fitSVMPosterior
合适的后验概率
语法
描述
ScoreSVMModel= fitSVMPosterior (SVMModel)ScoreSVMModel,它是一个经过训练的支持向量机(SVM)分类金宝app器,包含用于两类学习的最优得分-后验概率变换函数。
该软件使用支持向量机分类器拟合适当的得分-后验概率转换函数SVMModel,并使用存储的预测数据进行交叉验证(SVMModel。X)和类标签(SVMModel。Y).变换函数计算观察被归入正类的后验概率(SVMModel.Classnames (2)).
ScoreSVMModel= fitSVMPosterior (SVMModel,TBL,ResponseVarName)SVMModel这个年代的tware estimates the score transformation function using predictor data in the tableTBL和类标签资源描述。ResponseVarName.
ScoreSVMModel= fitSVMPosterior (SVMModel,TBL,Y)SVMModel这个年代的tware estimates the score transformation function using predictor data in the tableTBL和类标签Y.
ScoreSVMModel= fitSVMPosterior (SVMModel,X,Y)SVMModel这个年代的tware estimates the score transformation function using predictor dataX和类标签Y.
ScoreSVMModel= fitSVMPosterior (<年代pan class="argument_placeholder">___名称,值)使用一个或多个指定的附加选项名称,值对参数提供SVMModel是一个分类VM分类器。例如,您可以指定要使用的折叠数k倍交叉验证。
[)另外返回转换函数参数(ScoreSVMModel,ScoreTransform]=fitSVMPosterior(<年代pan class="argument_placeholder">___ScoreTransform),使用前面语法中的任何输入参数。
例子
拟合可分离类的得分-后验概率函数
载入费雪的虹膜数据集。使用花瓣的长度和宽度训练分类器,并从数据中去除弗吉尼亚的物种。
负载<年代pan style="color:#A020F0">fisheririsclassKeep = ~ strcmp(物种,<年代pan style="color:#A020F0">“维吉尼亚”);X =量(classKeep 3:4);y =物种(classKeep);gscatter (X (: 1) X (:, 2), y);标题(<年代pan style="color:#A020F0">“虹膜测量散点图”)包含(<年代pan style="color:#A020F0">“花瓣长度”) ylabel (<年代pan style="color:#A020F0">“花瓣宽度”)传说(<年代pan style="color:#A020F0">“Setosa”,<年代pan style="color:#A020F0">“多色的”)
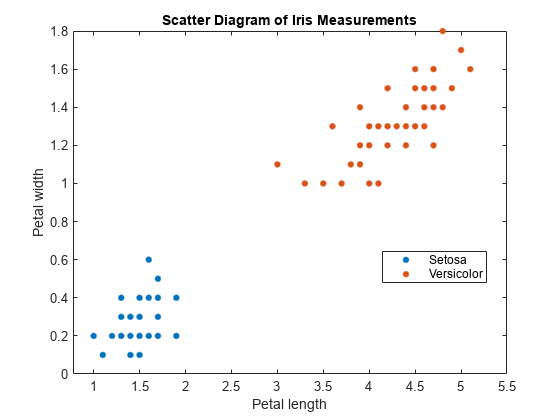
这些类是完全可分离的。因此,分数变换函数是一个阶梯函数。
使用数据训练SVM分类器。使用10倍交叉验证(默认)交叉验证分类器。
rng (1);CVSVMModel = fitcsvm (X, y,<年代pan style="color:#A020F0">“CrossVal”,<年代pan style="color:#A020F0">“上”);
CVSVMModel是一个培训ClassificationPartitionedModel支持向量机分类器。
估计将分数转换为后验概率的阶跃函数。
[ScoreCVSVMModel, ScoreParameters] = fitSVMPosterior (CVSVMModel);
警告:类是完全分离的。后验变换的最佳分数是阶跃函数。
fitSVMPosterior以下:
使用软件存储的数据
CVSVMModel来拟合变换函数当类可分离时发出警告
将阶跃函数存储在
ScoreCSVMModel。ScoreTransform
显示分数函数类型及其参数值。
ScoreParameters
ScoreParameters =<年代pan class="emphasis">结构体字段:类型:'step' LowerBound: -0.8431 UpperBound: 0.6897 PositiveClassProbability: 0.5000
ScoreParameters是一个有四个字段的结构数组:
分数转换函数类型(
类型)与负类边界对应的分数(
下界)对应于正向类边界的分数(
UpperBound)正类概率(
PositiveClassProbability)
由于类是可分离的,所以阶跃函数将分数转换为任意一个0或1,即观察到的是花斑虹膜的后验概率。
拟合不可分类的得分-后验概率函数
加载电离层数据集。
负载<年代pan style="color:#A020F0">电离层
这个数据集的类是不可分离的。
训练SVM分类器。交叉验证使用10倍交叉验证(默认)。标准化预测器并指定类顺序是一种良好的实践。
rng (1)<年代pan style="color:#228B22">%为了再现性CVSVMModel = fitcsvm (X, Y,<年代pan style="color:#A020F0">“类名”, {<年代pan style="color:#A020F0">“b”,<年代pan style="color:#A020F0">‘g’},<年代pan style="color:#A020F0">“标准化”,真的,<年代pan style="color:#0000FF">...“CrossVal”,<年代pan style="color:#A020F0">“上”);ScoreTransform = CVSVMModel。ScoreTransform
ScoreTransform = '没有'
CVSVMModel是一个培训ClassificationPartitionedModel支持向量机分类器。积极类是‘g’这个ScoreTransform财产是没有一个.
