pem
优化线性和非线性模型的预测误差最小化
描述
例子
改进估计状态空间模型
用子空间方法估计一个离散时间状态空间模型。然后,通过最小化预测误差对其进行优化。
估计一个离散时间状态空间模型使用n4sid,它应用了子空间方法。
负载iddata7z7;z7a = z7(施用);选择= n4sidOptions (“焦点”,“模拟”);init_sys = n4sid (z7a 4选择);
init_sys提供73.85%的适合于估计数据。
init_sys.Report.Fit.FitPercent
ans = 73.8490
使用pem以提高契合度。
sys = pem (z7a init_sys);
分析结果。
比较(z7a sys, init_sys);
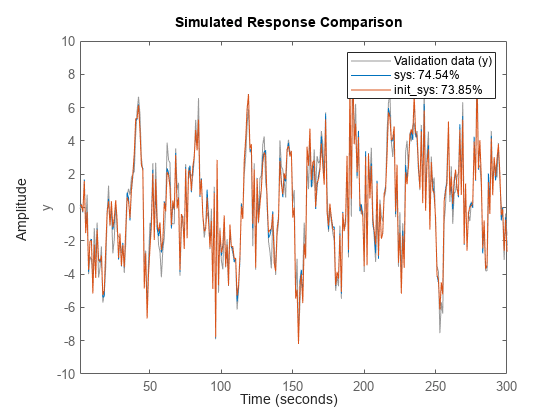
sys提供74.54%的拟合估计数据。
估计非线性灰箱模型
估计非线性灰箱模型的参数来拟合直流电机数据。
加载实验数据,并指定信号属性,如启动时间和单位。
负载(fullfile (matlabroot“工具箱”,“识别”,“iddemos”,“数据”,“dcmotordata”));数据= iddata(y, u, 0.1);数据。Tstart = 0;数据。TimeUnit =“年代”;
配置非线性灰箱模型(idnlgrey)模型。
对于本例,使用dcmotor_m.m文件。要查看该文件,输入编辑dcmotor_m.m在MATLAB®命令提示符。
file_name =“dcmotor_m”;订单= [2 1 2];参数= (1;0.28);initial_states = (0, 0);t = 0;init_sys = idnlgrey (file_name、秩序、参数initial_states Ts);init_sys。TimeUnit =“年代”;setinit (init_sys“固定”,{假假});
init_sys非线性灰箱模型的结构是否由dcmotor_m.m.该模型有一个输入,两个输出和两种状态订单.
setinit (init_sys“固定”,{假假})指定初始状态init_sys为自由估计参数。
估计模型参数和初始状态。
sys = pem(数据、init_sys);
sys是一个idnlgrey模型,它封装了估计参数及其协方差。
分析评估结果。
比较(数据、sys init_sys);
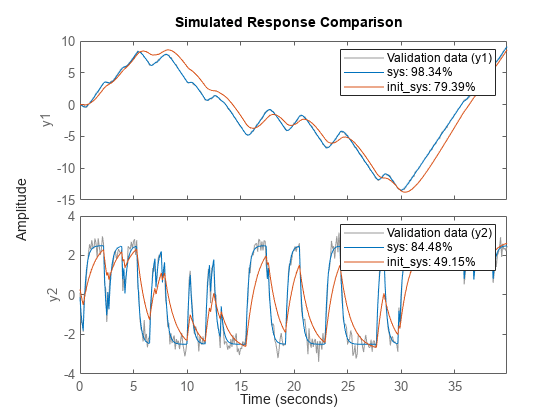
sys提供了98.34%的拟合估计数据。
使用过程模型配置评估
创建流程模型结构并更新其参数值以最小化预测误差。
初始化流程模型的系数。
init_sys = iDproc(“P2UDZ”);init_sys。Kp = 10;init_sys。太瓦=0.4; init_sys.Zeta = 0.5; init_sys.Td = 0.1; init_sys.Tz = 0.01;
的Kp,太瓦,ζ,道明,Tz系数init_sys都配置了他们的初始猜测。
使用init_sys使用测量数据配置预测误差最小化模型的估计。因为init_sys是一个idproc模型,使用procestOptions创建选项集。
负载iddata1z1;选择= procestOptions (“显示”,“上”,“SearchMethod”,“lm”);sys = pem (z1、init_sys选择);
估计数据:时域数据z1数据有1个输出,1个输入,300个样本。模型类型:{'P2DUZ'}Levenberg-Marquardt搜索< br > ------------------------------------------------------------------------------------------ < br >一阶改进规范(%)< br >迭代步最优成本预期实现二分< br >------------------------------------------------------------------------------------------ 0 - 414 3.8 - 21.2201 - 119.4048 - 1.15 3.8 - 8.55 323 814 2 14.8743 - 2.48 6.84305 - 0.873 4.41 - 23.3 0 451 4.43 54 11 4 8.75 5.20355 0.977 1.49 e + 03 24 7 5 64.7 1.83911 0.973 473 13 0 6 0 7 1.67335 0.062 6.57 1.67582 0.225 20.3 4.98 8.88 0.0829 1.67334 0.00494 0.0555 0.000374 0.000648 0.147 0 8 0------------------------------------------------------------------------------------------ 终止条件:附近(当地)最小,(标准(g) < tol) . .迭代次数:8,函数评估数:42 Status: Estimated using PEM Fit to estimate data: 70.63%, FPE: 1.73006
检查模型是否合适。
sys.Report.Fit.FitPercent
ans = 70.6330
sys与实测数据拟合率为70.63%。
输入参数
输出参数
算法
PEM使用数值优化来最小化成本函数,预测误差的加权范数,对于标量输出定义如下:
在哪里E(t)为模型的实测输出与预测输出之间的差值。对于线性模型,误差定义为:
在哪里E(t)是向量和代价函数吗 为标量值。下标N表示代价函数是数据样本数量的函数,值越大,代价函数的准确性越高N.对于多输出模型,前面的方程更为复杂。有关更多信息,请参阅系统识别:用户的理论,第二版,Lennart Ljung, Prentice Hall PTR, 1999。
选择功能
你可以达到和pem通过对各种模型结构使用专用的估计命令。例如,使用init_sys ss(数据)用于估计状态空间模型。
你也可以从以下列表中选择一个网站: