使用深度学习分类缺陷晶片地图上
这个例子展示了如何分类八个类型的制造缺陷晶片地图上使用一个简单的卷积神经网络(CNN)。
晶片薄圆盘的半导体材料,通常是硅,作为集成电路的基础。每个晶片产量几个人电路(ICs),分为死亡。自动检查机测试晶圆集成电路的性能。机器产生图像,称为晶片地图,指明哪些模具正确执行(通过)和模具不符合性能标准(失败)。
传球的空间格局和失败死在一个晶片地图可以显示生产过程中的具体问题。深度学习的方法可以有效地分类在大量的晶圆缺陷模式。因此,通过使用深度学习,您可以快速识别生产问题,使生产过程及时修复,减少浪费。
这个例子展示了如何训练一个分类网络探测和分类八种制造缺陷模式。示例还显示了如何评估网络的性能。
下载地图数据wm - 811 k的晶圆缺陷
下面的例子使用了wm - 811 k的晶圆缺陷地图数据集(1][2]。数据集由811457片地图图片,其中包括172950标记图像。每个图像只有三像素值。的值0显示背景、价值1代表正确表现死亡,和价值2代表有缺陷的模具。9个标签的标签图像有一个基于缺陷模的空间格局。数据集的大小是3.5 GB。
集dataDir的期望位置数据集。下载数据集使用downloadWaferMapDatahelper函数。这个函数是附加到例子作为支持文件。金宝app
dataDir = fullfile (tempdir,“WaferDefects”);downloadWaferMapData (dataDir)
预处理和增加数据
数据存储在一个垫子文件作为一个结构数组。数据集加载到工作区。
dataMatFile = fullfile (dataDir,“MIR-WM811K”,“MATLAB”,“WM811K.mat”);waferData =负载(dataMatFile);waferData = waferData.data;
探索数据显示第一个元素的结构。的waferMap字段包含图像数据。的failureType字段包含缺陷的标签。
disp (waferData (1))
waferMap: [45×48 uint8] dieSize: 1683 lotName:“lot1”waferIndex: 1 trainTestLabel:“训练”failureType:“没有”
重新格式化数据
这个示例只使用标记图像。删除未标示的图像结构。
unlabeledImages = 0(大小(waferData),“逻辑”);为idx = 1:尺寸(unlabeledImages, 1) unlabeledImages (idx) = isempty (waferData (idx) .trainTestLabel);结束waferData (unlabeledImages) = [];
的dieSize,lotName,waferIndex字段不相关图像的分类。示例数据分区到训练、验证和测试集比指定的使用不同的约定trainTestLabel字段。删除这些字段的结构使用rmfield函数。
fieldsToRemove = [“dieSize”,“lotName”,“waferIndex”,“trainTestLabel”];waferData = rmfield (waferData fieldsToRemove);
指定图像类。
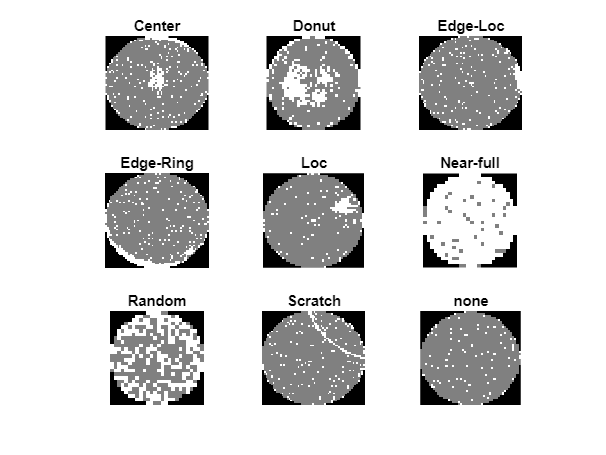
defectClasses = [“中心”,“甜甜圈”,“Edge-Loc”,“环”,“疯狂的”,”“准””,“随机”,“抓”,“没有”];numClasses =元素个数(defectClasses);
申请额外的预处理操作数据,如调整图像匹配输入大小或网络应用随机网络分类训练,您可以使用一个增强图像数据存储。你不能从数据创建一个增强的图像数据存储结构,但是您可以创建数据存储的数据表。将数据转换为一个表有两个变量:
WaferImage——晶圆缺陷地图图像FailureType——为每个图像分类标签
waferData = struct2table (waferData);waferData.Properties。VariableNames = [“WaferImage”,“FailureType”];waferData。FailureType =分类(waferData.FailureType defectClasses);
显示一个示例图像从每个输入图像类使用displaySampleWaferMapshelper函数。这个函数是附加到例子作为支持文件。金宝app
displaySampleWaferMaps (waferData)
平衡数据采样过密
显示的图像每个类的数量。数据集是严重不平衡,显著减少每个缺陷类的图像比图片的数量没有缺陷。
总结(waferData.FailureType)
中心4294年甜甜圈555 Edge-Loc 5189环9680 Loc 3593几乎饱和149随机866 1193没有147431
改善类平衡,oversample缺陷类使用oversampleWaferDefectClasseshelper函数。这个函数是附加到例子作为支持文件。金宝app辅助函数附加数据集和五个修改每个缺陷图像的副本。每个副本都有其中一个修改:水平反射,垂直反射,或由多个旋转90度。
waferData = oversampleWaferDefectClasses (waferData);
课后显示图像的每个类的数量平衡。
