监督学习算法既接受已知的输入数据集,也接受相应的输出数据集。然后,它训练一个模型将输入映射到输出,这样它就可以预测对任何新的输入数据集的响应。
正如我们前面讨论过的,所有监督学习技术都采用分类或回归的形式。
分类技术可以预测离散响应。如果您想要预测的输出可以分成不同的组,那么可以使用这些技术。
分类问题的例子包括医学成像、语音识别和信用评分。
另一方面,回归技术预测连续的响应。
一个很好的例子就是你所预测的输出可以在一定范围内取任意值的任何应用,比如股票价格和声音信号处理。
现在,假设你有一个想要解决的分类问题。让我们简要地看看几个可以使用的分类算法。
逻辑回归算法是最简单的算法之一。它用于二分类问题,意思是只有两种可能输出的问题。当数据可以被单一的线性边界很好地分开时,它的工作效果最好。您还可以将其作为基线,与更复杂的分类方法进行比较。
袋装决策树和增强决策树将预测能力较弱的单个决策树组合成具有更强预测能力的许多树的集合。
当预测器是离散的或非线性的,以及您有更多的时间来训练模型时,最好使用它。
记住,还有很多其他的分类算法;这只是其中最常见的两种。
如果你有一个回归问题,也有很多算法可供选择。
线性回归是一种统计建模技术。当您需要一个易于解释和快速适应的算法,或者作为评估其他更复杂的回归模型的基线时,可以使用它。
非线性回归有助于描述数据中更复杂的关系。当数据具有很强的非线性趋势,不能轻易转化为线性空间时,可以使用它。
再次强调,这只是两种常见的回归算法供你选择;还有很多你可能需要考虑的。
现在让我们把所有这些放在一起,看看这个过程在现实世界中可能是什么样子。
假设你是一家塑料生产厂的工程师。工厂有900名工人,一年365天,每天24小时工作。
要确保在机器故障发生之前捕获它们,您需要开发一个运行状况监视和预测性维护应用程序,该应用程序使用先进的机器学习算法对潜在问题进行分类。
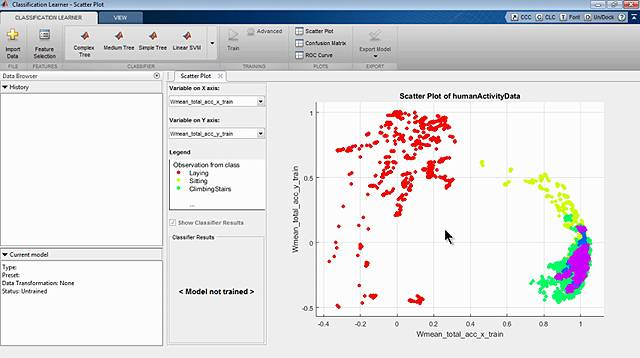
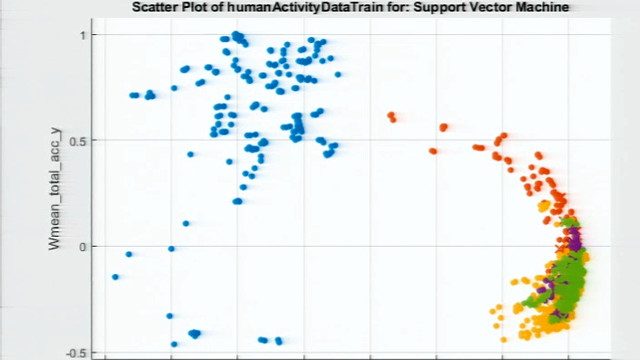
在从工厂的机器中收集、清洗和记录数据之后,您的团队评估了几种分类技术。对于每一种技术,团队都会使用机器数据训练一个分类模型,然后测试模型预测机器是否会出现问题的能力。
测试结果表明,套袋决策树的集成是最准确的。因此,这就是您的团队在开发预测性维护应用程序时所要做的事情。
除了尝试不同类型的模型之外,还有许多方法可以进一步提高模型的预测能力。让我们简单谈谈其中的三种方法……
第一种是特征选择,即从提供最佳预测能力的数据中识别最相关的输入。记住:一个模型的好坏取决于你用来训练它的特性。
第二,特征变换是降维的一种形式,我们在之前的视频中讨论过。以下是3种最常用的技术。
通过特征转换,您可以减少数据的复杂性,从而使其更容易表示和分析。
超参数调优是提高模型精度的第三种方法。这是一个迭代的过程,你的目标是找到训练模型的最佳设置。您可以使用不同的设置多次重新训练模型,直到您发现可以产生最精确的模型的设置组合。
这就是一个监督学习的简单介绍。在我们的下一个视频中,我们将深入了解一个机器学习工作流的例子。
在那之前,请务必查看下面的描述以获取更多有用的机器学习资源和链接。谢谢收看。