你好,每个人。我叫Graham Dudgeon,是MathWorks电气技术的主要产品经理。今天和我一起的是帕特里斯·布鲁内尔,她是魁北克水电研究所IREQ的首席科学家。嗨,帕特里斯。你好吗,我的朋友?
我过得很好。谢谢,格雷厄姆。我很高兴今天能和你聊天。
在这次演讲中,我和Patrice将讨论如何使用系统模拟和机器学习来开发算法,利用电压跌落测量来检测电网故障的位置。Patrice将为我们介绍一些故障定位检测的背景知识,我们将讨论Hydro-Quebec公司在这一领域的一些举措。然后,Patrice将描述正在研究的系统,并讨论如何配置仿真模型以在多个位置生成故障数据。
然后,帕特里斯树将返回给我,我将讨论使用分类学习者,这是统计和机器学习工具箱的一部分,可以训练和评估机器学习算法。接下来,我将看一下分类算法的结果可以帮助指导我们提出关于改善整体结果所需的额外测量的建议。然后,我将探索减少数据集如何影响分类算法的准确性。这有助于提供有关提供准确分类所需数据的指导以及如果我们通过减少数据集进行培训,可能存在哪些限制。然后我们将以摘要结尾。
我想从设置故障定位检测背后的一些上下文开始。显然,能够准确地确定故障的位置具有很高的操作价值。有了精确的位置,系统操作员可以采取明确的行动,维护人员可以更有效地调度。Hydro-Quebec在开发先进的故障定位和基于条件的维护能力方面有着悠久的历史。
MILES项目就是一个例子。MILES,代表对线路的维护和调查。利用MILES,可以在关键位置进行电压测量,并开发了一种对数,仅根据这些测量值就可以对故障位置进行三角测量。我们在右边看到的图像是MILES故障定位器的一个例子,用来估计实际的故障。
MILES算法基于电力系统工程理论。与世界各地的许多公用事业公司一样,魁北克水电公司正在探索机器学习在哪些方面可以提供互补能力,并增强运营监控。这就是为什么我们激动地用MathWorks在一个代表性问题上探索这种能力。
所研究的系统为辐射状配电网,是MILES项目中具有代表性的系统。仿真结果在实际系统中得到了验证。所以我们有很高的信心模拟的故障响应将代表实际的响应。
在本研究中,有5个电压测量位置用绿色表示。我们选择了38个不同的位置来应用错误。对于每个伏特位置,我们使用288相和中性电阻的组合。这样做是为了生成超过10,000个故障场景,特别是38个故障位置,每个位置有288个场景——在超过10,000个场景中生成。
为什么我们要设定如此多的场景?对于机器学习来说,通常数据越多越好。1万似乎是个合理的目标。当然,如果需要的话,我们可以生产更多。
我还应该指出,我们生成了正常数据,这意味着数据来自没有应用故障的模拟。我们只改变负荷值,使用每个负荷的正态分布。现在我将切换到MATLAB来展示我们用来生成仿真数据的模型和脚本。
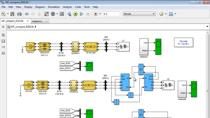
让我们首先看看我们在Simscape Electrical的专门电力系统中开发的仿真模型。配电网通过电网与配电变压器相连。这是一条超过15公里的三相线路,我把它分成三部分,每部分5公里,还有一个两相分支。
所以我标记了所有的方块,L1, L2, L3和L4。还有一些单相配电馈线连接到网络上。我有6个。我把L1标记为第一阶段。我们还有一个母线来测量模型中五个位置的电压和电流。它们被标记为B1 B2 B3 B4。我们在这里收集所有的信号。对于每一次折叠,我们都要测量它的正、负和零序列。我们在一个输出中收集所有的信号。
让我们快速看看三个阶段系统。你看到我用这个街区将其分成1公里的部分。而这就是我们指定了行参数的地方。这让我可以访问该行中的五个或六个点。所以我能在那里造成错误。
目的是有故障块,我可以为各种故障类型和故障阻抗编程。我将能够设置这个块,然后脚本将沿着这条线在我们之前看到的所有位置移动它。它将允许我在我之前提到的38个位置应用错误。当然,这同样适用于单相线。
现在,让我们看看用来生成模拟数据的脚本。全屏显示。我们开始吧。
在这里我指定了通用的通用参数,在这里我定义了错误的类型。现在,我将只编程一个AB接地故障与专用参数。在这里,我列出了模型中所有的10行代码,在这些代码中,我将使用稍后使用的特殊标签应用错误。
在这里,我们可以指定直线。在这个模拟中,假设只有1和5。所以单相线和两相线,给你们展示一下原理。在此之后,对于列表中的每一行,我们将向其添加整个块。我会坐着看的,根据如果我们做一个三相或单相故障我已经转发给相应设置块如果我们沿着每个部分每一个插入点我会强硬路线所以我连接的完整块位置我想违约,并为每个照片的位置我错误阶段和r中性值。
这就给了我很多错误——典型的错误——对于这种错位。那么在下一步,让我们看看。这里,我们来模拟一个,给你们演示一下原理。在模拟中我们会加快速度。然后下一步就是启动模拟。并在仿真后,将仿真后的数据保存在一个表格中,这样就可以在仿真后使用了。
现在,让我们开始。哦,停了。让我们继续。您应该看到在这个子系统中出现了完整的块。这是L1线。我们开始吧。它连接到第一个点,我想从折叠中配对。模型是编译,模拟,然后我将进入下一节,做相同的设置,应用折叠,收集提交数据等等。我让它在剩下的线路上运行。
我们现在开始第4次提交。一旦我们完成L1线,就会自动关闭它,然后打开单相线。同样的事情在这里。我在做add block,我在第一个位置应用错误,然后模拟,得到结果,然后去下一个。
还有两个模拟,这一个和最后一个。好的。现在让我们转到MATLAB命令。可以在这里看到,故障定位和生成的数据表。
让我们在模拟结果中快速忽略。例如,我做的第一个是总线B1上的第一个故障,年ID ABC相位幅度,只是向您展示我计算和获取的序列参数。看到我在同一个公共汽车上做的最后一个模拟。
现在让我们回到Graham,他将讨论如何使用机器学习工具。
谢谢,帕特里斯。因此,一旦生成了故障数据,我们就会在Matlab表中组织它。该表包括每个总线电压测量的序列数据以及故障分类。我们在这里看到的示例仅显示了一些数据点,以用于说明目的。我们已经加上一个序列数据,幅度和角度以及故障分类。
对于本例,我们为超过10,000个场景生成了数据。分类学习器是一个用户界面,带有机器学习工具箱中的统计数据。我一会儿会打开分类学习者,我可以向你们展示它的一些功能。我要注意的是,我不会给出一个全面的概述,所以在我展示的内容之后,如果您想要更多的信息,我鼓励您参考文档。
我要做的第一件事是加载数据集并调用Classification Learner。我在这里使用项目,所以我可以组织我的文件和创建快捷方式,以帮助我更好地管理我的工作流程。我要点击获取origin训练数据。这将加载数据,然后调用分类学习器。
如果您想要有关项目的更多信息,请参阅文档。我只会将分类学习者扩展到全屏。
在Classification Learner中,我首先启动一个新的会话并从工作区加载数据。在这个例子中,我的数据在MATLAB表格中。现在,它是工作空间中唯一的变量,所以它会自动选中这个。如果您的工作区中有多个数据集变量,您将选择。在这个例子中,我不需要这么做。您将看到数据已经被自动传递,默认列基本上是分类的,有39个惟一分类。我要提醒大家的是,我们有38个故障点,还有一个正常的分类。
因为它本质上是分类的,分类学习器自动地把错误作为响应数据。数据表T中的其他变量被选为预测变量。现在,当然,你可以控制。如果分类no没有找到正确的信息,你可以适当地选择,但在这种情况下,他确切地知道我想做什么。
现在我们要做的是选择要对验证做什么。有两种选择——交叉验证(交叉验证使用统计方法将数据分离为训练和测试集)或hold-out验证(hold-out验证将留出一定比例的数据用于测试,然后使用剩余的数据进行修剪)。
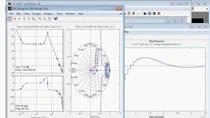
我们将坚持使用默认设置,这是使用具有五个故障的交叉验证。然后我们单击“开始”会话。您可以看到我们默认为散点图,在这种情况下,这在这种情况下显示了正序列的总线1电压幅度。实际上是负序列的总线1电压幅度。
我想在这里提出几点看法。首先,正常的操作,没有应用错误,但我们改变负载值,它看起来非常干净。实际上是右下角的这一小块区域。如果我向下滚动我们的课程到正常。是红色的那个。如果我悬停。然后我们会得到一些关于选定的数据点的信息。你可以看到这里,班级正常。
所以我们可以看到正常行为非常干净,因为我们有一个紧密的分布,我们没有看到任何故障,条件的任何故障。在这种情况下,我们希望正常运行易于分类。第二个观察是,虽然我们可以在故障数据上看到模式,但我们还看到了数据点的重叠,这意味着通过传统工程分析的分类将具有挑战性。
现在让我们将这些数据展示给机器学习算法,看看我们能取得什么成果。我总是从选择所有的快速训练开始。它会选择一些机器学习算法,对于我所展示的数据,这些算法会在相对较快的时间内进行训练。如果我选择train,如果你安装了parallel Computing Toolbox,这将自动调用一个并行池,这将允许训练算法从多个核中受益。
现在我们可以看到在训练过程中有很多不同的算法。所以我们只让其中一些通过。正如你所看到的,当他们完成的时候,精确度就会提高。最好的模型会被白盒突出显示。所以现在我们的准确率是67.9%。我们让它再运行一点,我们可以做得更好。优良kNN为75.9%,中等kNN为80.6。这很好。所以我们能做的是,当其他人还在等待训练结束的时候这是我们目前为止最好的一次。
那么80.6%是什么意思呢?为了更深入地了解这个数字,我们可以查看混淆矩阵。我们在这里选择混淆矩阵。混淆矩阵向我们展示了训练数据如何在训练的分类器上执行。我们看到我们有真实类和预测类。如果我们有一个完美的分类器,我们将只看到这个矩阵的对角项,我们也会对结果有一点怀疑。
完美的分类训练数据,命名你的开销分类算法或你有一些数据质量问题。在这种情况下,我们可以看到,我们有一些地方我们有一个独特的非对角的模式,分类,观察与培训相关的数据集,我们可以看到,这里有大量相关的L1 PH3和L1 PH2,这里也和L1 PH5 L1 PH5。因此,分类器很难区分L1 PH2和L1 PH3上的错误,也很难区分L1 PH4和L1 PH5上的默认错误。
这个问题迫使我们回到物理系统,并确定是否有物理特性导致了这个结果。让我们考虑一下系统发生了什么。我们所测量的电压都来自于分叉线的上游。叉线具有等效的电气特性。
这意味着,如果在分叉上发生错误,比如在这个示例中的位置F1的例子。然后用恶魔指示的电压测量,虽然可以检测到故障,但不能区分故障是否在位置。F1和F2。
让我们再看一遍系统模型,这样我就可以向你们展示这些分叉线。好的。所以我们有L1 PH2和L1 PH3的问题。如果我在L1 PH2下面,看到这里有四个线段。如果是L1 PH3,我们有两个片段。但是11的直线,nn,在这里。所以我们确实有一个叉子,它有相同的电特性。因此,这就是为什么我们在L1 PH2和L1 PH3的分类上有困难。
同样适用于L1 PH4和L1 PH5。在这个例子中,我们有相同的设置。所以我们只需要放大一些我们在困惑矩阵中遇到困难的地方。我们看到我们有了明显的非对角线分类,这是错误的,因为有分叉的线。那么我们能做些什么来改善这种情况呢?
一种解决方案是在叉的末端进行额外的电压测量。注意,一般情况下,我们需要y - 1额外的测量值,其中y是分叉的数量。所以在我们的系统中,有两个叉子时,我们只需要一个额外的测量。因此,我们更新了仿真模型,加入了额外的测量,在这种情况下,L1 PH2测量有助于区分L1 PH2和L1 PH3故障,L1 PH4测量有助于区分L1 PH4和L1 PH5折叠。
现在,我们将加载带有额外测量值的新数据集,并重新训练分类算法。我们没有对新数据集进行培训。现在,记住,上一次,当我们没有这些额外的测量,分叉的线路是一个问题,我们在所有快速训练的最好结果是80.6%。所以让我们顺其自然,看看我们能取得什么成果。
到目前为止,75%都在树上。我们再给它几秒钟让它训练一两个。91.9%。所以我们已经得到了更好的回应,但证据在布丁中。我们要看看混淆矩阵,看看我们是否在帮助解决我们遇到的特定问题。
让我选择细knn或余弦knn。它们具有相同的准确性。它们可能会略有不同的结果,但我只需选择一个来看看这里。我们会看看混乱的矩阵。
让我再试一次。我们实际上有三个结果相同。现在它选择了加权kNN。我选择它,然后看看混淆矩阵。
所以我们看不见-你们可能还记得我们有一个大得多的非对角分量当我们看L1 PH2和L1 PH3的时候。所以我们有了比以前更好的分类。所以对L1 PH2和L1 PH4的额外测量帮助我们达到了更高的精度。这也有助于建立我们的信心,即我们所看到的效果确实是由分叉线引起的。
我在这里再强调几点。我只用了快速训练。但是有了分类学习者,你可以使用更广泛的模型。你可能会想看看支持向量机。金宝app我通常使用二次支持向量机,因为我发现它们更准确。金宝app但是他们需要更长的时间来训练。所以我不会在这个演讲中训练它,因为它需要更长的时间。但通常你会看到更准确的。
另一点是当您有培训的模型时,可以按下导出型号,然后您可以选择模型的名称,只需单击“确定”。然后去Matlab工作区。所以你可以在这里看到我们在工作区中训练了模型,它也显示您必须在Matlab工作区中调用它。
在接下来的结果中,我要展示的是我使用MATLAB脚本来做到这一点。我不会展示MATLAB脚本,因为它们只是几行代码。我更愿意关注这次演讲的结果。但是我们可以为那些想要更仔细地了解这些工作流程的人提供脚本。
我们将知道仅使用边缘案例考虑培训。我们这样做的原因是让我们一些关于我们需要成功培训分类算法的数据类型的见解。特别是,我们可以在减少数据集中实现准确的结果吗?
有三种情况我们会考虑。首先,训练故障数据只能从第一行部分收集。其次,对故障数据的培训仅在最后一节上收集。第三,在第一节和最后一节上收集的故障数据训练。我们可以从这里显示的混淆矩阵从这里看出,我们在提供的数据上获得非常准确的结果。这是预期的。
问题是,当来自其他部分的错误数据通过这些模型时,分类器将如何响应?我们将看几行代码来探索这个特殊系统的情况。让我先介绍一下你们看到的混淆矩阵。让我们关注右边的结果,从第一部分开始训练。这意味着除了第1节之外,我们没有任何预测类。这就是为什么,如果你看这里的列,你会看到第2节,第3节和第4节,它们是空的。这是意料之中的,因为我们没有训练过这些。
有了这个,对角线上的结果是最好的,因为我们有那个场景的数据。如果我们用绿色的方框进行分类,那就意味着我们确定了正确的长度。例如,我们来看L1 PH4第2节。这是真正的类,没有训练第一部分的数据。它被鉴定为L1 PH4 section 1。这条线是一样的,所以是绿色方框。这是我们对没有训练过的部分所能做的最好的事情,至少是让它们按照正确的路线分类。
绿方框外的任何东西都表示我们没有确定正确的直线。所以我们可以看到,通过观察这三种不同的边的情况,我们并没有得到令人满意的结果。例如,L1 PH4的第1节上的故障行为没有包含足够的信息来推断L1 PH4可用的另一节上的故障可以被识别为属于该线。
这是另一个例子,L1 PH6。这一行只有两个部分,我们看到,在对最后一部分进行训练时,这里的中间响应产生了准确的结果,以识别正确的行。第一部分的训练不准确。所以当我们看这些结果和其他的结果,我没有在这里展示,我们得出结论,我们需要一个广泛的错误的场景,跨越每条线的部分,以便准确地分类故障位置。这可能并不奇怪,但剩下的问题是,我们需要在线段上的粒度级别达到可接受的精确度级别。
这个问题超出了本演示的范围,但是可以通过从仿真模型生成合成数据来探索。总之,这项研究的结果是令人鼓舞的。我们已经证明,分类机器学习算法可以以相对较高的精度对故障位置进行分类。我们看到分叉线对于上游测量是有问题的。因此,在这种情况下,我们建议在叉子的末端进行额外的测量。
通过这些额外的测量,我们能够在故障定位分类上获得更好的准确性。我们还看了对简化数据集的处理。我们发现,在这个例子中,只训练第一部分和最后一部分是不够的,以可接受的精度定位正确的线。这意味着,要有效地训练机器学习算法,需要大量的合成数据。