cudaconv -使用NVIDIA图形芯片组执行2d卷积。
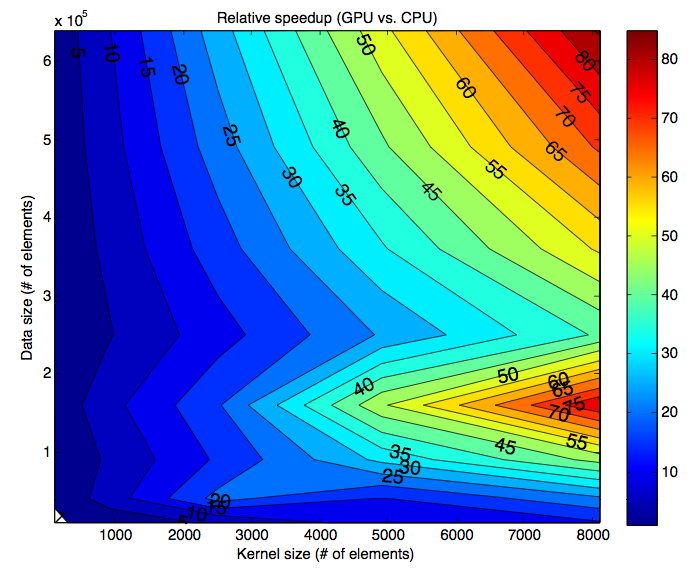
对于大数据集(~ 100万个元素),特别是对于大型内核(性能不会随着内核大小扩展太多),cudaconv的性能可以比conv2高5000%。
我没有创建此算法。它是从CUDA SDK中包含的示例进行调整,并在MATLAB兼容的C代码中包装。
对于非常大的数据矩阵,它可能*完全*崩溃你的计算机(/图形驱动?),所以要小心。在测试中,我发现了卷积大小的上限(受CUDA FFT函数可以接受的大小或2D纹理大小的限制)大约为2^20个元素,因此代码将卷积分解成更小的部分。如果你想冒险,可以提高这个极限,但是要注意,在这些尺寸下,cudaconv已经比conv2快50-100倍了。
引用
Alexander Huth(2021)。快速基于2D gpu的卷积(//www.tatmou.com/matlabcentral/fileexchange/20220-fast-2d-gpu-based-convolution), MATLAB中央文件交换。检索。
意见及评分(13.)
cudaconv /
你也可以从以下列表中选择一个网站:
有人成功地在窗口下编译和运行代码,并得到正确的结果吗?
尝试将'-m 64'添加到nvcc编译行中。
我在MacOS(10.6.7+)上有类似的问题,因为'uname -a'返回i386,但gcc构建x86_64默认。NVCC尝试“自动检测”,但得到了错误的值。
我希望这有帮助。
当我使用下载中包含的.mexmaci文件时,我得到了与Dung Chu相同的结果。
我相信您应该删除该文件,并使用make创建新的文件。(转到终端中的该目录,键入'make')
但是,当我这样做时,我正在获得我不知道如何应对的架构问题:
当编译时,我得到这样的错误:
警告:在Cudaconv.o中,文件是为I386构建的,它不是链接的架构(x86_64)
当使用结果文件时,我得到这个:
c = cudaconv (2, 2)
???无效的mex-file'/ applications/matlab74 / work/cudaconv/cudaconv/cudaconv.maci':dlopen(/pplications/matlab74/work/cudaconv/cudaconv/cudaconv.machmaci,1):没有找到合适的图像。找到:
/应用程序/ MATLAB74 /工作/ cudaconv / cudaconv / cudaconv。梅克斯马西:macho,但是建筑是错误的。
有用。但结果是以某种方式奇怪的。我跑这个
Y =(5);
f = 1/5 *那些(3);
z = Cudaconv(y,f)
z2 = conv2(y,f,'sider')
z =
1.0E-35 *
-0.1319 0.0000 -0.1319 0.0000 -0.1319
0.0000 0 0.0000 00
0 0 0.0000 0 -0.1320
-0.1319 0.0000 -0.1319 0.0000 -0.1941
0000 00 000
z2 =
0.8000 1.2000 1.2000 1.2000 0.8000
1.2000 1.8000 1.8000 1.8000 1.2000
1.2000 1.8000 1.8000 1.8000 1.2000
1.2000 1.8000 1.8000 1.8000 1.2000
0.8000 1.2000 1.2000 1.2000 0.8000
我正在使用matlab2008使用fedora 10。有没有人知道为什么?
亲爱的亚历克斯,我汇编了这个例子如下..
首先,我在cudaconv.cu插入了一些代码
# pragma评论(自由,“C: \ \ CUDA \ \ lib64 \ \ cufft.lib”)
#pragma评论(lib,“c:\\ cuda \\ lib64 \\ cudart.lib”)
接下来,制作一个对象文件
>>系统('c:\ cuda \ bin64 \ nvcc -compile“d:\ cudaconv \ cudaconv \ cudaconv.cu”-ccbin“c:\ dev \ msvs \ vc \ bin”-o cudaconv.o -ic:\ dev \ matlab \ r2009b \ extern \ crincems -ic:\ dev \ msvs \ vc \ include')
Findy,编译并链接它
>> MEX('cudaconv.o')
祝你好运,对不起我贫穷的英语..
DOCU显然不支持Windows。金宝app试图改变MEX文件以获得这项工作。有没有人有任何运气,以便在watchze下工作?
我还没有走出matlab。我如何编译这段代码,以便我可以运行它?
- d
最后函数使用GPU!
对于2D信号的“有效”部分,卷积非常快,非常准确(已知双单精度差异除外),但如果使用“相同”的形状,边缘附近存在大的差异。因此,我写了一块塑造代码来将其视为conv2。请测试并报告任何编码错误!
____________________________________________________
功能[newimage] = cudaconv2(图像,滤波器,形状)
如果nargin == 2
形状='full';
结尾
if(strcmp(stup,'full'))%不是真正的“完全”卷积!!!!!
[im in] = size(image);
[fm fn] = size(filter);
outM1 = 1;
outn1 = 1;
Image2 = 0 (im+fm-1, in+fn-1);
image2(圆(fm / 2):圆形(im + fm / 2 -…1),圆(fn / 2):圆形(+ fn / 2 - 1) =图像(1:1:末端);
输出= Cudaconv(Image2,滤波器);
[outm2,outn2] =尺寸(输出);
elseff(strcmp(shape,'相同'))边缘的差异大差异
输出= Cudaconv(图像,过滤器);
[Am An] = size(image);
outM1 = 1;
outn1 = 1;
OUTM2 = AM;
outN2 =一个;
Elseif (strcmp(shape, 'valid')) %非常准确
输出= Cudaconv(图像,过滤器);
[Am An] = size(image);
[cm rn] =尺寸(过滤器);
outM1 =圆(Cm / 2);
OUTN1 =圆形(RN / 2);
圆(Am - Cm/2);
OUTN2 =圆形(AN - RN / 2);
其他的
DISP('形状无效');
返回;
结尾
newimage =输出(outM1: outM2 outN1: outN2);
____________________________________________________
它在我的GeForce 8400 GPU上正常工作。
要解决零输出问题(请参阅Simon Knight的先前消息),请再次运行NVIDA CUDA Toolkit安装程序,选择自定义安装并检查“CUDakext”。重新启动后,Cudaconv函数应完全运行。
你好,当我运行这个时,我只得到一个0矩阵:
y = rand(64);
>> F = 1/9 *那些(3);
= conv2(y,f, '相同');
= curaconv (y,f);
> >(任何(z1))
ans =
1
>>任何(任何(Z2))
ans =
0.
我正在使用r2007a,并在osx上尝试过。是最新的zip文件,上面提供了更正的头文件吗?
这种东西看起来很有希望,所以我会非常热衷于尝试。
谢谢!
抱歉有一个丢失的头文件-所有应该在更新发布时修复。