sim
Simulate trained reinforcement learning agents within specified environment
描述
例子
模拟加强学习环境
Simulate a reinforcement learning environment with an agent configured for that environment. For this example, load an environment and agent that are already configured. The environment is a discrete cart-pole environment created withrlPredefinedEnv。代理人是政策梯度(rlpgagent) 代理人。有关此示例中使用的环境和代理的更多信息,请参见Train PG Agent to Balance Cart-Pole System。
rng(0)% for reproducibilityloadrlsimexample.matenv
env = CartPoleDiscreteAction with properties: Gravity: 9.8000 MassCart: 1 MassPole: 0.1000 Length: 0.5000 MaxForce: 10 Ts: 0.0200 ThetaThresholdRadians: 0.2094 XThreshold: 2.4000 RewardForNotFalling: 1 PenaltyForFalling: -5 State: [4×1 double]
agent
agent = rlPGAgent with properties: AgentOptions: [1×1 rl.option.rlPGAgentOptions] UseExplorationPolicy: 1 ObservationInfo: [1×1 rl.util.rlNumericSpec] ActionInfo: [1×1 rl.util.rlFiniteSetSpec] SampleTime: 0.1000
通常,您会使用trainand simulate the environment to test the performance of the trained agent. For this example, simulate the environment using the agent you loaded. Configure simulation options, specifying that the simulation run for 100 steps.
simopts= rlSimulationOptions(“ maxsteps',100);
对于此示例中使用的预定义的卡特杆环境。您可以使用plotto generate a visualization of the cart-pole system. When you simulate the environment, this plot updates automatically so that you can watch the system evolve during the simulation.
plot(env)

Simulate the environment.
经验=sim(env,agent,simOpts)

经验=带有字段的结构:Observation: [1×1 struct] Action: [1×1 struct] Reward: [1×1 timeseries] IsDone: [1×1 timeseries] SimulationInfo: [1×1 struct]
输出结构经验记录从环境中收集的观察结果,动作和奖励以及模拟过程中收集的其他数据。每个字段都包含一个timeseries对象或结构timeseries数据对象。例如,经验是atimeseries在模拟的每个步骤中包含代理在卡车孔系统上施加的动作。
经验
ans =带有字段的结构:CartPoleAction:[1×1个时间]
使用多个代理模拟模金宝app拟环境
Simulate an environment created for the Simulink® model used in the example培训多个代理商执行协作任务, using the agents trained in that example.
Load the agents in the MATLAB® workspace.
loadrlCollaborativeTaskAgents
Create an environment for therlCollaborativeTask金宝appSimulink®型号,它具有两个代理块。由于两个块使用的代理(agentAandagentB)已经在工作空间中了,您无需传递其观察和行动规范即可创建环境。
env = rl金宝appSimulinkenv('rlCollaborativeTask',[[“ rlcollaborativetask/agent a”,“ rlcollaborativetask/agent b”]);
加载由rlCollaborativeTaskSimulink® model to run.
rlCollaborativeTaskParams
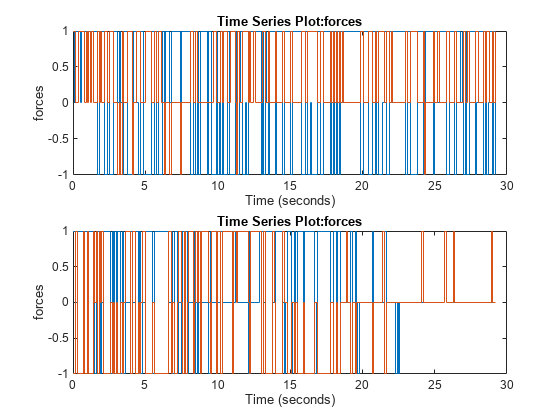
Simulate the agents against the environment, saving the experiences inxpr。
XPR = SIM(Env,[Agenta AgentB]);
Plot actions of both agents.
次要情节(2,1,1);情节(xpr (1) .Action.forces)次要情节(2,1,2); plot(xpr(2).Action.forces)