数值实现了具有七态的广义SEIR模型[2]。除了依赖于函数“lsq曲率fit”的拟合之外,其他实现都是从头开始的。因此,目前的实现可能不同于引用.[2]中使用的实现。
这个Matlab实现还包括与ref.[2]的一些主要区别。其中死亡率和恢复率的表达式是时间的分析函数和经验函数。这种时间依赖性背后的思想是,随着时间的增加,死亡率和恢复率应该趋近于一个恒定值。如果死亡率保持不变,死亡人数可能被高估。这里没有模拟出生和自然死亡。这意味着,包括死亡病例数量在内的总人口保持不变。请注意,ref.[2]是预印本,没有同行评审,我没有足够的资格来判断论文的质量。
本来文包括:
- SEIQRDP函数。M,用于模拟感染病例、康复病例和死亡病例(以及其他病例)的时间历史。
-函数fit_SEIQRDP。m,估计SEIQRDP中使用的8个参数。最小二乘意义上的M。
—一个示例文件文档。给出了数值实现方法。
—示例文件Example_province_region。mlx,它使用约翰霍普金斯大学收集的关于湖北省(中国)COVID-19流行病[3]的数据。
- example文件Example_Country。mlx,它使用约翰霍普金斯大学收集的关于一个国家的COVID-19流行病的数据[3]。
-一个“意大利区域”文件。mlx”作者:Matteo Secli (https://github.com/matteosecli),我对它进行了修改,使其更加坚固。
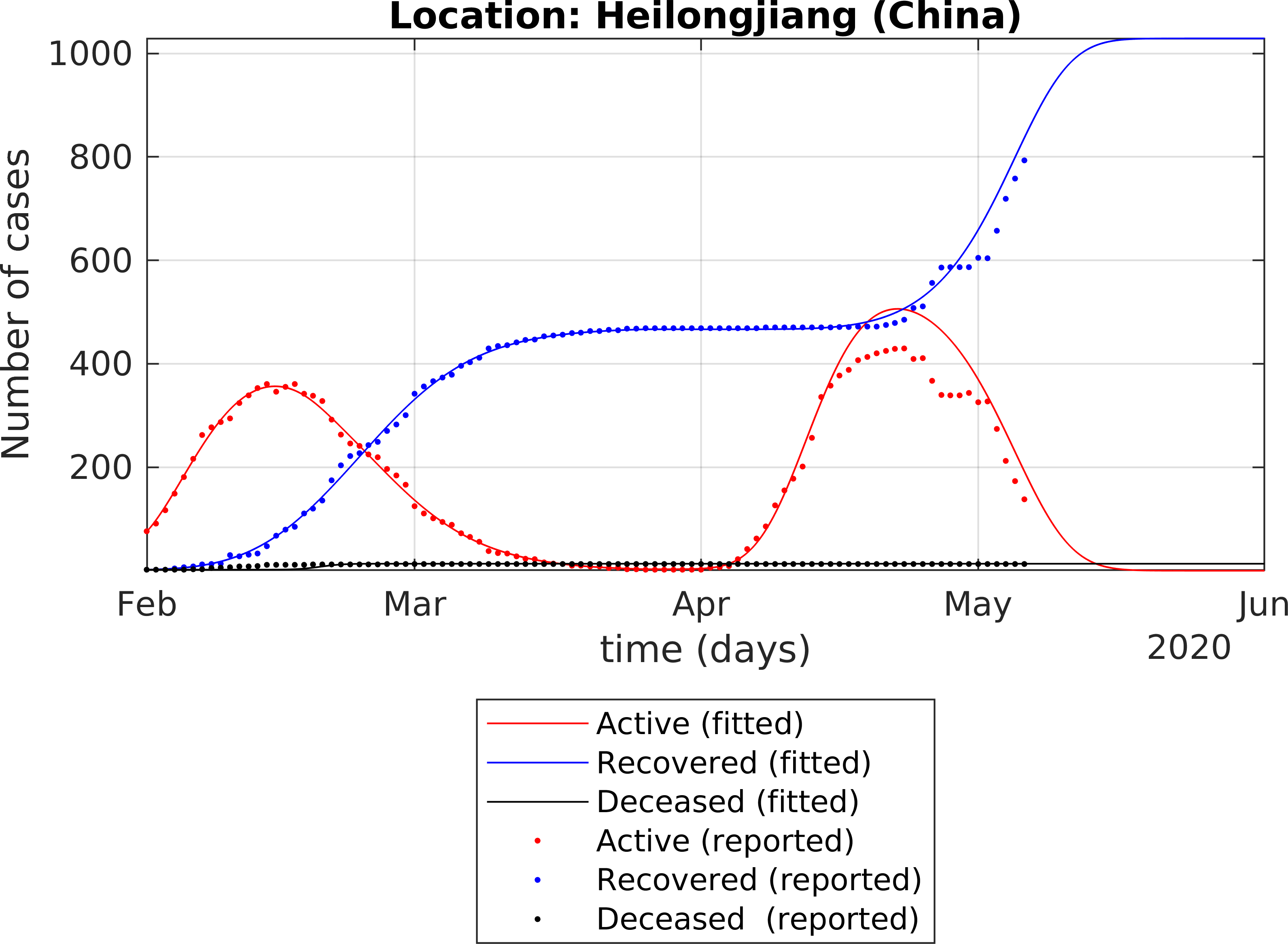
-一个例子文件chinese各省。mlx,它演示了函数fit_SEIQRDP。m用于for循环,用于拟合来自中国不同省份的数据[3]。
-举个例子“unsuretiesissues”。,这说明了拟合有限数据集的危险。
-例如“Example_US_cities.”说明当“恢复”数据不可用时的拟合。
-一个例子simulateMultipleWaves,mlx,说明了对多个流行病波的拟合。
-一个函数getDataCOVID,它从[3]读取约翰霍普金斯大学收集的数据。
一个getDataCOVID_ITA函数https://github.com/matteosecli),该机构从意大利政府收集意大利COVID-19大流行的最新数据[4]
-一个函数getDataCOVID_US,它从[3]收集美国的更新数据
-一个函数checkRates。绘制拟合的和计算的死亡率和回收率(质量检查)的M
-一个函数getMultipleWaves。m,模拟SEIRQDP模型并将其拟合到检测到多个流行病波的情况。
如果您需要导入当前提交中没有包含的数据,您可以在Matlab工作区(https://se.mathworks.com/videos/importing-data-from-text-files-interactively-71076.html)
欢迎提出任何问题、意见或建议。
参考文献
L。[2]Peng,杨,W。,,D,诸葛,C,和香港,L(2020)。基于动态建模的中国新冠肺炎流行病学分析。arXiv预打印:2002.06563。
评论及评分(117)
您也可以从以下列表中选择网站:
嗨Cheynet,
理解。非常感谢!
嗨Felin,
如果最初报告的隔离病例数为零,则E、I和Q的初始值为零,因此模拟在任何时间步将给出“0”。2020年1月,许多国家的活跃病例数为零。我建议不要使用2020年3月之前的数据,除了中国和其他一些国家。
嗨Cheynet,
当我运行example_county以基于拟合参数模拟流行病爆发时,当我使用较长的初始和最终时间(即从2020年1月22日到2021年2月1日),我得到E、I、Q、R、D的值都为零。但当我调整到更小的时间段(即从2021年1月到2021年2月)时,我得到了非零值。这导致了对example_country图中的拟合数据和真实数据部分进行比较,当E、I、Q、R、D(较长时间段的情况)的值都为零时,没有恢复(拟合)、活动(拟合)、死亡(拟合)图,只有恢复(报告)、活动(报告)、死亡(报告)图。我能知道这是什么原因造成的吗?如何使E,I,Q,R,D的值在更长的时间内(即从2020年1月22日到2021年2月1日)非零?
期待您的澄清,非常感谢!
嗨Cheynet,
非常感谢你的回答!!您对我理解这个模型肯定有很大的帮助!再次感谢!!
嗨,阿廖沙,
很抱歉回复晚了。我试着在下面逐点回答:
1 Example_Country文件。MLX包括来自各国的数据,这些数据定期更新。这些数据可以在Github上找到:https://github.com/CSSEGISandData/COVID-19.用作“猜测”的参数是进行最小二乘拟合所必需的初始猜测。这些是由用户给出的初始条件,可以影响参数的拟合值。单位取决于你所观察的参数。他们的单位需要确保方程的齐次性。单位时间为“天”。在文件文档中。Mlx, lambda和kappa将进行更详细的解释。
这些是初始条件。所以它们是“猜测”的值
是的,我用的是1小时的时间步长。因为单位时间是“天”,所以我取1/24天作为时间步长。它主要用于实际目的。我使用的是龙格-库塔算法的一个稍加修改的版本,它依赖于这样一个假设:参数kappa和lambda在两个时间步之间不发生显著变化。如果您使用的时间步长太大,模拟的准确性将下降,甚至可能出现收敛问题。然而,如果您将时间步长增加到12小时,即dt = 1/2甚至dt = 1,即一天,代码应该仍然可以很好地工作,因为kappa和lambda在当前代码中随时间平滑地变化
你可以自由地做出任何你想要的改变。有几种方法可以使模型与数据相匹配。我使用的拟合过程不是最简单的方法,因为我首先拟合lambda和kappa,以限制它们可能值的范围,然后应用具有严格的参数下限和上限的一般拟合。一种更直接(但不一定更好)的方法是首先适合lambda和kappa,并且不再允许它们的值发生变化。然后再进行第二次拟合,以检索剩下的参数。
你好,Cheynet,
我在这之前就解决了这个问题!我还有几个问题,如果你能帮我澄清我的疑惑,我将非常感激。
1.在Example_Country文件下。mlx和“将广义SEIR模型拟合到真实数据”部分,有一部分我必须输入alpha_guess, beta_guess等。这些数字是从我要分析的国家的数据中得来的,还是只是有根据的猜测?此外,这些参数的单位是什么?例如每天/每星期/每千人等。
2.在同一部分下,有'lambda_guess = [0.01,0.001,10];%回收率'和'kappa_guess = [0.001,0.001,10];%死亡率'。我能知道这些值是什么意思和你是如何获得它们的吗?
3.在“基于拟合参数模拟流行病爆发”一节中,您使用了1/24的时间步长。
Dt = 1/24;%时间步长我可以知道你如何选择这个值和它如何影响输出吗?
4.我必须在函数fit_SEIQRDP, SEIQRDP和checkRates的值中做任何更改吗?我使用的是你分享的github链接中确诊病例、死亡病例和康复病例的全球时间序列数据。我下载了csv文件并导入了它们,而不是直接从源代码获取。那将是我所做的唯一的改变。我是否需要修改我所分析的每个国家的参数?
我在理解代码方面有一些困难,因为我还是一个初学者,非常感谢您的帮助!!
好的,非常感谢你的帮助Cheynet!
嗨,阿廖沙,
您看到的消息来自于indR为空的事实。换句话说,这意味着您修改的getDataCOVID函数无法正确读取excel文件。我不知道你是怎么修改这个文件的,所以我不能提供更多的帮助。另一种方法是在工作空间中手动导入excel文件,让Matlab创建一个函数来读取excel文件并重用该函数(在稍加修改后)。
嗨Cheynet,
我试图改变函数'getDataCOVID.m '中的代码。我没有使用Github存储库中的数据,而是下载了数据,并将它们分离到excel文件中。我导入了数据并修改了如下代码。然后在Example_Country文件中运行这个函数。然后,错误“索引超过数组元素的数量”为下面的行弹出
indR = indR(1);
我怎么解决这个问题?
%%导入数据
Ndays = floor(now)-datenum(2020,01,22)-1;%减去一天,因为数据更新有24小时的延迟
opts = delimitedTextImportOptions("NumVariables", Ndays+5);
选择。VariableNames = ["ProvinceState", "CountryRegion", "Lat", "Long", repmat("data",1,Ndays+1)];
选择。VariableTypes = ["string", "string", repmat("double",1,Ndays+3)];
指定文件级别属性
选择。ExtraColumnsRule = "ignore";
选择。EmptyLineRule = "read";
状态={'确认'、'死亡'、'恢复'};
2 = 1:元素个数(状态)
{二}如果strcmpi(地位,“确认”)
tableConfirmed =readtable('data_confirmed.xlsx', opts);
{2} elseif strcmpi(地位,“死亡”)
tableDeaths =readtable('data_deaths.xlsx', opts);
{二}elseif strcmpi(地位,“恢复”)
tableRecovered =readtable('data_recovered.xlsx', opts);
其他的
错误(“不明身份”)
结束
结束
time = datetime(2020,01,22):days(1):datetime(datestr(floor(now)), 'Locale', 'en_US')-datenum(1);
嗨Cheynet,
谢谢你!我已经安装了最新版本的MATLAB R2020b,代码现在工作正常。
嗨,Md Nasseef,
我认为错误来自于这样一个事实,你至少需要Matlab R2018使用可选参数“opts = delimitedTextImportOptions”。你可以在用户的评论中看到克服这个问题的可能解决方案(见2020年4月18日左右的评论)
你好Cheynet,
我正在获得一个错误运行getDataCOVID(错误在getDataCOVID(第14行)opts = delimitedTextImportOptions("NumVariables", Ndays+5));我使用的是MATLAB R2017b。你能指导我解决这个问题吗?谢谢你!
代码被更新了,但是在数据库更改后有几个小错误需要更正。通常情况下,示例现在应该可以正常工作了。
嗨Fayeza,
感谢您的反馈!我打算更新代码,使用户更容易选择拟合的开始和结束时间。这应该在一周内完成
嗨Cheynetl,
我知道报告的数据是从1月22日开始的,但是代码是从6月开始工作的。我们可以修改一下代码,比如从8月开始吗?
嗨,布鲁诺,
向量[a,b,c,…]]对每个参数的不同猜测进行分组。这是对不同猜测值进行分组的一种紧凑方法。下限和上限是在函数fit_SEIQRDP内部设置的,因此用户不需要指定它们。
总共有10个参数,所以拟合不是通过试图同时找到10个最佳值来完成的(至少不是直接地)。首先对病死率(3个参数)和恢复率(3个参数)进行拟合。参数的估计使用个别的测量率。这个拟合给出了参数kappa和lambda的狭窄上下限边界。在第一步之后,十个参数中的六个几乎是固定的。
嗨Cheynet,
谢谢你的回答。你澄清了我的部分疑虑。如果我没有搞清楚我的问题:当我定义向量[a, b, c]时,这意味着什么?例如:'a'是一个下限,'c'是一个上限,'b'是一个比率?还是时间序列由[下限,中点,上限]定义?
嗨,布鲁诺,
非常感谢您的反馈!
我不确定我是否正确理解了你的问题。所以我试着用一个很长的回答:
Lambda_guess和kappa_guess是用于促进拟合的值。假设我们想要得到一个函数的最小值。如果用户提供的第一个猜测值接近绝对最小值,则算法将适当收敛。如果猜测值不充分,则可能以局部最小值结束。这是最小二乘拟合算法的一个常见问题。
如果你的问题是关于kappa和lambda的“物理”值,文件文档。mlx描述了它们,但我认为在文档文件的在线显示中有一个视觉错误。MLX,因为这些方程没有出现。
checkRates中的离散度来自报告的数据(“测量”值)。所以离散度取决于数据源。例如,如果考虑意大利的数据,离散度就非常小。如果你以法国或比利时为例,这种差异会更大。
我恰当地回答了你的问题吗?
你好,Cheynet。
首先,恭喜你完成了有趣的工作。我有几个小问题要问:为lambda_guess和kappa_guess选择向量的意义是什么?
在checkRates测试中,测量值的离散度必须始终呈现类似于example_Country?这些测量值是什么?
嗨拉吉,
Q是活跃案例的数量。在目前的Matlab提交中,它被称为“隔离”,因为它假设每个测试呈阳性的案例都是隔离的。这个新的“状态”,标记为Q,可以有两种结果:恢复或死亡。请注意,在美国州和城市的情况下,活动病例数是/没有的,所以我使用的是确诊病例总数减去死亡病例数。虽然不理想,但总比什么都没有好。
嗨,Cheynet,有一个很小的疑问。Q(隔离病例)是否与活动病例总数相同?或者等于确诊病例总数??
嗨,维,
哦,我明白了!谢谢,我没有注意到(2)点的错别字。我会在下一个版本中改正它。
你好,Cheynet,很高兴看到你考虑我的想法。就(2)而言,正如我前面所指出的,在
Documentation.mlxillustration where you explain the Numerical solution part.
这个拼写错误在任何m文件或实现部分中都没有。所以结果不受这个错别字的影响。然而,一个
当他看到document .mlx中图解段中的矩阵A时,他应该不会感到困惑。
问候
嗨,维,
非常感谢您的反馈!
1)你说得对。我还注意到kappa_0和lambda_0应该具有时间逆的维数。我已经更新了文件文档。MLX与这些常数的适当定义。
2)很奇怪,我仍然看到矩阵是7x7。是SEIQRDP函数还是fit_SEIQRDP函数?
3)你提出了一个很重要的问题!我花了几个小时研究E0和I0。它们确实会影响你的适合度。理想情况下,它们也应该是自由参数,但这造成了许多未知……我对你的建议做了轻微修改,更新了示例,与中国的数据似乎很吻合。
你好,E. Cheynet。祝贺你的出色工作。有些错别字/建议需要注意,例如:
1.k1和lamda1的维数应为T^(-1)或其他,这取决于恢复率和死亡率的不同公式。它肯定不会对结果产生任何影响,但从数学上讲,指数项总体上应该是零维的。
2.矩阵A应该是7by7,但是它现在显示的是7by8。
3.目前的E0和I0使得模型对扰动数据高度敏感,特别是对印度的最终估计。因此,设定孵化时间为5天的初步猜测(如大多数文献报道的那样)应符合以下假设
I0 = 0.1* q0 (1);%最初感染病例数占报告病例的10%
E0 = 5* i0;%最初暴露病例数是最初感染的5倍。
问候
嗨,哈维尔,
这是个好问题。E和我都不知道。所以E0和I0也不知道。如果确诊病例数不为零,则E0或I0不太可能为零。将它们设为零是错误的,因为这将阻碍模拟。E0和I0的选择是任意的。我选择使用E0和I0等于Q0的值,但也有其他的选择。
你好,E. Cheynet!非常有趣的项目!我是一个初学者,有一个问题,在选择初始暴露和感染人群(E0和I0)的值时,您遵循了什么标准?我看到Q0是最初的活跃病例(Q0=确诊病例(1)-治愈病例(1)-死亡病例(1)),但为什么你们把E0和I0设置为最初的确诊病例(确诊病例(1),初始时间报告的总病例)?
谢谢你!
为了避免任何误解:这个模型没有涉及机器学习,所以“模型训练”在这里是没有意义的。
嗨Tsardoz,
如果查看函数fit_SEIQRDP,就会发现拟合算法并不能同时拟合所有的参数。例如,对于死亡率,首先得到一个估计,并对其进行约束,以限制风险,使其达到局部最小值。对于恢复速率,如果有的话,使用类似的方法。这大大减少了过拟合的问题。还能改进吗?毫无疑问。然而,用户仍然负责评估拟合是否有意义。这是函数"checkRate.m"的部分目的。
此外,拟合算法依赖于有限的参数范围。这就是为什么使用lsq曲率fit而不是nlinfit的原因。最后,评估什么是“现实的参数值”几乎没有意义,因为关于哪个参数是现实的、它们的真正含义是什么以及数据来源是什么的信息有限。例如:在这个帖子中有一个讨论,指出Peng等人使用的参数delta被错误地定义为“隔离时间的倒数”。这个参数的物理解释是问题所在,而不是它的值。
“如果死亡率或恢复率随时间恒定,就会出现过拟合。”
恐怕恰恰相反。在有限的数据中,你尝试和估计的参数越多,模型越过拟合,产生的结果就越差。
目标应该是在模型训练集预测上产生真实的参数值,而不是LSE。
嗨Tsardoz,
我忽略了您如何计算R0值,这意味着我无法判断您是否应用了适当的方法。请注意,我(到目前为止)没有包括任何基本复制数的计算。这本身就是一项研究。如果病死率或恢复率随时间恒定,则会出现过拟合。明确指出,该模型涉及与时间有关的恢复和死亡率。适当使用拟合算法是用户的责任。总而言之:垃圾输入,垃圾输出。
你好,dr Humayun Kabir,
检查'getDataCOVID'函数是否在您的工作区中。Matlab版本应该不会影响这个问题。
你好,E. Cheynet,
我的MATLAB是2018b版本。当我运行.mlx文件时,我面临以下问题:
未定义函数或变量“getDataCOVID”。
你能告诉我我做错了什么吗?
提前谢谢。
你好,卢·克鲁尔,
λ0、λ1、κ0、κ1为经最小二乘拟合得到的经验系数。如果可能的话,我会用计算出的死亡和康复病例的比率进行初步估计。最后的估计值是使用总方程组得到的。
正如变量“guess”所表示的,这是一个猜测。一开始是任意选择的。
我没有试图计算基本的复制数。我帮不上什么忙。
“tau”变量是一个时间延迟,它改进了与时间相关的恢复速率的建模。λ0、λ1为待调整的非量纲系数。λ0为随时间增大的恢复速率。
κ0和κ1也是经验系数。κ0为初始死亡率。κ1隐含了死亡率的时间延迟信息。我可能会在以后的版本中把他换成一个更明确的公式。
这就跟你问声好!
我是一个初学者,我对您的项目非常感兴趣,这对我帮助很大。为了更好地了解您的工作,我有几个问题要问您。
你是怎么得到λ0,λ1,κ0,κ1的?
您是如何估计初始GUESS参数的?
基本繁殖数的公式是什么?β*δ*(1-α)^T公式正确吗?
lamda_guess中的三个变量是什么意思?kappa_guess中的两个变量是什么意思?
如果你能给我一个答复,我将不胜感激
嗨,比尔,
这是个好问题。如果回收的数量未知,我认为设置初始条件时,回收E0的数量不等于0是一个好主意。我没有尝试看E0的不同值将如何影响隔离和死亡的计算曲线。你提出的数目可能是现实的。我对这个话题了解不够,无法作出判断。我猜E0的选择会影响参数“lambda”。然而,ode系统是耦合的,因此参数“lambda”涉及到多个方程中。这意味着E0在拟合过程中只有部分(但可能是重要的?)作用。
你好,Etienne,非常感谢你的英勇努力,处理这个案件的数量是未知的。你的例子突出了美国,但我主要感兴趣的是对我居住的英国的未来预测(英国也没有公布复苏的数据)。
我想知道,在恢复者未知的情况下,你有没有试过用恢复者的数量等于死亡人数的简单倍数来播种解算器?
我尝试在英国使用恢复=死亡*1.5;无需对输入数组进行其他调整,代码返回的结果与意大利的延时版本非常相似,后者具有良好的报告数据和非常合理的曲线拟合。
我很惊讶地发现,在我的英国例子中,恢复/死亡的比率是随时间变化的,与意大利的相当相似。所以你的求解器似乎有神奇的特性。
不需要答复,但感兴趣的任何意见,您可能有。
你好ZAFAR,没有。csv文件要下载。函数从GitHub存储库中读取表的内容,并将其存储为csv文件。然后将csv导入到本地工作区,读取并删除。但是也有其他方法可以使用。
需要下载。csv文件
嗨,Cheynet,很抱歉发布了这个脚本。我只是认为你可以运行“美国”和“韩国”的脚本,看看它是否有效。你可能会对“活跃”案例的情节如何接近峰值感兴趣……大约在4月30日。有趣的是,很多科学家都在使用确认日变化的数据和预测来预测峰值,这是一条对称的曲线,而“主动”追逐的预测曲线是不对称的,有一个长尾,我认为这更现实。感谢您的评论!
你好戴尔,
我不建议在评论区发布完整的Matlab脚本。据了解,美国城市没有“恢复数据”。我对“日本”这个国家没有错误。数据正确加载,拟合与我上传的最新版本成功完成。您可能使用了更容易出现错误的旧版本。
E.Cheynet,运行我发布的位置“美国”,“韩国”和“日本”的代码,你会看到问题。“美国”和“韩国”可以,但“日本”不行。当您查看csv数据文件时,它显示有已确认、死亡和恢复的数据,但当您使用位置“日本”时,您的代码不会选择tableConfired、tableDeaths或tableRecovered。
你好戴尔,
我不太明白你的意思。如果你谈论Github页面,你不能修改主分支,这是我使用的。
E.Cheynet,请注意,如果使用我添加的内容运行代码,这些图形需要设置文件夹。也就是说,如果你运行美国的数据,在Figs文件夹中必须有一个标记为US的文件子文件夹…或者如果你的位置是韩国,那么必须有一个文件设置为…无花果/韩国。
你好赛米亚,
我无法重现你得到的错误(使用R2019)。检查是否使用了提交的最新版本。如果仍然有问题,可以使用Matlab的手动调试工具
你好,E. Cheynet,
我的MATLAB是2019版的。我面临着以下问题:
使用lsqcurvefit错误(第262行)
函数值和YDATA大小不相等。
fit_SEIQRDP错误(第90行)
[多项式系数,~,残余,~,~,~,雅可比矩阵)= lsqcurvefit(@(对位,t) modelFun1 (para t),…
另一种选择是使用函数:websave('dummy.csv',yourFileName);它将读取您想要在互联网上访问的文件,并将其存储为CSV文件。然后,您可以使用传统的方法在Matlab中读取csv文件。
你好,M Farooq,
检查你的Matlab版本是否足够最新。我认为你至少需要Matlab R2018b来使用函数“delimitedTextImportOptions”。
或者,您可以手动导入您想要的表,并要求Matlab自动为您生成一个您将用于数据的函数。
你好,E. Cheynet,
我想跑
[tablec确认,tableDeaths, tablercovered,time] = getDataCOVID()
得到以下错误
未定义函数或变量delimitedTextImportOptions。
getDataCOVID中的错误(第14行)
opts = delimitedTextImportOptions("NumVariables", Ndays+5);
你能告诉我我做错了什么吗?
问候
据我所知,速率“δ”的维度是时间的倒数,所以它不应该用百分数表示,而应该用天数^(-1)表示。
谢谢迪翁。我已将变量delta重新定义为更新代码中感染病例进入隔离的速率。
感谢E. Cheynet的快速响应和您在创建这个神奇的代码实现方面的所有努力。把看作速率更有意义。在论文和你们的代码中明确说明一下delta v delta^(-1):在代码中,delta = 1/8意味着人们以12.5%的速度进入隔离,而delta = 1/10意味着以10%的速度进入隔离。因此,增加分母在逻辑上将减少隔离的实际数量并增加感染。
E.Cheynet……感谢华盛顿州的加入。
嗨迪翁,
我同意你的观点,delta的定义很奇怪。如果你看参考文献[2],也许有一个更好的定义。在他们的论文中,他们没有将其定义为隔离时间的倒数,而是人们进入隔离的速度。这更有意义....
[2] Munz P Hudea,我,穆,J。史密斯& r . J .(2009)。当僵尸攻击的时候!:僵尸感染爆发的数学模型。传染病模型研究进展,4,133-150。
Delta被定义为“平均隔离时间的倒数”,我认为这是指感染者被隔离的天数的倒数。但是,增加delta的分母(即增加隔离天数)会导致更多的感染。将delta作为隔离时间,可以增加隔离时间,减少感染,但总体曲线是不现实的。我无法从代码中判断我是否误解了delta的含义(可能是隔离率,但引用的Peng等人的论文将其定义为隔离时间),或者是否存在bug。有人玩过参数吗?
E.Cdheynet……以下是我尝试过的方法……我用一个新的Example_US_cities的Locations语句修改了您的代码。MLX如下:
fprintf(['最近更新:',datestr(time(end)),'\n'])
Location = ",华盛顿";
试一试
indC = find(contains(tableconfirmd . combined_key,Location)==1);
indD = find(contains(tableDeaths.Combined_Key,Location)==1);
捕获异常
searchLoc = strfind(tableConfirmed.Combined_Key,Location);
indC = find([searchLoc{:}]==1);
searchLoc = strfind(tableConfirmed.Combined_Key,Location);
indD = find([searchLoc{:}]==1);
结束
这是我的输出:
最近更新时间:04- 2020年4月4日
Combined_Key
______________________________
亚当斯,华盛顿,美国
“Asotin,华盛顿,美国”
“美国华盛顿本顿”
.
.
.
惠特曼,华盛顿,美国
“亚基马,华盛顿,美国”
《美国华盛顿,西澳》
“未分配,美国华盛顿”
错误消息:
矩阵索引超出删除范围。
datetime/parenAssign错误(第58行)
thisData(rowIndices) = [];
DaleExample_Washington中的错误(第38行)
确认时间(< = minNum) = [];
“Example_US_cities。Mlx”包含一个整个状态的例子。这里的州定义为数据库收集的与相同州名相关联的每个城市的总和。显然,如果我们看一下总人口的话,这就足够了。
你好戴尔,
这对个别州来说应该是可能的。然而,一个人将需要数据库存在,并在例如Github上是最新的。我没有试着去找。
你好戴尔,
非常感谢您的留言!
我不确定我理解你的要求,但目前的Matlab提交已经包含了一个美国城市的例子:“Example_US_cities.mlx”
嗨Jacobo,
主要原因是脚本删除了几乎没有数据的已确认案例,这对拟合没有意义。根据确诊病例的数量,变量“confirmed”有可能变为空。如果(手动)运行两次相同的行,也可能触发错误,因为向量“Confirmed”的大小发生了变化。在这两种情况下,用户都有责任检查向量“Confirmed”的大小。
你好,
我不能用example3文件运行canada。它在第40行说:“矩阵索引超出删除范围”。
嗨,E.Cheynet,我一直在玩你的代码…这太棒了!我现在试着分析单个州,比如华盛顿州。我运气不太好。你有任何代码像你张贴的例子多个城市?
一些美国城市的不适合似乎是因为我修改了恢复率,使其恒定。这不是个好主意。所以我决定回到与时间相关的恢复率。
来自美国的例子的新代码与我的Matlab 20a优化工具箱运行良好。新的美国城市直播脚本非常好(有一些不太适合某些城市),但遗憾的是,美国没有那些被感染但现在已经恢复的人的准确数据。我很想知道中国、意大利和法国正在做什么来获取这些美国没有做的数据。
你好,谢谢你漂亮的代码,
我在getDatacovid中有错误。m in line: opts = delimitedTextImportOptions
再次感谢。
你好,
我是Reji Kumar。
我的MATLAB比2012版本更老。我如何使用其中的代码?有人吗?请帮忙。
嗨艾蒂安,
非常感谢你的解释。现在我的怀疑很清楚了。因此在mlx文件中的图中‘确认(报告)’=确认(JHU数据)-恢复(JHU数据)-死亡(JHU数据);从JHU数据,然后匹配到隔离Q(t)。我把你代码中的“确认(报告)”和JHU数据中的“确认”数字混淆了。再次感谢。
嗨艾蒂安,
非常感谢你的解释。我的理解上还有差距。请忽略我的上一个帖子。这是我的问题。在mlx文件生成的图中,确认(报告)、恢复(报告)、死亡(报告)与JHU实际数据之间是如何关联的?特别是图中确认(报告)的数据与JHU中“确认”的数据之间的关系。因此,确认(报告)的数据点在图中某个时间后会下降,但JHU中的“确认”数据从不下降。
嗨Ranajoy,
你提出了一个合理的观点。在约翰霍普金斯大学(John Hopkins University)的Github存储库中,只有三个类别是可用的:复原、确认和死亡。他们对“确诊”的定义是“经检测呈阳性”。这就是为什么在这个数据库中确认的数量不能减少。我想“确诊(感染)”这个词并不是最好的选择,因为感染病例不会永远具有传染性。的确,在我上传的例子中,我也使用了“确认”这个术语。确诊病例实际上是隔离病例,因为我认为在现实生活中,一旦有人被“确诊”,他们就会被隔离,这可能是最接近“活跃病例=确诊-治愈-死亡”的定义。
你好,
如果我没理解错的话,数据是从约翰霍普金斯大学的网站上提取的,在约翰霍普金斯大学的github中有四种类别:确诊、死亡、康复、活动(其中确诊=死亡+康复+活动;在数据中的任何时间点)。因此,约翰霍普金斯定义的“确诊”永远不会落下,因为它是死亡、康复和活动的总和。但在这个广义SEIR模型中,根据模型,“确认”图在一段时间后持续下降,所以当我们与模型匹配时,我们是否应该不使用“活动”数据而使用“确认”数据呢?
嗨,尤金,
约翰霍普金斯大学似乎已经开始在他们的Github页面上上传新的数据集,特别关注美国。我会等他们上传完所有的东西再看数据。
所有的*mlx文件现在运行得很好。example4的实际数据图。MLX仍然显示一些负值,但注意这些值被忽略。最令人惊奇的图形是意大利区域的伦巴第地区图形。感染曲线的扁平化是明显的,但如果忽略恢复和死亡状态,就会错过它。
遗憾的是,由于缺乏恢复的数据,你们无法将美国的数据与SEIR模型相匹配。刚刚(美国东部时间4月1日下午1点)约翰·霍普金斯大学报告了1907年40例美国确诊感染,4127例死亡,7141例康复。
更新:意大利地区的数据在数据库格式更改后已经更新。如果您试图运行旧版本的代码,它将不能很好地工作。
黑尤金,
我也注意到了这个警告。显然,在某些病例中,报告的康复+死亡人数超过了"确诊"人数。这很奇怪,但可能是由于报告错误。由于这是一个来自数据库的问题,所以我实现了一个快速而肮脏的解决方案。在更新的函数fit_SEIQRD中,我简单地禁止“实际情况”的数量变为负数,并将其设置为零
你好,Etienne,我修正了我昨天提到的问题,在取“diff”之前,通过对精细采样的拟合曲线进行去采样。我现在得到了一个非常好的拟合值和每日报告值的图表,至少对于意大利是这样的。谢谢你的耐心,希望你的wifi能正常工作。
你好,
很抱歉回复晚了。我暂时无法使用wifi(只有移动网络)。我尽量在不久的将来给你答复
嗨,Etienne,我不想偷懒,但我昨天才开始使用Matlab(我有IDL的经验)。我希望您能给我一些建议,以解决与您的SEIR建模相关的问题。
我采用了你的Example3,并使它在包括我居住的英国在内的几个国家工作。然后,我将“diff”操作符应用到累积数组(fitting and reporting),以模拟日常案例。
我在你的代码中的累计报告数组和从其他来源的每日报告案例之间取得了良好的一致,所以我的“diff”工作正常。然而,当对拟合曲线应用“diff”时,他们大大低估了每日报告病例。
我追踪到这一事实,即拟合曲线的采样比报告值更精细(例如471个元素相比意大利的37个元素)。
请您给我一些非常笼统的建议,如何使拟合数组与报告数组一致,以便“diff”返回可比较的结果,例如使D数组与Example3中的死亡一致。
感谢您提供的任何建议,再次感谢您的出色工作
你好,
我得到了一个问题,而建模加拿大与example3文件。它在第40行说:“矩阵索引超出删除范围”。
你好,我刚刚下载了最新的代码和数据后运行了Example4。在今天之前,SEIR模型在所有省份都运行良好,但今天中国有9个省份正在建模阴性确诊病例。程序输出一个警告。
嗨,供你参考,我刚刚下载了ECheynet-SEIR-aefecf6,并在Matlab R2020a中运行了所有的例子,他们都执行得很好。
非常感谢和尊敬您先生的一些优秀的代码!
嗨,乔丹,
您可以检查time(1)的值。如果time(1) >=datetime(2020,04,01),则N= 0。我还注意到约翰霍普金斯大学的数据库昨天已经更改了,所以示例不能很好地工作。我需要更新示例1到4。
这里有些不对,当它返回N = 0时,这个dt正确吗?谢谢你的帮助!!
Dt = 0.1;%时间步长
Time1 = datetime(time(1)):dt:datetime(2020,04,01);
N = numel(time1);
t = [0:N-1].*dt;
谢谢。遗憾的是,约翰霍普金斯大学的网站没有将恢复的数据放入csv文件中。让我们希望他们开始放入恢复的数据,以便您的代码可以按照未来的日期运行。约翰霍普金斯大学的网站首次在JH网站上列出了为美国恢复的病毒。在他们的互动网页上,今天是他们提供美国复原数据的第一天(827人死亡,354人复原意大利:20499人死亡,112,982人复原):
https://coronavirus.jhu.edu/map.html
非常感谢你,Cheynet。
嗨,约书亚和尤金,
你是对的,在使用的url地址中有一个拼写错误。现在应该加以纠正。约翰霍普金斯大学的Github账户使用了更新的数据集,没有“恢复病例”的数量。这是一个遗憾,因为这是一个有价值的信息,对拟合程序。因此,我决定只使用到23-03-2020更新的数据。主要原因是,提交的目的只是为了展示如何在Matlab中进行广义SEIR模型的拟合。
请我下载了新的更新,但我有这个错误消息。求你了,我要怎么补救
使用urlreadwrite错误(第92行)
服务器没有找到与此请求匹配的资源。
urlwrite错误(第52行)
[f,status] = urlreadwrite(mfilename,catchErrors,url,filename,varargin{:});
getDataCOVID错误(第36行)
urlwrite(文件名,“dummy.csv”);
艾蒂安。我下载了新文件。Example1运行,但Example2、Example3和Example4都停止,并出现以下错误。非常感谢您为这段代码所做的工作。
使用urlreadwrite错误(第92行)
服务器没有找到与此请求匹配的资源。
urlwrite错误(第52行)
[f,status] = urlreadwrite(mfilename,catchErrors,url,filename,varargin{:});
getDataCOVID错误(第36行)
urlwrite(文件名,“dummy.csv”);
示例文件现在应该可以正常工作了。
嗨,尤金,
谢谢你提供的信息!我看到约翰霍普金斯大学创建了一个新的数据库。但是,它们不再包括“恢复”的数量作为时间的函数。真奇怪……今晚我将尝试更新这个示例。
Etienne,所有4个例子和意大利分析昨晚都在工作,但当约翰霍普金斯大学更新他们的数据时,Example2、Example3和Example4都产生了2020年3月24日的时间变量无效的错误(时间向量中的NaT)。意大利的例子仍然有效,但是它从意大利下载数据。下面是错误消息,时间向量的最后一个元素是NaT,不是有效的日期。
使用dateformverify错误(第18行)
DATESTR将日期数字转换为日期向量失败。日期超出范围。
datestr错误(第200行)
S = datef。Ormverify (dtnumber, dateformstr, islocal);
datetime/datestr错误(第801行)
S = datestr(datenum(this),varargin{:});
嗨。
如何解决以下问题:
> fit_SEIQRDP(Q, R, D, Npop, E0, I0, time, guess, varargin)
尝试执行SCRIPT varargin函数:
谢谢
嗨,尤金,
谢谢你的留言!我没有注意到“今天”这个功能需要财务工具箱。在更新版本的代码中,我写了:“floor(datenum(现在)”而不是“datenum(今天)”
这些代码真的很棒。谢内特博士,谢谢你帮我们做这些。
你能帮我们画一下残差吗?
这个项目很出色。我将在我的研究生概率与统计学课程中使用它来演示如何用数据拟合模型的参数。我需要进行一次编辑才能让程序运行起来,检索今天日期的“today”只在Mathworks财务工具箱中可用,所以我只需要以适当的格式输入今天的日期。
你好何塞,
谢谢你的建议。不幸的是,我既没有资格也没有时间来完成或贡献这项工作。
他Jacobo,
由于不同流行地区之间的“时间延迟”,我认为它不会在世界范围内很好地发挥作用。同样重要的是要记住,不应该尝试使用seiqrdpm函数进行长期预测。这是由于存在很大的不确定性,特别是当数据集有限时。
你好,
嗨Jacobo,
我已经更新了示例文件,对变量“猜”和使用的数字进行了更多的教学描述。
回应:
看来你把它修好了,而且更直观了!神奇的谢谢。非常好的代码。
___
进一步的问题:
我正在尝试为世界做一个SEIR模型。我使用了你的代码,但可能创建一个名为“世界”的区域,添加所有病例、死亡等…会有帮助吗?
我通过添加4个。mat文件来解决这个问题,这些文件是从。csv文件中导入的,其中我添加了区域“world”。
作为一个建议,为世界建立一个区域是个好主意。
到目前为止,我还无法对世界做出正确的预测,曲线不够陡峭。我仍然在尝试一些价值观。
这就跟你问声好!我同意……如果您不介意,尽管速度会慢一些,但我们可以使用这个平台.....进行合作我已经有一些优秀的人在做它,所以如果有什么您想要实现的东西,想要与其他人并行化,请告诉我。
我现在是这么想的:
>在“fitter”周围创建一个“包装器”,以允许运行所有行数据(国家和地区)
->输出到.csv或xls的输入和输出从Fit .csv或xls
->添加其他指标的模拟结果,如
->天直到高峰
——>受感染总人数
->总死亡人数
->将数据(可能带有API)与其他人口统计信息合并,可能来自世界经济论坛或世界卫生组织
->在输出数据中运行一些数据分析,试图找到模式和相关性
->在输入和输出之间运行一个相关矩阵,以评估拟合参数对拟合和“后处理”变量结果的敏感性
你怎么看?
你好何塞,
实际上,我已经上传了一个更新的版本,其中“包含”函数被“strfind”取代昨天,为那些谁与旧的Matlab版本工作。我不建议你泄露你的电子邮件。否则你会收到大量垃圾邮件。
你好Cheynet,
这就是我为解决兼容性问题所做的工作
%%%%%%在2015年使用,因为“包含”不能工作
% id = strfind (tableRecovered.ProvinceState,“我们”);
% Index = find(not(cellfun('isempty',id)));
对于另一个问题,我简单地使用了plot命令而不是原来的命令,如下所示:
情节(time1, Q, r, time1, r,“c”,time1, D,‘g’,time1,我,“b”,“线宽”,2);
抓住
情节(时间、Confirmed-Recovered-Deaths‘罗’,时间恢复,“bo”,时间,死亡,“去”,“线宽”,1);
我在巴西带领一群朋友,制作不同的模型,其中一个就是其中之一。如果你能和我们联系,那就太好了。我不知道我是否可以在这里发表我的邮件,但你可以在linkdin上找到我,我的名字是José Roberto Clark Reis。
谢谢,
穆
哦,这是同时发布的。非常感谢Cheynet先生,太棒了!我是一名电化学领域的科学家,但现在我正利用在家的时间研究其他重要的课题:)
嗨,费边,
我上传了一个新版本的数据。Mat文件不再需要。使用函数“getDataCOVID”,数据直接从上面提到的Github存储库中读取。
嘿,社区,
我可能有一个非常基本的问题。我从GitHub (.csv文件)获得了这种疾病的最新统计数据。如何将数据传输到数据。m文件?
我试图复制粘贴额外的列到单表(恢复,确认,死亡,时间)直接在Matlab中保存数据的变化。m文件。
我正在得到错误:
使用strfind错误
Cell必须是字符向量的单元格数组。
我不太明白,因为这个函数,据我所知,是用来找到我想要评估的国家的。(我在示例3的代码中没有改变任何东西)
当我重新加载原始数据。M文件,代码运行良好。
总的来说:谢谢你的出色工作!
最好的问候,
费边
嗨Jacobo,
我已经更新了示例文件,对变量“猜”和使用的数字进行了更多的教学描述。
*我解决了这个问题* =>我不知道是哪个问题,我只是在。mlx而不是。m中运行它
____
你猜的数字是多少?顺序是什么?我搞不清楚。
我发现他们是
Alpha:保护率
Beta:感染率
伽马:平均潜伏时间的倒数
:平均隔离时间的倒数
Lambda0和lambda1:用于随时间变化的治愈率的系数
Kappa0和kappa1:用于随时间变化的死亡率的系数
我在这里发布了一个请求帮助的帖子:https://la.mathworks.com/matlabcentral/answers/511876-issue-with-seir-model-for-mathlab
我很期待在我的工作中使用你们的软件,我真的希望我能使用它。
我犯了这个错误:
使用SEIQRDP错误
输入参数太多。
example3中的错误(第34行)
[S,E,I,Q,R,D,P] = SEIQRDP(alpha1,beta1, gama1,delta1,Lambda1,Kappa1,Npop,E0,I0,Q0,R0,D0,t);
黑,
感谢您的反馈!
函数“contains”是在Matlab 2016b中引入的,如果你有一个较旧的版本,你将无法使用它。我认为另一个词是" strfind"
对于第二个错误,这可能也是一个兼容性问题,尽管它对我来说有点模糊。函数“datetime”是在Matlab 2014b中引入的,但可能有一些更新只适用于最新版本。我用Matlab 2019b写了这个函数。或者,你可以使用"datenum"和函数"datetick"。
你好,
我在试着运行你很好的实现。例1工作得很好。例2,我至少遇到了两个问题。第一个是"contains"函数,就在代码的开头。我绕过了它,并以与湖北省相对应的156值开始。它运行得很好。
然后,当我进入:
> >图
semilogy (time1, Q, r, time1, r, b, time1, D,“k”);
使用符号学错误
需要一个数字或双可转换参数
我用2015a。这可能是兼容性问题吗?
谢谢