モデル关节を使使しネットワーク学习
この例では,層グラフまたはdlnetwork.ではなく関数を使用して深層学習ネットワークを作成し、学習させる方法を説明します。関数の使用には、幅広いネットワークを記述する柔軟性が得られるという利点があります。欠点は、より多くのステップを実行し、データを慎重に準備しなければならないことです。この例では、手書き数字のイメージと、数字を分類して垂直位置からの各数字の角度を判定する双対目的関数を使用します。
学习データの読み込み
関数Digittrain4daraydataはイメージとその数字ラベル,および垂直方向からの回転角度を読み込みます。イメージ,ラベル,角度についてarrayDatastoreオブジェクトを作成してから、関数结合クラスの学习て含む一のデータデータます。
[XTrain, YTrain anglesTrain] = digitTrain4DArrayData;dsXTrain = arrayDatastore (XTrain,“IterationDimension”,4);dsYTrain=arrayDatastore(YTrain);dsAnglesTrain=arrayDatastore(anglesTrain);dsTrain=combine(dsXTrain,dsYTrain,dsAnglesTrain);classNames=categories(YTrain);numClasses=numel(classNames);numResponses=size(anglesTrain,2);numObservations=numel(YTrain);
学習データからの一部のイメージを表示します。
idx=randperm(numObservations,64);I=imtile(XTrain(:,:,:,idx));图imshow(I)

深层学习モデルの定义
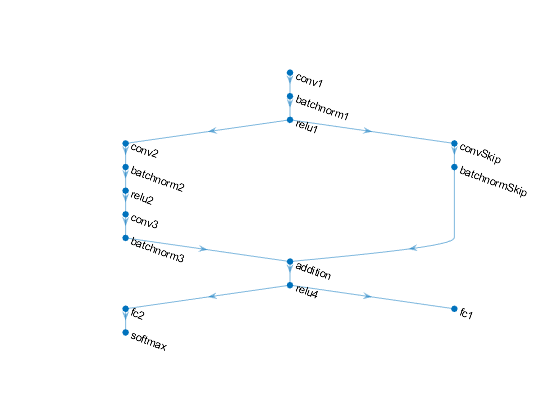
ラベルと回転角度の両方を予測する次のネットワークを定義します。
16個の5 x 5フィルターをもつconvolution-batchnorm-ReLUブロック
各ブロックに 32個の 3 x 3フィルターがあり、間に 雷卢演算をもつ、2.個の 卷积范数ブロックの分岐
32个个1 x 1の畳み込みをもつ卷积 - Batchnormブロックブロックのあるスキップ
加算とそれに続くReLU演算を使用した両方の分岐の組み合わせ
回帰出力用に、サイズが 1 (応答数) の全結合演算をもつ分岐
分享到援助用作に,サイズが10(クラス数)のの全合
モデルのパラメーターと状態の定義および初期化
各演算のパラメーターを定義して構造体に含めます。parameters.OperationName.ParameterNameの形式を使用します。ここで,参数は构造体,operationNameは演算名(conv1など),ParameterNameはパラメーター名(“权重”など)です。
モデルパラメーターを含む構造体参数を作物成し。附近initializeGlorotおよびinitializeZerosを使用して,学習可能な層の重みとバイアスをそれぞれ初期化します。サンプル関数initializeZerosおよびinitializeOnes[
バッチ正規化層を使用して学習や推論を実行するには,ネットワークの状態も管理しなければなりません。予測の前に,学習データから派生するデータセットの平均と分散を指定しなければなりません。状態パラメーターを含む構造体状态を作成します。バッチ正規化の統計値は、dlarrayオブジェクトにしないでください。関数0および那些を使用して、バッチ正規化の学習済み平均と学習済み分散の状態をそれぞれ初期化します。
この初期化サンプル関数は、この例にサポート ファイルとして添付されています。
最初の畳み込み層のパラメーターを初期化します。
filterSize = [5 5];numChannels = 1;numFilters = 16;sz = [filterSize numChannels numFilters];numOut = prod(filterSize) * numFilters;numIn = prod(filterSize) * numFilters;parameters.conv1。重量= initializeGlorot(深圳、numOut numIn);parameters.conv1。Bias = initializeZeros([numFilters 1]);
最初のバッチ正規化層のパラメーターと状態を初期化します。
parameters.batchnorm1.Offset=initializeZeros([numFilters 1]);parameters.batchnorm1.Scale=initializeons([numFilters 1]);state.batchnorm1.TrainedMean=零(numFilters,1,'单身的');state.batchnorm1.trountvariance = =那些(numfilters,1,'单身的');
2番目の畳み込み層のパラメーターを初期化します。
filterSize=[3];numChannels=16;numFilters=32;sz=[filterSize numChannels numFilters];numOut=prod(filterSize)*numFilters;nummin=prod(filterSize)*numFilters;parameters.conv2.Weights=initializeGlorot(sz,numOut,nummin);parameters.conv2.Bias=initializeZeros([numFilters 1]);
2番目のバッチ正規化層のパラメーターと状態を初期化します。
parameters.batchnorm2。Offset = initializeZeros([numFilters 1]);parameters.batchnorm2。Scale = initializeOnes([numFilters 1]);state.batchnorm2。TrainedMean = 0 (numFilters 1'单身的');state.batchnorm2。TrainedVariance = 1 (numFilters 1'单身的');
3番目の畳み込み层のパラメーターをををしし。
filtersize = [3 3];numchannels = 32;numfilters = 32;sz = [filterSize numChannels numFilters];numOut = prod(filterSize) * numFilters;numIn = prod(filterSize) * numFilters;参数.conv3.weights = initializeglorot(sz,numout,numin);参数.conv3.bias = initializezeros([numfilters 1]);
3番目のバッチ正析层パラメーターパラメーターパラメーターとと状态を
参数.batchnorm3.offset = initializezeros([numfilters 1]);parameters.batchnorm3.scale = initializeones([numfilters 1]);state.batchnorm3.troundmean =零(numfilters,1,'单身的');state.batchNormal3.TrainedVariance=个(numFilters,1,'单身的');
スキップ接続における畳み込み層のパラメーターを初期化します。
filtersize = [1 1];numchannels = 16;numfilters = 32;sz = [filterSize numChannels numFilters];numOut = prod(filterSize) * numFilters;numIn = prod(filterSize) * numFilters;parameters.convskip.weights = nigitizeglorot(sz,numout,numin);parameters.convskip.bias = nigitizezeros([numfilters 1]);
スキップ接続におけるバッチ正規化層のパラメーターと状態を初期化します。
parameters.batchnormSkip.Offset = initializeZeros([numFilters 1]);parameters.batchnormSkip.Scale = initializeOnes([numFilters 1]);state.batchnormSkip.TrainedMean = 0 ([numFilters 1],'单身的');state.batchnormSkip.TrainedVariance = ones([numFilters 1],'单身的');
分類出力に対応する全結合層のパラメーターを初期化します。
sz = [numClasses 6272]; / / / /numOut = numClasses;numIn = 6272;parameters.fc1。重量= initializeGlorot(深圳、numOut numIn);parameters.fc1。Bias = initializeZeros([numClasses 1]);
回帰回帰力に対応する全层层层をを层しますををしします。
sz = [numreponses 6272];numout = numreponses;numIn = 6272;参数.fc2.weights = initializeglorot(sz,numout,numin);参数.fc2.bias = initializezeros([numreponses 1]);
パラメーターの構造体を表示します。
参数
参数=结构体字段:conv1:[1×1结构]batchnorm1:[1×1结构]conv2:[1×1结构]batchnorm2:[1×1结构]conv3:[1×1结构]batchnorm3:[1×1结构]convSkip:[1×1结构]batchnormSkip:[1×1结构]fc1:[1×1结构]fc2:[1×1结构]
演算“conv1のパラメーターを表示します。
parameters.conv1
ans =结构体字段:重量:[5×5×1×16 dlarray]偏置:[16×1 dlarray]
状態の構造体を表示します。
状态
陈述=结构体字段:[1×1 struct] batchnorm2: [1×1 struct] batchnorm3: [1×1 struct] batchnormSkip: [1×1 struct]
演算“batchnorm1の状態パラメーターを表示します。
state.batchnorm1
ans =结构体字段:TrainedMean: [16×1 single] TrainedVariance: [16×1 single]
モデルの関数の定義
このこの例の最后最后にリストされて,前に说明した深层モデルモデルのの力模型を作成します。
関数模型は,モデルパラメーター参数,入力データdlX、モデルが学習と予測のどちらの出力を返すべきかを指定するフラグdoTraining,およびネットワークの状態状态をを受け取りますネットワーク予测はラベルの,角度の予测,および更新されたの状态ををします。
モデル勾配関数の定義
例の最後にリストされている関数modelGradientsを作成します。この関数は、モデルのパラメーター、ならびに入力データdlXののミニバッチととそれにするするT1およびT2(それぞれラベルと角度を含む)を受け取り,学校可なパラメーターについてのの勾配,更新されたの,および対応する损失を返し。
学習オプションの指定
学習オプションを指定します。ミニバッチ サイズを 128として 20エポック学習させます。
numEpochs=20;miniBatchSize=128;
学習の進行状況を監視するには,それぞれの反復の後で学習の損失をプロットできます。”“学習の進行状況を含む変数プロットを作成します。学習の進行状況をプロットしない場合は,この値を”没有“に設定します。
情节=“培训进度”;
モデルの学習
小型批处理队列を使用して、イメージのミニバッチを処理および管理します。各ミニバッチで次を行います。
カスタムミニバッチ前经理关节
preprocessMiniBatch(この例の最後に定義) を使用して、クラス ラベルを 一个热的符号化します。イメージデータを次元ラベル
'SSCB'(空间,空间,频道,批量)で书签设定设定し。既定既定で,小型批处理队列オブジェクトは、基となる型が仅有一个的のdlarrayオブジェクトオブジェクトデータををます。书籍ををクラスラベルラベルまたは角度に追ししないででGPUが利用できる場合、GPUで学習を行います。既定では、
小型批处理队列オブジェクトは,GPUが利用可致杂合,各各力をGPUARRAY.に変換します。GPUを使用するには,并行计算工具箱™とサポートされているGPUデバイスが必要です。サポートされているデバイスについては,リリース别のgpuサポート(并行计算工具箱)を参照してください。
MBQ = Minibatchqueue(Dstrain,...'迷你atchsize',小匹马,...“MiniBatchFcn”,@preprocessminibatch,...“MiniBatchFormat”,{'SSCB','',''});
各エポックについて、データをシャッフルしてデータのミニバッチをループで回します。反復が終了するたびに、学習の進行状況を表示します。各ミニバッチで次を行います。
関数
德尔费瓦尔およびmodelGradientsを使用してモデルの勾配と損失を評価。関数
adamupdateをを用してネットワークパラメーターパラメーター新。
亚当用にパラメーターを初期化します。
trailingAvg = [];trailingAvgSq = [];
学習の進行状況プロットを初期化します。
如果阴谋==“培训进度”figure lineLossTrain=动画线('颜色'[0.85 0.325 0.098]);ylim([0正])包含(“迭代”)伊拉贝尔(“损失”) 网格在…上结束
モデルモデル学习させます。
迭代= 0;start = tic;%循环epochs。为历元=1:numEpochs%洗牌数据。洗牌(兆贝可)%循环在迷你批次虽然Hasdata(MBQ)迭代=迭代+ 1;[DLX,DLY1,DLY2] =下一个(MBQ);%使用dlfeval和%MACEMEGRADENTERS功能。[gradients,state,loss]=dlfeval(@modelGradients,parameters,dlX,dlY1,dlY2,state);%使用ADAM Optimizer更新网络参数。[参数,trailingavg,trailingavgsq] = adamupdate(参数,渐变,...trailingAvg,trailingAvgSq,迭代);%显示训练进度。如果阴谋==“培训进度”D=持续时间(0,0,toc(开始),'格式','hh:mm:ss');Addpoints(LineLoStrain,迭代,Double(收集(提取数据(丢失)))标题(“时代:”+时代+”,过去:“+字符串(D)现在开始结束结束结束

モデルのテスト
真のラベルと角度をもつテストセットで予測を比較して,モデルの分類精度をテストします。学習データと同じ設定の小型批处理队列オブジェクトを使用して,テストデータセットを管理します。
[XTest,欧美,anglesTest] = digitTest4DArrayData;dsXTest = arrayDatastore (XTest,“IterationDimension”,4);dsYTest=arrayDatastore(YTest);dsAnglesTest=arrayDatastore(anglesTest);dsTest=combine(dsXTest,Dsystest,dsAnglesTest);mbqTest=minibatchqueue(dsTest,...'迷你atchsize',小匹马,...“MiniBatchFcn”,@preprocessminibatch,...“MiniBatchFormat”,{'SSCB','',''});
検証データのラベルと角度を予測するために,ミニバッチをループ処理し,doTrainingオプションを假に設定したモデル関数を使用します。予測されたクラスと角度を保存します。予測されたクラスおよび角度を真のクラスおよび角度と比較し,その結果を保存します。
dotraining = false;classespredictions = [];anglespredictions = [];classcorr = [];anglediff = [];%循环在迷你批次。虽然Hasdata(MBQTEST)%读取迷你批次数据。[dlXTest,dlY1Test,dlY2Test]=next(mbqTest);%使用预测函数进行预测。[dlY1Pred, dlY2Pred] =模型(参数、dlXTest doTraining、状态);%确定预测类。y1predbatch = onehotdecode(dly1pred,classnames,1);classesepredictions = [classespricictions y1predbatch];Dermine预测角度y2predbatch =提取数据(dly2pred);anglespredictions = [anglespredictions y2predbatch];%比较预测和真实课程Y1Test = onehotdecode (dlY1Test一会1);classCorr = [classCorr Y1PredBatch == Y1Test];%比较预测和真实角度anglediffbatch = y2predbatch - dly2test;Anglediff = [Anglediff ExtractData(聚集(Anglediffbatch))];结束
分類精度を評価します。
精度=意味着(classCorr)
精度=0.9730
回帰精度を評価します。
Anglermse = SQRT(平均(Anglediff。^ 2))
anglermse =仅有一个的6.6909
一部のイメージと、その予測を表示します。予測角度を赤、正解ラベルを緑で表示します。
idx = randperm(大小(xtest,4),9);数字为i=1:9子批次(3,3,i)i=XTest(:,:,:,idx(i));imshow(i)保持在…上sz=尺寸(I,1);偏移量=sz/2;角度预测(idx(I));绘图(偏移量*[1-tand(thetaPred)1+tand(thetaPred)],[sz 0],'r--')ThetAvalidation = Anglyest(IDX(i));绘图(offset * [1-TAND(THETAVATIONATION)1 + TAND(THETAV验证)],[SZ 0],'G - ')持有关label = string(classesepredictions(idx(i)));标题(”的标签:“+标签)结束

モデル関数
関数模型は,モデルパラメーター参数,入力データdlX、モデルが学習と予測のどちらの出力を返すべきかを指定するフラグdoTraining,およびネットワークの状態状态をを受け取りますネットワーク予测はラベルの,角度の予测,および更新されたの状态ををします。
作用[dlY1、dlY2] =模型(参数、dlX doTraining,状态)%卷积重量= parameters.conv1.Weights;偏见= parameters.conv1.Bias;海底= dlconv (dlX、权重、偏见,'填充',“一样”);%批量归一化,Relu抵消= parameters.batchnorm1.Offset;规模= parameters.batchnorm1.Scale;trainedMean = state.batchnorm1.TrainedMean;trainedVariance = state.batchnorm1.TrainedVariance;如果doTraining[Dy,trainedMean,trainedVariance]=批次标准(Dy,偏移量,比例,trainedMean,trainedVariance);%更新状态State.batchnorm1.troundmean =训练有素;State.batchnorm1.TrountVariance =训练variance;其他的海底= batchnorm(海底、抵消、规模、trainedMean trainedVariance);结束海底= relu(海底);%卷积,批量归一化(跳过连接)重量= parameters.convSkip.Weights;偏见= parameters.convSkip.Bias;dlYSkip = dlconv(海底,重量、偏见,“步”,2); offset=parameters.batchnormSkip.offset;scale=parameters.batchnormSkip.scale;trainedMean=state.batchNormalSkip.trainedMean;trainedVariance=state.batchNormalSkip.trainedVariance;如果dotRaining [Dlyskip,训练有谋,训练审查] = Batchnorm(Dlyskip,偏移,刻度,训练有谋,训练遗嘱);%更新状态state.batchnormSkip.TrainedMean = trainedMean;state.batchnormSkip.TrainedVariance = trainedVariance;其他的Dlyskip = Batchnorm(Dlyskip,偏移,规模,训练霸,训练variance);结束%卷积重量= parameters.conv2.Weights;偏见= parameters.conv2.Bias;海底= dlconv(海底,重量、偏见,'填充',“一样”,“步”2);%批量归一化,Relu抵消= parameters.batchnorm2.Offset;规模= parameters.batchnorm2.Scale;trainedMean = state.batchnorm2.TrainedMean;trainedVariance = state.batchnorm2.TrainedVariance;如果doTraining[Dy,trainedMean,trainedVariance]=批次标准(Dy,偏移量,比例,trainedMean,trainedVariance);%更新状态state.batchnorm2。TrainedMean = TrainedMean;state.batchnorm2。TrainedVariance = TrainedVariance;其他的海底= batchnorm(海底、抵消、规模、trainedMean trainedVariance);结束海底= relu(海底);%卷积重量= parameters.conv3.Weights;偏见= parameters.conv3.Bias;海底= dlconv(海底,重量、偏见,'填充',“一样”);%批量标准化偏移量=parameters.BatchNorma3.offset;刻度=parameters.BatchNorma3.scale;trainedMean=state.BatchNorma3.trainedMean;trainedVariance=state.BatchNorma3.trainedVariance;如果doTraining[Dy,trainedMean,trainedVariance]=批次标准(Dy,偏移量,比例,trainedMean,trainedVariance);%更新状态State.batchnorm3.trountmean =训练有谋;State.batchnorm3.trountaRiance =训练variance;其他的海底= batchnorm(海底、抵消、规模、trainedMean trainedVariance);结束%加法,reludlY=dlYSkip+dlY;dlY=relu(dlY);%完全连接,softmax(标签)权重=parameters.fc1.weights;bias=parameters.fc1.bias;dlY1=fullyconnect(dlY,权重,bias);dlY1=softmax(dlY1);%完全连接(角度)重量= parameters.fc2.Weights;偏见= parameters.fc2.Bias;dlY2 = fullyconnect(海底,重量、偏见);结束
モデル勾配关节
関数modelGradientsは,モデルパラメーター,入力データdlXののミニバッチととそれにするするT1およびT2(それぞれラベルと角度を含む)を受け取り,学校可なパラメーターについてのの勾配,更新されたの,および対応する损失を返し。
作用[gradients,state,loss]=modelGradients(参数dlX,T1,T2,state)doTraining=true;[dlY1,dlY2,state]=model(参数dlX,doTraining,state);lossLabels=crossentropy(dlY1,T1);lossAngles=mse(参数dlY2,T2);loss=lossLabels+0.1*lossAngles;gradients=dlgradient(损失,参数);结束
ミニバッチ前処理関数
関数preprocessMiniBatchは,次の手順でデータを前処理します。
入力电池配列からイメージデータを抽出して数値配列に連結します。4番目の次元でイメージデータを連結することにより,3番目の次元が各イメージに追加されます。この次元は,シングルトンチャネル次元として使用されます。
入力细胞配列からラベルと角度データ抽出して,それを2番目のと共に,分类配列および数码配列にそれぞれします。
カテゴリカルラベルラベル数据配列にに符符化符ます。
作用[x,y,角度] = preprocessminibatch(xcell,ycell,anglecell)%从细胞和连接中提取图像数据猫(X = 4,伊势亚{:});%从单元格中提取标签数据并连接Y =猫(2,YCell {:});%提取来自小区的角度数据并连接角=猫(2,angleCell {:});%单热量编码标签Y=onehotcode(Y,1);结束
参考
dlarray|sgdmupdate|德尔费瓦尔|dlgradient|全协商|DLCONV.|softmax|relu.|batchnorm|crossentropy|小型批处理队列|onehotencode|onehotdecode
