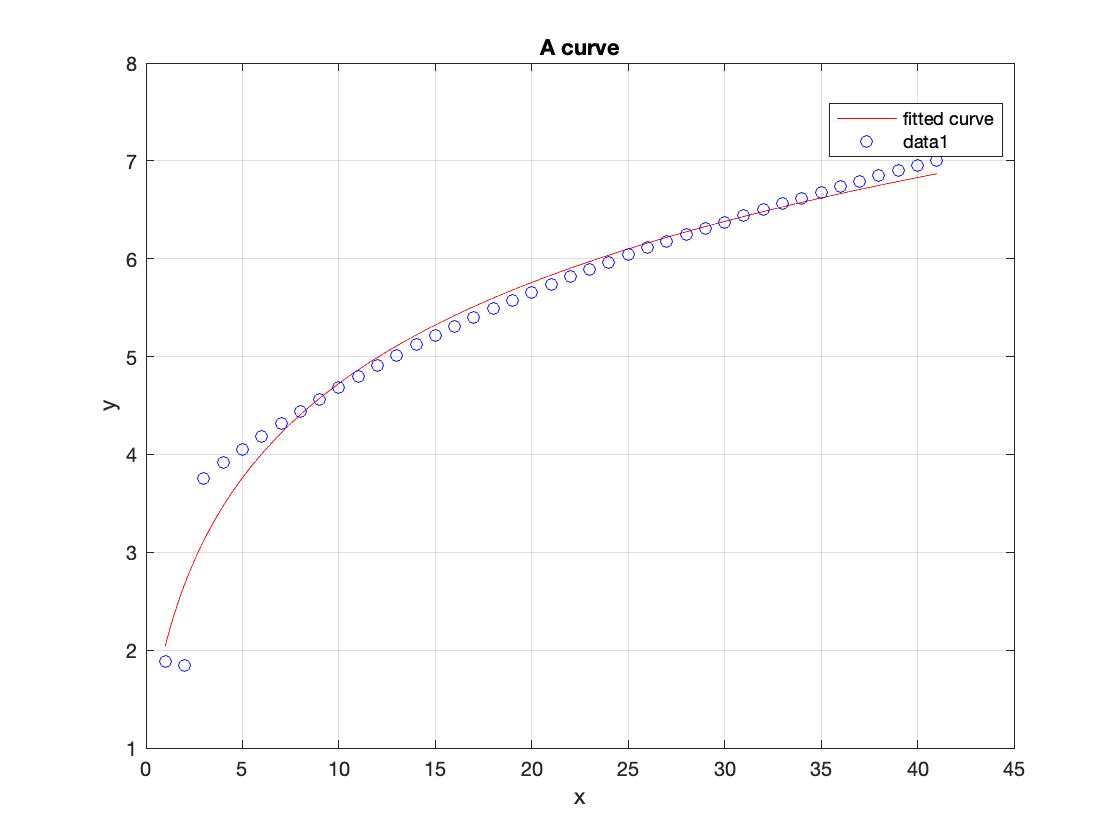
我们会适应数据与健康…
mdl =适合(x ' r ',英国《金融时报》,“开始”[1],“低”,(。001。001])
mdl =
通用模型:mdl (x) = 1 + *日志(b * x + 1)系数(95%置信界限):a = 2.059 (1.947, 2.171) = 0.3803 (0.338, 0.4225)
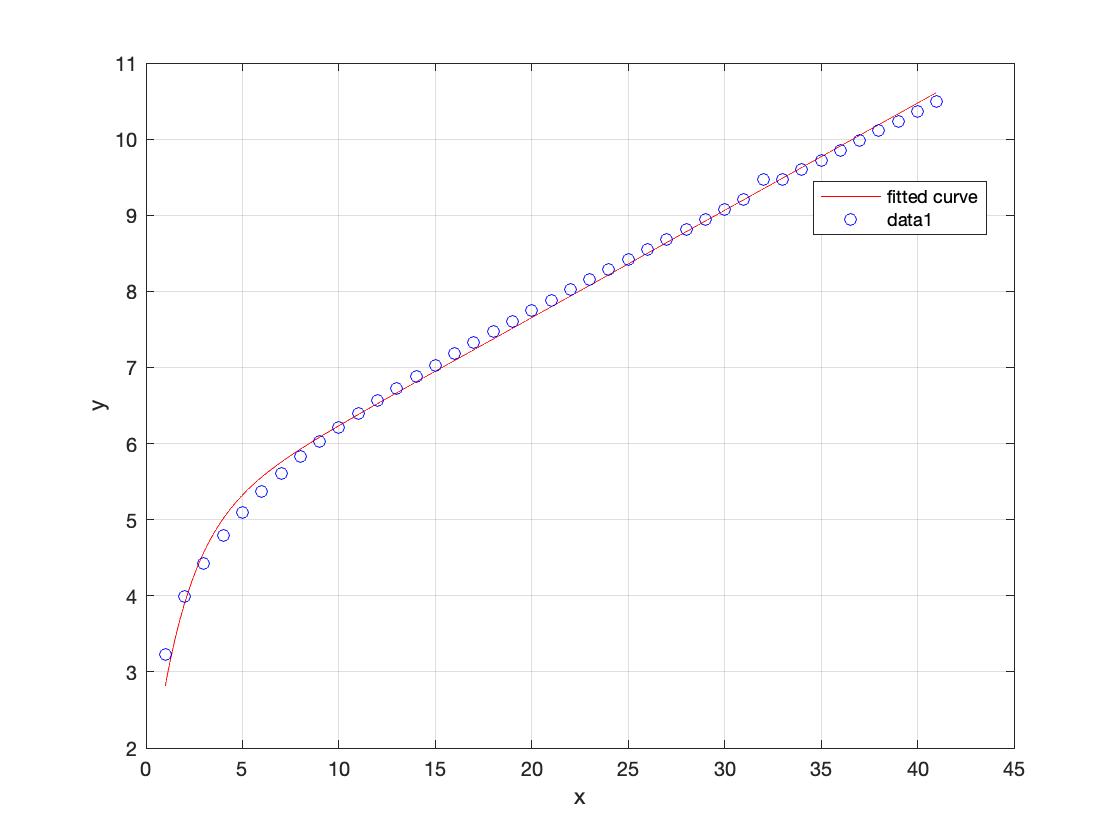
采用自然对数。结果将是参数a和b,这样的曲线可以“校准”以适应主模型。对于这个数据集,大约是2.059,和b大约是0.3803。如果你现在想re-scale数据会覆盖到主曲线,你会这样做:
fplot (@ (x) 1 +日志(x + 1), [0 5))
小红帽= 1 + (r - 1) / mdl.a;
如您所见,现在的数据位于主曲线的顶端。在这种情况下,由于噪音很低,曲线拟合很好。
我可以使用其他工具来做配合,但CFTB这个问题是一个很好的选择。也可能,我选择为你的数据模型并不是最好的一个,但因为我没有你的数据,这纯粹是我胡乱猜想。