总结(waferData.FailureType)
中心25764年甜甜圈3330 Edge-Loc 31134环58080 Loc 21558几乎饱和894随机5196 7158没有147431
数据分割成训练、验证和测试集
将采样过量数据集分为训练、验证和测试集使用splitlabels(计算机视觉工具箱)函数。大约90%的数据用于训练,5%用于验证,5%是用于测试。
labelIdx = splitlabels (waferData (0.9 0.05 0.05),“随机”TableVariable =“FailureType”);trainingData = waferData (labelIdx {1}:);validationData = waferData (labelIdx {2}:);testingData = waferData (labelIdx {3}:);
增加训练数据
指定一组随机扩增适用于训练数据使用imageDataAugmenter对象。添加随机扩增的训练图像可以避免网络过度拟合训练数据。
8月= imageDataAugmenter (FillValue = 0, RandXReflection = true, RandYReflection = true, RandRotation = 360年[0]);
指定的输入规模网络。创建一个augmentedImageDatastore读训练数据,调整数据,网络输入大小,并应用随机扩增。
inputSize = [48 48];dsTrain = augmentedImageDatastore (inputSize trainingData,“FailureType”DataAugmentation = 8月);
创建数据存储,读取验证和测试数据和调整网络输入数据的大小。你不需要应用随机扩增验证或测试数据。
dsVal = augmentedImageDatastore (inputSize validationData,“FailureType”);dsVal。MiniBatchSize = 64;dst = augmentedImageDatastore (inputSize testingData,“FailureType”);
创建网络
定义了卷积神经网络架构。图像输入层的范围反映了这样一个事实:晶片地图只有三个层次。
层= [imageInputLayer inputSize [1],…归一化=“rescale-zero-one”、最小值= 0,Max = 2);convolution2dLayer(3 8填充=“相同”)batchNormalizationLayer reluLayer maxPooling2dLayer(2步= 2)convolution2dLayer(填充= 3,16日“相同”)batchNormalizationLayer reluLayer maxPooling2dLayer(2步= 2)convolution2dLayer(3、32、填充=“相同”)batchNormalizationLayer reluLayer maxPooling2dLayer(2步= 2)convolution2dLayer(64,填充=“相同”)batchNormalizationLayer reluLayer dropoutLayer fullyConnectedLayer (numClasses) softmaxLayer classificationLayer];
指定培训选项
指定培训选项为亚当的优化。列车网络30时代。
选择= trainingOptions (“亚当”,…ResetInputNormalization = true,…MaxEpochs = 30,…InitialLearnRate = 0.001,…L2Regularization = 0.001,…MiniBatchSize = 64,…洗牌=“every-epoch”,…Verbose = false,…情节=“训练进步”,…ValidationData = dsVal,…ValidationFrequency = 20);
列车网络或下载Pretrained网络
默认情况下,示例加载pretrained晶圆缺陷分类网络。pretrained网络使您能够运行整个示例没有等待培训完成。
训练网络,设置doTraining变量在下面的代码真正的。火车模型使用trainNetwork函数。
火车在GPU如果一个是可用的。使用GPU需要并行计算工具箱™和CUDA NVIDIA GPU®®启用。有关更多信息,请参见GPU计算的需求(并行计算工具箱)。
doTraining =假;如果doTraining trainedNet = trainNetwork (dsTrain层,选项);modelDateTime =字符串(datetime (“现在”格式=“yyyy-MM-dd-HH-mm-ss”));保存(fullfile (dataDir“trained-WM811K——”+ modelDateTime +“.mat”),“trainedNet”);其他的downloadTrainedWaferNet (dataDir);trainedNet =负载(fullfile (dataDir“CNN-WM811K.mat”));trainedNet = trainedNet.preTrainedNetwork;结束

量化网络性能测试数据
每一个测试图像的使用进行分类分类函数。
defectPredicted =分类(trainedNet, dst);
计算网络的性能相对于地面实况分类混淆矩阵使用confusionmat函数。想象混淆矩阵使用confusionchart函数。的值在这个矩阵的对角线显示正确的分类。一个完美的分类器的混淆矩阵值唯一的对角线上。
defectTruth = testingData.FailureType;cmt = confusionmat (defectTruth defectPredicted);图confusionchart (cmt,类别(defectTruth)标准化=“row-normalized”,…Title =“测试数据混淆矩阵”);

精度、召回和F1的分数
这个例子使用几个评估网络性能指标:精度、回忆,F1的分数。这些指标被定义为一个二进制分类。克服这多类问题的限制,您可以考虑预测作为一组二进制分类,每个类。
正确预测的精度的比例图像属于一个类。鉴于真阳性数(TP)和假阳性(FP)分类,可以计算精度为:
回忆是属于一个特定的类,图像的比例预测属于这个班。鉴于TP的计数和假阴性(FN)分类,可以计算回忆:
F1分数谐波均值的精度和召回值:
对于每个类,计算的精度,还记得,和F1分数使用TP的计数,FP, FN结果混淆矩阵。
prTable =表(大小= [numClasses 3], VariableTypes = [“细胞”,“细胞”,“替身”),…VariableNames = [“回忆”起,“精度”,“F1”),RowNames = defectClasses);为idx = 1: numClasses numTP = cmt (idx idx);numFP =总和(cmt (:, idx)) - numTP;numFN =总和(cmt (idx:), 2)——numTP;精度= numTP / (numTP + numFP);回忆= numTP / (numTP + numFN);defectClass = defectClasses (idx);prTable。回忆{defectClass} =回忆;prTable。精密{defectClass} =精度; prTable.F1(defectClass) = 2*precision*recall/(precision + recall);结束
显示每个类的指标。分数接近1显示更好的网络性能。
prTable
prTable =9×3表召回精密F1 __________ __________ _________中心{[0.9169]}{[0.9578]}0.93693甜甜圈{[0.8193]}{[0.9067]}0.86076 Edge-Loc{[0.7900]}{[0.8384]} 0.81349环{[0.9859]}{[0.9060]}0.94426 Loc{[0.6642]}{[0.8775]}几乎0.75607全面{[0.7556]}{[1]}0.86076随机{[0.9692]}{[0.7683]}0.85714划痕{[0.4609]}{[0.8639]}0.60109没有{[0.9696]}{[0.9345]}0.95173
Precision-Recall曲线和Area-Under-Curve (AUC)
除了返回每个测试图像的一个分类,网络还可以预测的概率测试图像的每个缺陷类。在这种情况下,precision-recall曲线提供了一个替代的方法来评估网络性能。
计算precision-recall曲线,首先执行一个二进制分类对每个缺陷类通过比较对任意阈值的概率。当概率超过阈值时,您可以指定目标类的图像。阈值的选择影响TP的数量,FP, FN结果和精度和召回的分数。评估网络性能,必须考虑性能阈值的范围。Precision-recall曲线绘制精度和回忆之间的权衡值作为二进制分类您调整阈值。AUC度量总结precision-recall曲线为一个类中的一个数字范围[0,1],其中1表示一个完美的分类无论阈值。
计算每一个测试图像的概率属于每个缺陷类的使用预测函数。
defectProbabilities =预测(trainedNet, dst);
使用rocmetrics函数计算精度、召回和AUC为每个类的阈值范围。画出precision-recall曲线。
中华民国= rocmetrics (defectTruth defectProbabilities、defectClasses AdditionalMetrics =”前的“);图绘制(中华民国,XAxisMetric =“reca”YAxisMetric =”前的“);包含(“回忆”起)ylabel (“精度”网格)在标题(“所有类Precision-Recall曲线”)

precision-recall曲线为一个理想的分类器穿过点(1,1)的类precision-recall曲线,倾向于(1,1),等环和中心是类的网络具有最好的性能。网络的最差表现刮伤类。
计算和显示的AUC值精度/召回曲线为每个类。
prAUC = 0 (numClasses, 1);为idx = 1: numClasses defectClass = defectClasses (idx);currClassIdx = strcmpi (roc.Metrics。ClassName, defectClass);reca = roc.Metrics.TruePositiveRate (currClassIdx);prec = roc.Metrics.PositivePredictiveValue (currClassIdx);prAUC (idx) = trapz (reca(2:结束),prec(2:结束);% prec(1)总是NaN结束prTable。AUC = prAUC;prTable
prTable =9×4表召回精密F1 AUC __________ __________ ____ ____中心{[0.9169]}{[0.9578]}0.93693 - 0.97314甜甜圈{[0.8193]}{[0.9067]}0.86076 - 0.89514 Edge-Loc{[0.7900]}{[0.8384]} 0.81349 - 0.88453环{[0.9859]}{[0.9060]}0.94426 - 0.73498 Loc{[0.6642]}{[0.8775]}几乎0.75607 - 0.82643全面{[0.7556]}{[1]}0.86076 - 0.79863随机{[0.9692]}{[0.7683]}0.85714 - 0.95798划痕{[0.4609]}{[0.8639]}0.60109 - 0.65661没有{[0.9696]}{[0.9345]}0.95173 - 0.99031
使用GradCAM可视化网络决定
Gradient-weighted类激活映射(Grad-CAM)产生一种视觉解释决策的网络。您可以使用gradCAM函数图像的识别部分,大多数网络预测的影响。
甜甜圈缺陷类
的甜甜圈缺陷的特征是图像有缺陷像素集中在同心圈模具的中心。大多数的图像甜甜圈缺陷类没有缺陷像素在死亡的边缘。
这两个图片显示数据甜甜圈缺陷。网络的正确分类左边的图像作为甜甜圈缺陷。网络是不是右边的图像作为一个环缺陷。图片的颜色叠加对应的输出gradCAM函数。影响图像的地区,大多数网络分类和明亮的颜色叠加出现。图像分类作为一个环缺陷,缺陷边界的死被视为重要的。一个可能的原因可能有更多环图像训练集相比甜甜圈图像。


疯狂的缺陷类
的疯狂的缺陷的特征是图像有缺陷像素集中在一个blob远离死亡的边缘。这两个图片显示数据的Loc缺陷。网络的正确分类左边的图像作为疯狂的缺陷。右边的图像分类错误网络和分类的缺陷Edge-Loc缺陷。图像分类作为一个Edge-Loc缺陷,缺陷边界的死是网络中最具影响力的预测。的Edge-Loc缺陷不同于疯狂的缺陷主要是在集群的缺陷的位置。


比较正确的分类和错误分类
你可以探索其他的实例正确分类和分类错误的图像。指定一个类来评估。
defectClass = defectClasses (2);
defectClasses (2);

找到所有图片的索引与指定的缺陷类型地面真理或预测的标签。
idxTrue =找到(testingData。FailureType==defectClass); idxPred = find(defectPredicted == defectClass);
找到正确的指标分类图像。然后,选择一个图像来评估。默认情况下,这个例子中正确评估第一个分类图像。
idxCorrect =相交(idxTrue idxPred);idxToEvaluateCorrect = 1;imCorrect = testingData.WaferImage {idxCorrect (idxToEvaluateCorrect)};
1;imCorrect = testingData.WaferImage {idxCorrect (idxToEvaluateCorrect)};

的指标分类错误的图像。然后,选择一个图像的评估和预测类的图像。默认情况下,这个例子中评估第一个分类错误的形象。
idxIncorrect = setdiff (idxTrue idxPred);idxToEvaluateIncorrect = 1;imIncorrect = testingData.WaferImage {idxIncorrect (idxToEvaluateIncorrect)};labelIncorrect = defectPredicted (idxIncorrect (idxToEvaluateIncorrect));
1;imIncorrect = testingData.WaferImage {idxIncorrect (idxToEvaluateIncorrect)};labelIncorrect = defectPredicted (idxIncorrect (idxToEvaluateIncorrect));

调整测试图像匹配网络的输入大小。
imCorrect = imresize (imCorrect inputSize);imIncorrect = imresize (imIncorrect inputSize);
生成地图使用gradCAM函数。
scoreCorrect = gradCAM (trainedNet imCorrect defectClass);scoreIncorrect = gradCAM (trainedNet imIncorrect labelIncorrect);
地图显示得分超过原来的晶片地图使用displayWaferScoreMaphelper函数。这个函数是附加到例子作为支持文件。金宝app
t = nexttile图tiledlayout (1、2);displayWaferScoreMap (imCorrect scoreCorrect t)标题(“正确的分类(“+ defectClass +“)”)t = nexttile;displayWaferScoreMap (imIncorrect scoreIncorrect t)标题(“误分类(“字符串(labelIncorrect) + +“)”)

引用
[1],学识渊博,Jyh-Shing r .张成泽,Jui-Long陈。“晶圆图故障模式识别和相似度排名大规模数据集。”IEEE半导体制造业28日,没有。1(2015年2月):1 - 12。https://doi.org/10.1109/TSM.2014.2364237。
[2]张成泽,罗杰。“米尔全集。”http://mirlab.org/dataset/public/。
[3]Selvaraju, Ramprasaath R。,Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. “Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization.” In2017年IEEE计算机视觉国际会议(ICCV),618 - 26所示。威尼斯:IEEE 2017。https://doi.org/10.1109/ICCV.2017.74。
[4]T。,Bex. “Comprehensive Guide on Multiclass Classification Metrics.” October 14, 2021. https://towardsdatascience.com/comprehensive-guide-on-multiclass-classification-metrics-af94cfb83fbd.
另请参阅
trainingOptions|trainNetwork|augmentedImageDatastore|imageDataAugmenter|imageDatastore|分类|预测|confusionmat|confusionchart