估计最优评分函数映射的观察评分后验概率的观察被分类为‘g’.
[ScoreCVSVMModel, ScoreParameters] = fitSVMPosterior (CVSVMModel);ScoreTransform = ScoreCVSVMModel。ScoreTransform
ScoreTransform = ' @ (S)乙状结肠(e-01 e-01年代,-9.482010,-1.218471)的
ScoreParameters
ScoreParameters =<年代pan class="emphasis">结构体字段:类型:'sigmoid'斜率:-0.9482截距:-0.1218
ScoreTransform是最优分数变换函数。ScoreParameters包含分数变换函数、斜率估计和截距估计。
您可以通过传递来估计测试样本的后验概率ScoreCVSVMModel来kfoldPredict.
估计测试样本的后验概率
估计支持向量机算法测试集的正类后验概率。
加载电离层数据集。
负载<年代pan style="color:#A020F0">电离层
训练SVM分类器。指定20%的抵抗层样本。标准化预测器并指定类顺序是一种良好的实践。
rng (1)<年代pan style="color:#228B22">%为了再现性CVSVMModel = fitcsvm (X, Y,<年代pan style="color:#A020F0">“坚持”, 0.2,<年代pan style="color:#A020F0">“标准化”,真的,<年代pan style="color:#0000FF">...“类名”, {<年代pan style="color:#A020F0">“b”,<年代pan style="color:#A020F0">‘g’});
CVSVMModel是一个培训ClassificationPartitionedModel交叉验证分类器。
估计最优评分函数映射的观察评分后验概率的观察被分类为‘g’.
ScoreCVSVMModel = fitSVMPosterior (CVSVMModel);
ScoreSVMModel是一个培训ClassificationPartitionedModel交叉验证分类器包含从训练数据估计的最优分数转换函数。
估计样本外正类后验概率。显示前10个样本外观察的结果。
[~, OOSPostProbs] = kfoldPredict (ScoreCVSVMModel);indx = ~ isnan (OOSPostProbs (:, 2));hoObs =找到(indx);<年代pan style="color:#228B22">%抵抗观察数字OOSPostProbs=[hoObs,OOSPostProbs(indx,2)];表(OOSPostProbs(1:10,1),OOSPostProbs(1:10,2),<年代pan style="color:#0000FF">...“VariableNames”, {<年代pan style="color:#A020F0">“ObservationIndex”,<年代pan style="color:#A020F0">“PosteriorProbability”})
ans =<年代pan class="emphasis">10×2表ObservationIndex PosteriorProbability ________________ ____________________ 6 0.17379 7 0.89639 8 0.0076634 9 0.91603 16 0.02672 22 4.6091e-06 23 0.9024 24 2.4127e-06 38 0.00042696 41 0.86429
输入参数
输出参数
更多关于
提示
这个过程描述了一种预测正类后验概率的方法。
通过传递数据来训练SVM分类器
fitcsvm这个result is a trained SVM classifier, such asSVMModel,用来存储数据。软件设置分数变换函数属性(SVMModel.ScoreTransformation)没有一个.通过训练的SVM分类器
SVMModel来fitSVMPosterior或fitPosterior.结果,例如,ScoreSVMModel,与训练的SVM分类器相同SVMModel,除了软件集ScoreSVMModel。ScoreTransformation到最优分数变换函数。通过预测器数据矩阵和包含最优分数变换函数的训练SVM分类器(
ScoreSVMModel)预测这个年代econd column in the second output argument of预测存储与预测数据矩阵的每一行对应的正类后验概率。如果你跳过第二步,那么
预测返回正的类别得分,而不是正的类别后验概率。
在拟合后验概率之后,您可以生成C/ c++代码来预测新数据的标签。生成C/ c++代码需要<年代pan class="entity">MATLAB<年代up>®编码器™. 有关详细信息,请参阅代码生成简介.
算法
如果您将分数重新估计为后验概率变换函数,也就是说,如果您将SVM分类器传递给fitPosterior或fitSVMPosterior和它的ScoreTransform属性是不没有一个,则软件:
显示警告
将原来的转换函数重置为
“没有”在估计新的之前
工具书类
[1] Platt, J. <支持向量机的概率输出和与正则似然方法的比较>。金宝app:大裕度分类器的进展.麻省理工学院出版社,2000年,61-74页。
另请参阅
分类VM|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">CompactClassificationSVM|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">ClassificationPartitionedModel|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">fitcsvm|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">预测|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">fitPosterior|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">fitPosterior|<年代pan itemscope itemtype="//www.tatmou.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">kfoldPredict
选择网站
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:<年代trong class="recommended-country">.
选择<年代pan class="recommended-country">网站你也可以从以下列表中选择一个网站:
