重采样数据
Bootstrap重新采样
引导过程包括从数据集中选择随机样本进行替换,并以相同的方式分析每个样本。置换抽样是指从原始数据集中分别随机选择每个观测数据。因此,原始数据集中的一个特定数据点可能在一个给定的bootstrap样本中出现多次。每个bootstrap样本中的元素个数等于原始数据集中的元素个数。您获得的样本估计范围使您能够确定您正在估计的数量的不确定性。
这个来自Efron和Tibshirani的例子比较了15所法学院的法学院入学考试(LSAT)分数和随后的法学院平均绩点(GPA)。
负载lawdata情节(考试成绩,'+')LSLine.
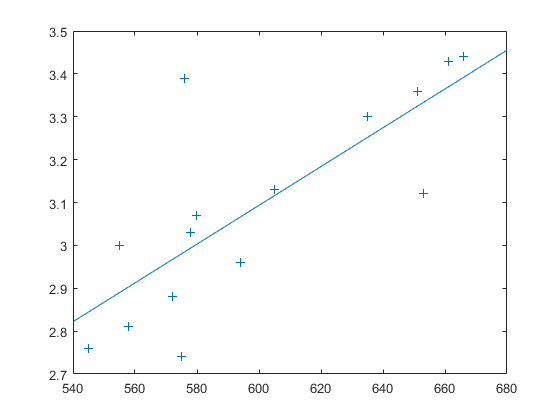
最小二乘拟合线表明,法学院的平均绩点越高,法学院的LSAT分数越高。但是这个结论有多确定呢?情节提供了一些直觉,但没有定量。
您可以使用| erc |计算变量的相关系数。
Rhohat = Corr(LSAT,GPA)
rhohat = 0.7764
现在你有了一个数字来描述LSAT和GPA之间的正联系;虽然它看起来很大,但你仍然不知道它是否具有统计学意义。
使用bootstrp功能您可以重新斥护LSAT.和平均绩点向量的次数不限,并考虑由此产生的相关系数的变化。
RNG.默认的重复性的%RHOS1000 = BOOTSTRP(1000,“相关系数”考试,gpa);
这是一个重建的LSAT.和平均绩点向量1000次,然后计算corr每个样本上的功能。然后,您可以在直方图中绘制结果。
直方图(RHOS1000,30,“FaceColor”,(。8。8 1])
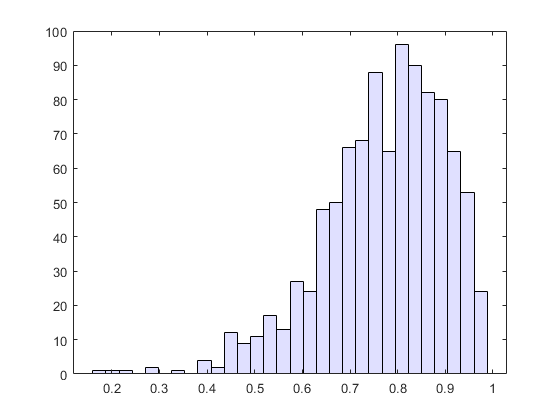
几乎所有估算都在间隔[0.4 1.0]上。
在统计推断中,为参数估计构造一个置信区间往往是可取的。使用Bootci.函数的置信区间,您可以使用引导来获得LSAT.和平均绩点数据。
ci = bootci(5000,@ corr,lsat,gpa)
ci =2×10.3319 - 0.9427
因此,LSAT与GPA的相关系数的95%置信区间为[0.33 0.94]。这是一个有力的定量证据,证明LSAT和之后的GPA是正相关的。此外,这一证据不需要对相关系数的概率分布做任何强有力的假设。
虽然Bootci.功能计算偏置校正和加速(BCA)间隔作为默认类型,它还能够计算各种其他类型的引导置信间隔,例如学生化的引导置信区间。
jackknife ruspling.
与自助法类似的是折刀法,它使用重新采样来估计样本统计量的偏差。有时也用于估计样本统计量的标准误差。折叠刀是由统计和机器学习工具箱™功能实现的重叠。
叠刀系统地重新取样,而不是像引导程序那样随机取样。对于带有n点,jackknife计算样本统计数据n单独的大小样本n1。每一个样本都是原始数据,省略了一次观察。
在bootstrap示例中,您测量了估计相关系数时的不确定性。您可以使用折叠刀来估计偏差,即样本相关性高估或低估真实的、未知的相关性的倾向。首先计算数据上的样本相关性。
负载lawdataRhohat = Corr(LSAT,GPA)
rhohat = 0.7764
接下来计算Jackknife样本的相关性,并计算其平均值。
RNG.默认的;重复性的%jackrho =重叠(@corr,考试,gpa);meanrho =意味着(jackrho)
meanrho = 0.7759
现在计算偏差的估计值。
n =长度(LSAT);biasrho =(n-1)*(Meanrho-Rhohat)
biasrho = -0.0065
样本相关性可能低估了真实的相关性。
并行计算支持重采样方法金宝app
有关并行计算重采样统计信息的信息,请参阅并行计算工具箱™。
您还可以从以下列表中选择一个网站:
