培训和验证
为了学习最优策略,强化学习代理通过反复的试错过程与环境交互。在培训期间,代理调整其策略表示的参数,以最大化长期回报。强化学习工具箱™ 软件为训练代理提供功能,并通过仿真验证训练结果。有关详细信息,请参阅培训强化学习代理.
应用程序
| 强化学习设计师 | 设计、培训和模拟强化学习代理 |
功能
阻碍
| RL试剂 | 强化学习代理 |
话题
培训和模拟基础
通过在指定环境中培训代理,找到最佳策略。
训练Q-learning和SARSA代理在MATLAB中求解网格世界®.
在一般马尔可夫决策过程环境中训练强化学习代理。
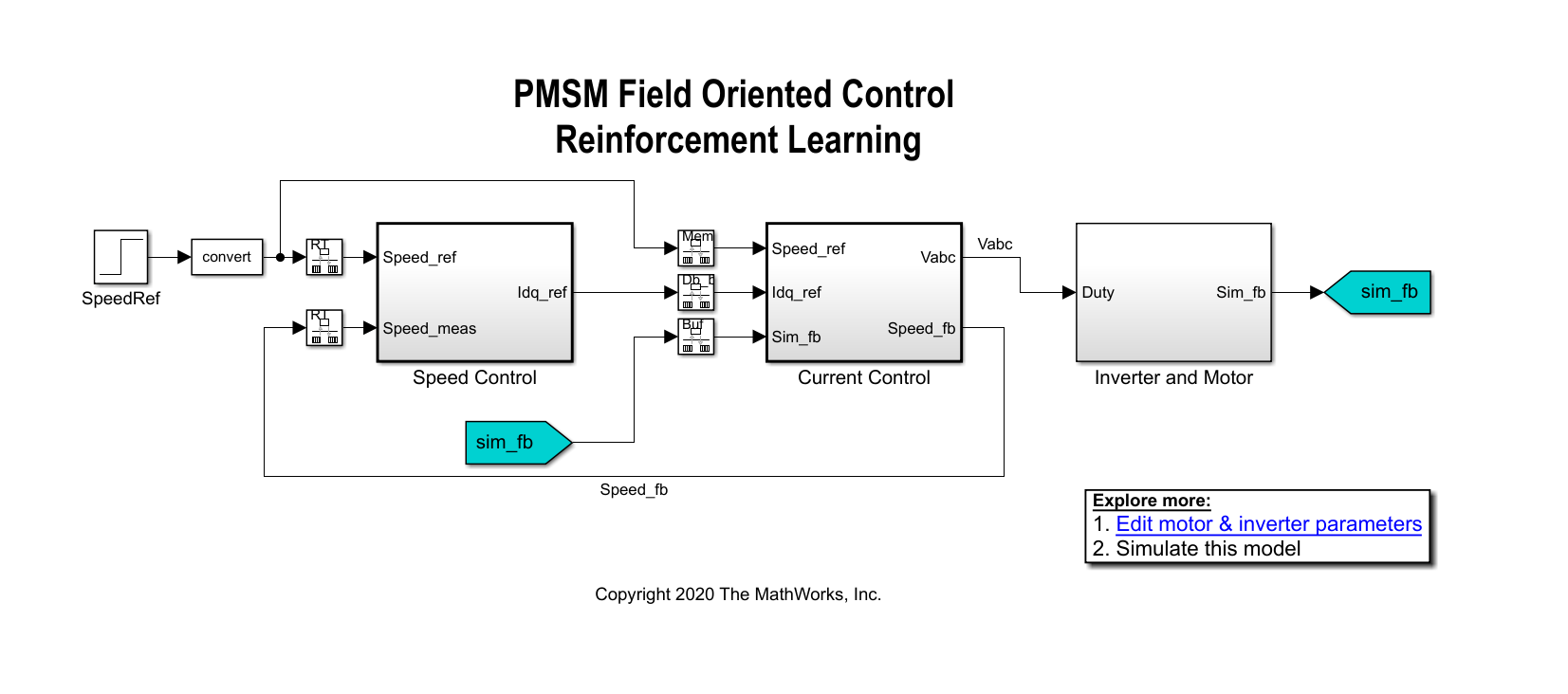
使用Simulink中建模的对象,使用强化学习训练控制器金宝app®作为培训环境。
使用强化学习设计器应用程序
使用强化学习设计器应用程序设计和培训推车杆系统的DQN代理。
以交互方式指定用于模拟强化学习代理的选项。
以交互方式指定培训强化学习代理的选项。
使用多进程和GPU
通过在多个核心、GPU、群集或云资源上并行运行模拟,加快代理培训。
使用异步并行计算训练actor-Critical agent。
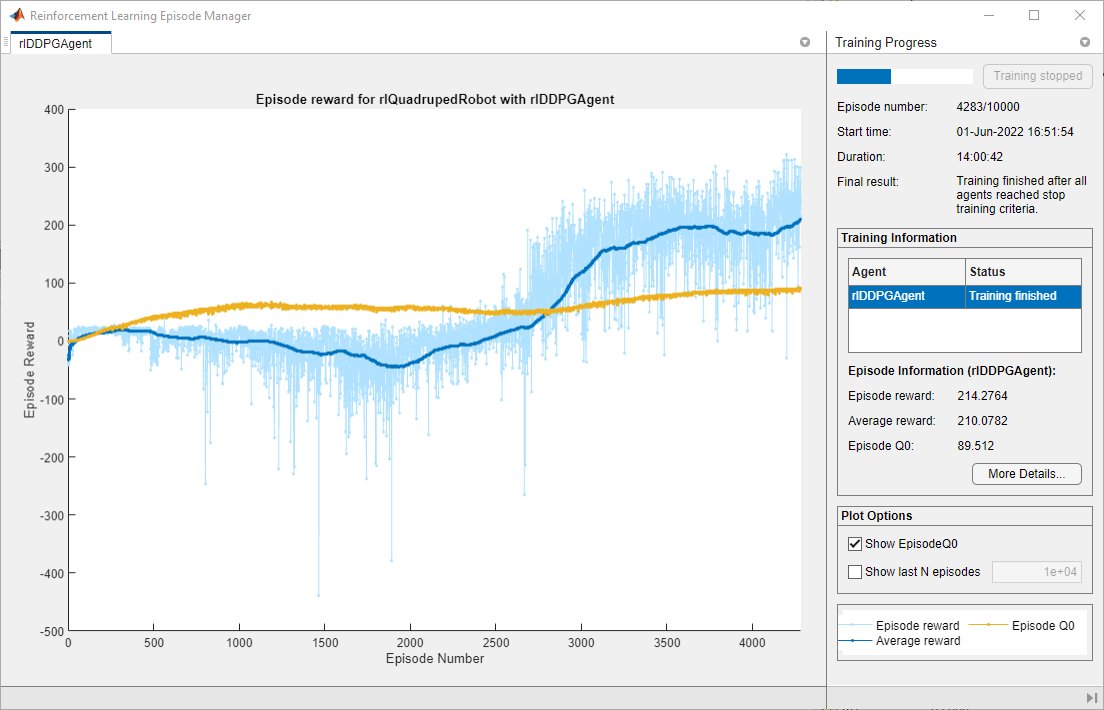
使用并行计算为自动驾驶应用程序培训强化学习代理。
培训代理MATLAB环境
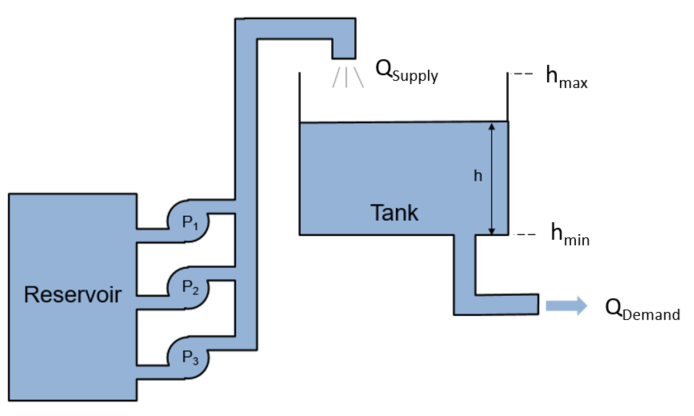
训练一个深度确定的策略梯度代理来控制在MATLAB中建模的二阶动态系统。
训练一个带有基线的策略梯度来控制在MATLAB中建模的双积分系统。
训练一个深度Q学习网络代理来平衡在MATLAB中建模的车杆系统。
训练策略梯度代理来平衡在MATLAB中建模的车杆系统。
训练一个演员-评论家代理来平衡在MATLAB中建模的车-杆系统。
使用基于图像的观察信号训练强化学习代理。
使用Deep learning工具箱中的Deep Network Designer应用程序创建强化学习代理™.
培训代理金宝app环境
训练深度Q网络代理来平衡Simulink中建模的钟摆。金宝app
训练一个深度确定的策略梯度代理来平衡Simulink中建模的钟摆。金宝app
训练强化学习代理来平衡包含总线信号观测值的摆锤Simulink模型。金宝app
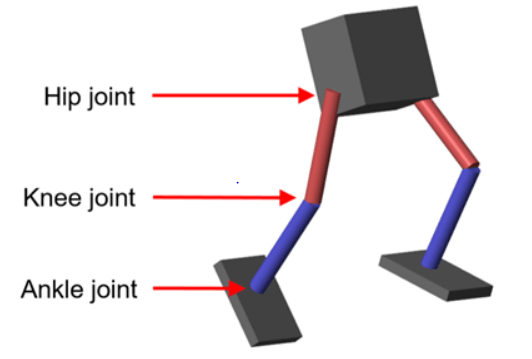
训练一个深度确定的策略梯度代理,使其能够在中建模的车杆系统上摆动和平衡Simscape™多体™.
多智能体训练
训练两个PPO代理协作移动对象。
培训三名PPO代理,以协作竞争的方式探索网格世界环境。
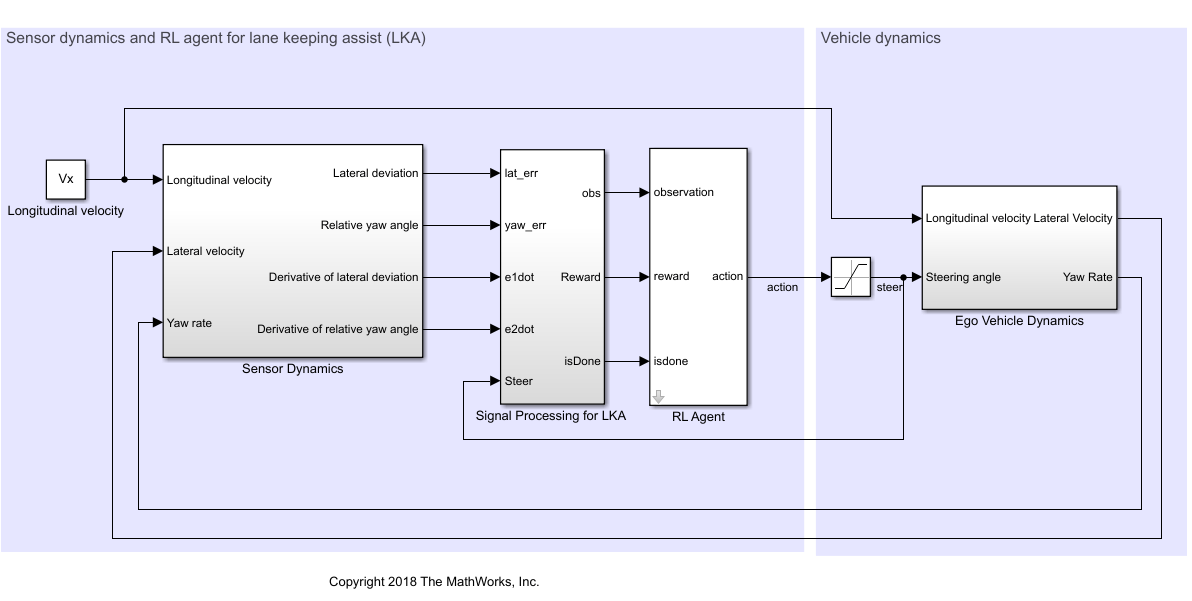
训练一个DQN和一个DDPG代理协同执行自适应巡航控制和车道保持辅助,以跟随路径。
模仿学习
在车道保持辅助系统中,训练深度神经网络来模拟模型预测控制器的行为。
训练一个深度神经网络来模拟飞行机器人的非线性模型预测控制器的行为。
使用参与者网络训练强化学习代理,该参与者网络之前已使用监督学习进行过训练。
定制代理和训练算法
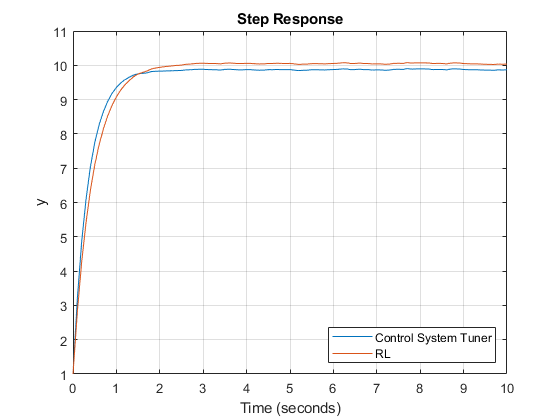
培训定制LQR代理。
使用您自己的自定义训练算法训练强化学习策略。
为自定义强化学习算法创建代理。
特色实例

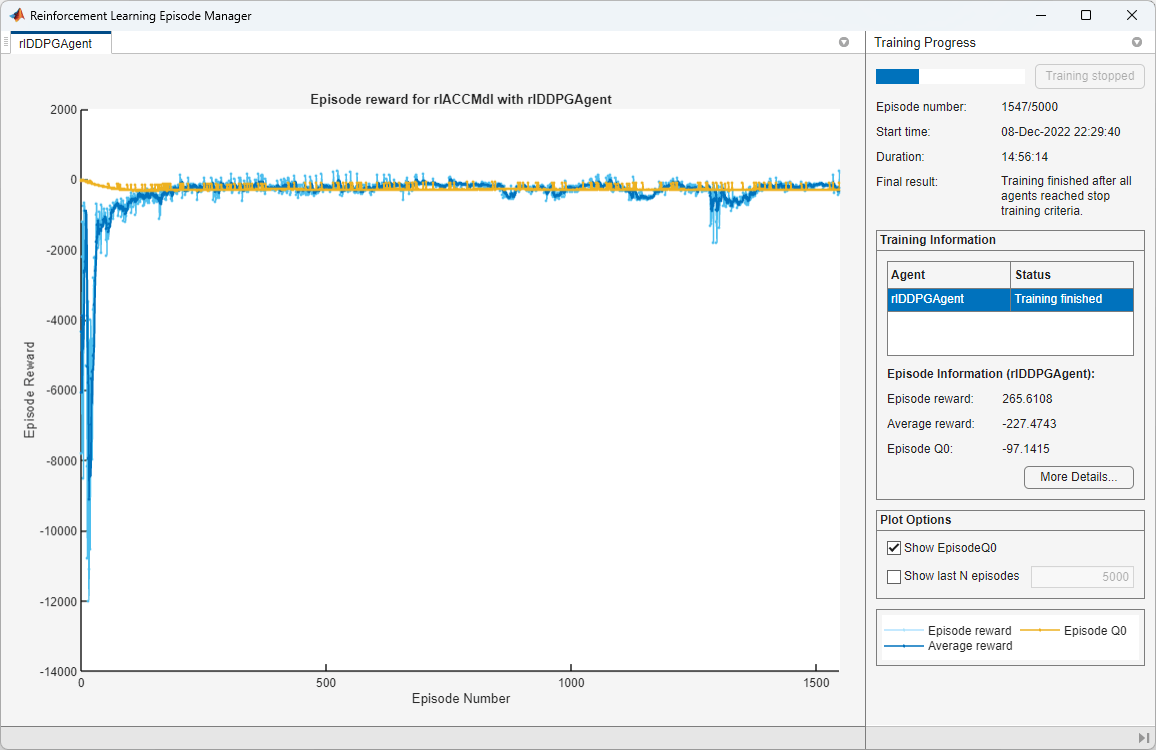
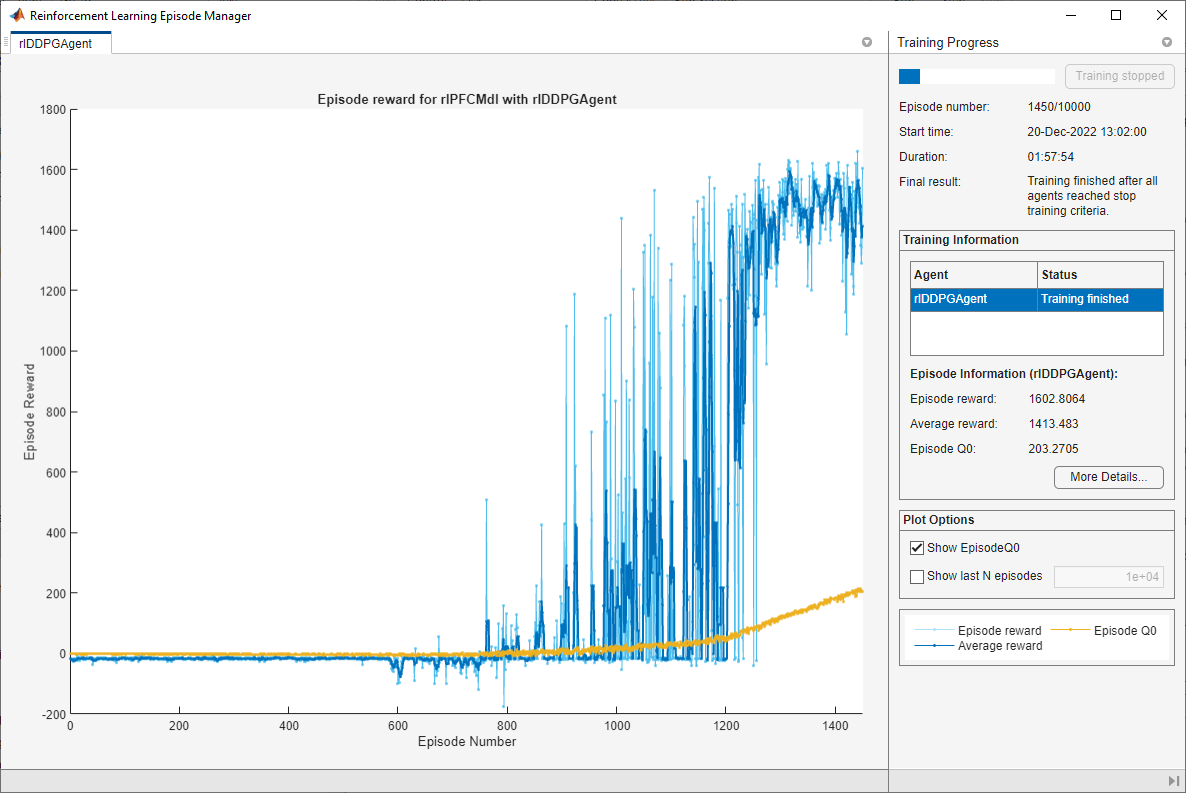
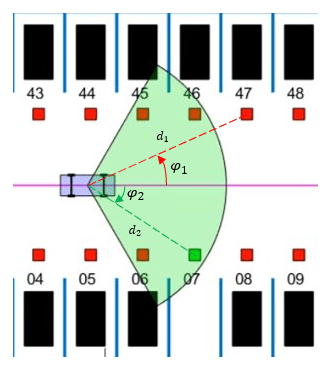
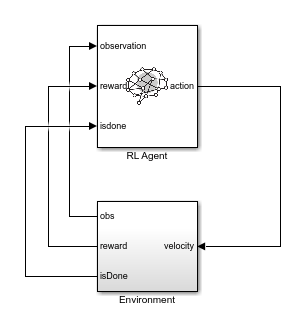
您还可以从以下列表中选择网站: