JPEG图像分块使用Deep学习
此示例示出了如何训练去噪卷积神经网络(DnCNN),然后使用该网络来减少图像中的JPEG压缩伪像。
该示例示出了如何训练DnCNN网络,并且还提供一个预训练的DnCNN网络。如果您选择训练DnCNN网络,使用CUDA的NVIDIA GPU™的计算能力3.0或更高版本强烈推荐(需要并行计算工具箱™)。
介绍
图像压缩用于减少图像的内存占用。JPEG图像格式采用了一种流行而强大的压缩方法,它使用质量因子来指定压缩量。降低质量值将导致更高的压缩和更小的内存占用,从而牺牲图像的视觉质量。
JPEG压缩是有损,这意味着压缩过程会导致图像丢失信息。对于JPEG图像,此信息丢失显示为图像中的阻塞伪影。如图所示,更多的压缩会导致更多的信息丢失和更强的伪影。具有高频内容的纹理区域(例如草和云)看起来很模糊。尖锐的边缘,比如屋顶和灯塔顶上的护栏,都会发出响声。

JPEG去块是减少JPEG图像中压缩伪影影响的过程。有几种JPEG去块方法,包括使用深度学习的更有效的方法。这个例子实现了一个基于深度学习的方法,试图最小化JPEG压缩伪影的影响。
该DnCNN网络
这个例子使用一个内置的深前馈卷积神经网络,称为DnCNN。该网络主要是设计用于从图像中的噪声除去。然而,DnCNN架构还可以训练删除JPEG压缩失真或提高图像清晰度。
参考文献[1]采用残差学习策略,即DnCNN网络学习估计残差图像。残留图像是原始图像和扭曲图像之间的区别。剩余图像包含关于图像失真的信息。在本例中,失真显示为JPEG块伪影。
训练DnCNN网络从彩色图像的亮度中检测出剩余图像。图像的亮度通道,ÿ,通过红色、绿色和蓝色像素值的线性组合表示每个像素的亮度。相反,图像的两个色度通道,CB和铬,是代表色差信息的红,绿和蓝色像素值的不同线性组合。DnCNN是因为人类的感知是在亮度比在颜色变化的变化更敏感仅使用亮度通道训练。
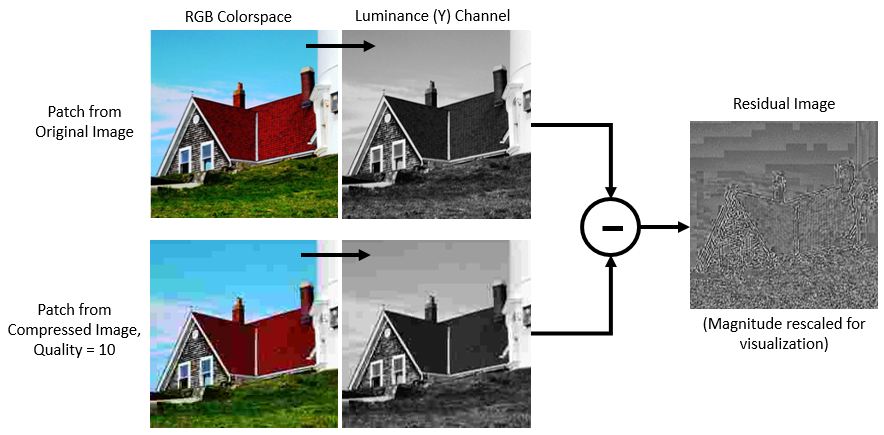
如果 是原始图像的亮度 是包含JPEG压缩伪影的图像的亮度,然后DnCNN网络的输入是 网络学会了预测 从训练数据来看。
一旦DnCNN网络获知如何估计的残留图像,它可以通过将残余图像的压缩的亮度信道,然后转换图像回RGB颜色空间重构压缩的JPEG图像的无畸变的版本。
下载培训数据
下载IAPR TC-12基准,该基准包含20,000张静态自然图像[2]. 数据集包括人、动物、城市等的照片。数据文件的大小约为1.8gb。如果不想下载训练网络所需的训练数据集,则可以通过键入负载( 'pretrainedJPEGDnCNN.mat')在命令行。然后,直接去执行JPEG解块使用DnCNN网络本例中的部分。
使用helper函数,下载iaprtc12数据,下载数据。该功能连接到例如作为支撑文件。金宝app
imagesDir = tempdir;url =“http://www-i6.informatik.rwth-aachen.de/imageclef/resources/iaprtc12.tgz”;downloadIAPRTC12Data(URL,imagesDir);
这个例子将训练网络与IAPR TC-12基准数据的一小部分。加载imageCLEF训练数据。所有图像都是32位JPEG彩色图像。
trainImagesDir=完整文件(imagesDir,“iaprtc12”,'图片','00');扩展={名为.jpg,'.bmp','.png'};imdsPristine = imageDatastore(trainImagesDir,'FileExtensions',EXTS);
列出训练图像的数量。
纽梅尔(imdsPristine.Files文件)
ans=251个
准备培训数据
要创建训练数据集,请读入原始图像,并以JPEG文件格式写出具有不同压缩级别的图像。
指定用于渲染图像压缩伪影的JPEG图像质量值。质量值必须在[0,100]范围内。较小的质量值会导致更多的压缩和更强的压缩伪影。使用小质量值的更密集采样,使训练数据具有广泛的压缩伪影。
JPEG质量=[5:5:40 50 60 70 80];
压缩后的图像作为MAT文件存储在磁盘上的目录中compressedImagesDir. 计算出的剩余图像作为MAT文件存储在磁盘的目录中剩余图像红外. MAT文件存储为数据类型双重的在训练网络时获得更高的精度。
compressedImagesDir = fullfile (imagesDir,“iaprtc12”,'JPEGDeblockingData','compressedImages');residualImagesDir=完整文件(imagesDir,“iaprtc12”,'JPEGDeblockingData','剩余图像');
使用辅助函数createJPEGDeblockingTrainingSet预处理训练数据。该功能连接到例如作为支撑文件。金宝app
对于每个原始的训练图像,helper函数写一个带质量因子100的图像副本作为参考图像,并将带每个质量因子的图像副本作为网络输入。该函数计算参考和压缩图像在数据类型中的亮度(Y)通道双重的对于更高的精度计算剩余图像时。压缩的图像存储在磁盘上,.MAT目录中的文件压缩程序。该计算的剩余图像存储在磁盘目录中的文件.MAT剩余部分。
[compressedDirName,residualDirName] = createJPEGDeblockingTrainingSet(imdsPristine,JPEGQuality);
培训创建随机块提取数据存储
使用随机补丁提取数据存储将训练数据馈送到网络。此数据存储从包含网络输入和所需网络响应的两个图像数据存储中提取随机对应的修补程序。
在本例中,网络输入是压缩图像。期望的网络响应是残差图像。创建一个名为IMD压缩从压缩图像文件的集合。创建一个名为残差从计算残留图像文件的集合。这两个数据存储需要一个辅助功能,预读,从图像文件中读取图像数据。此函数作为支持文件附加到示例。金宝app
imdsCompressed = imageDatastore(compressedDirName,'FileExtensions',“.mat”,'ReadFcn',@matRead);imdsremain=imageDatastore(剩余长度,'FileExtensions',“.mat”,'ReadFcn',@matRead);
创建imageDataAugmenter即数据扩张的指定的参数。在训练期间使用数据扩张以改变训练数据,从而有效地增加了可用的训练数据量。在此,增强因子90度和在x方向上的随机反射指定随机旋转。
扩增器=ImageData扩增器(...'随机旋转'@()兰迪([0,1],1)* 90,...'RandXReflection',正确);
创建随机补丁提取数据存储从两个图像数据存储。指定的50逐50像素的贴片尺寸。每个图像生成尺寸50逐50个像素的128个随机补丁。指定的128迷你批量大小。
patchSize=50;patchesPerImage=128;dsTrain=randomPatchExtractionDatastore(imdsCompressed、imdsRemain、patchSize,...'补丁程序图像',patchesPerImage,...'DataAugmentation',增强因子);dsTrain.MiniBatchSize = patchesPerImage;
随机抽取的补丁数据存储德斯特兰在epoch迭代时向网络提供小批量数据。预览从数据存储读取的结果。
inputBatch =预览(dsTrain);DISP(inputBatch)
×50双}{50×50双}{50×50双}{50×50双}{50×50双}{50×50双}{50×50双}
设置DnCNN层
通过创建内置DnCNN网络层dnCNNLayers公司功能。默认情况下,网络深度(卷积层数)为20。
图层=dnCNNLayers
层= 1x59层数组与层:1“InputLayer”图像输入50 x50x1图片2 Conv1卷积64 3 x3x1旋转步[1]和填充[1 1 1 1]3‘ReLU1 ReLU ReLU 4 Conv2卷积64 3 x3x64旋转步[1]和填充[1 1 1 1]5‘BNorm2批量标准化批量标准化与64个频道6‘ReLU2 ReLU ReLU 7 Conv3卷积64 3 x3x64旋转步[1]和填充(1 1 1)8“BNorm3”批量标准化批量标准化与64个频道9 ' ReLU3 ReLU ReLU 10Conv4卷积64 3 x3x64旋转步[1]和填充[1 1 1 1]11的BNorm4批量标准化批量标准化与64个频道12的ReLU4 ReLU ReLU 13 Conv5卷积64 3 x3x64旋转步[1]和填充[1 1 1 1]14“BNorm5”批量标准化批量标准化与64个频道15 ' ReLU5 ReLU ReLU 16 Conv6卷积64 3 x3x64旋转步[1]和填充[1 1 1 1]17“BNorm6”与64年批量标准化批量正常化渠道18 ' ReLU6 ReLU ReLU 19 Conv7卷积64 3 x3x64旋转步[1]和填充[1 1 1 1]20 ' BNorm7批量标准化批量标准化与64个频道21 ' ReLU7 ReLU ReLU 22 Conv8卷积64 3 x3x64旋转步[1]和填充[1 1 1 1]23 BNorm8的批量标准化批量标准化与64个频道24‘ReLU8 ReLU ReLU 25 Conv9卷积64 3 x3x64旋转步[1]和填充[1 1 1 1]26 BNorm9批正常化批规范化与64个频道27 ' ReLU9 ReLU ReLU 28 Conv10卷积64 3 x3x64旋转步[1]和填充[1 1 1 1]29“BNorm10”批量标准化批量正常化30 64个频道的ReLU10 ReLU ReLU 31 Conv11卷积64 3 x3x64旋转步[1]和填充[1 1 1 1]32“BNorm11”批量标准化批量标准化与64个频道33 ' ReLU11 ReLU ReLU 34 Conv12卷积64 3 x3x64旋转与步幅[1]和填充[1 1 11]35 ' BNorm12批量标准化批量标准化与64个频道36“ReLU12”ReLU ReLU 37 Conv13卷积64 3 x3x64旋转步[1]和填充[1 1 1 1]38“BNorm13”批量标准化批量标准化与64个频道39的ReLU13 ReLU ReLU 40 Conv14卷积64 3 x3x64旋转步[1]和填充(1 1 1)41 BNorm14的批量标准化批量标准化与64个频道42 ' ReLU14 ReLU ReLU 43 Conv15卷积64 3 x3x64卷曲步[1]和填充[1 1 1 1]44 BNorm15的批量标准化批量标准化与64个频道45‘ReLU15 ReLU ReLU 46 Conv16卷积64 3 x3x64旋转步[1]和填充[1 1 1 1]47 BNorm16的批量标准化批量标准化与64个频道48 ' ReLU16 ReLU ReLU 49 Conv17卷积64 3 x3x64旋转步[1]和填充[1 1 1 1]50 BNorm17的批量标准化批量标准化51和64个频道的ReLU17 ReLU ReLU 52Conv18卷积64 3 x3x64旋转步[1]和填充[1 1 1 1]53的BNorm18批量标准化批量标准化与64个频道54的ReLU18 ReLU ReLU 55 Conv19卷积64 3 x3x64旋转步[1]和填充[1 1 1 1]56 BNorm19的批量标准化批量标准化与64个频道57 ' ReLU19 ReLU ReLU 58 Conv20的卷积1 3 x3x64旋转步[1]和填充[1 1 1 1]59 FinalRegressionLayer回归输出均方误差
选择培训选项
利用随机梯度下降动量(SGDM)优化训练网络。使用培训选项函数。
训练一个深度的网络是很费时的。通过指定高学习率来加速培训。然而,这可能会导致网络的梯度爆炸或无法控制地增长,从而阻止网络的成功训练。若要将渐变保持在有意义的范围内,请通过设置启用渐变剪裁'渐变阈值'到0.005分,并指定'梯度阈值方法'使用渐变的绝对值。
maxEpochs=30;initLearningRate=0.1;l2reg=0.0001;batchSize=64;options=trainingOptions('新加坡元',...“动力”,0.9分,...'初始清除日期',初始学习速率,...'学习更新计划','分段',...'梯度阈值方法','绝对值',...'渐变阈值',0.005,...“L2正则化”l2reg,...'小批量大小',批量大小,...'最大时期',最大时期,...“情节”,'培训进度',...'冗长',错误);
训练网络
配置培训选择和随机抽取的补丁数据存储后,训练使用的DnCNN网络列车网络函数。要训练网络,设置doTraining参数在下面的代码来真的。强烈建议使用具有计算能力3.0或更高的cuda能力的NVIDIA™GPU进行培训。
如果你保留doTraining以下代码中的参数为假,则示例返回一个经过预处理的DnCNN网络。
注:在NVIDIA上训练大约需要40小时™ 泰坦X和可能需要更长的时间取决于你的GPU硬件。
训练在doTraining为真时运行doTraining=错误;如果doTraining modelDateTime=datestr(现在,'DD-MMM-YYYY-HH-MM-SS');[net,info]=列车网络(dsTrain,层,选项);保存(['培训JPEGDNCNN-'modelDateTime'-时代-'num2str(最大时期)“.mat”]'净',“选项”);其他的装载(“pretrainedJPEGDnCNN.mat”);结束
您现在可以使用DnCNN网络从新的图像删除JPEG压缩失真。
执行JPEG解块使用DnCNN网络
要使用DnCNN执行JPEG解块,请遵循本示例的其余步骤。该示例的其余部分演示如何:
在三个不同的质量等级创建具有JPEG压缩失真样品测试图像。
使用DnCNN网络删除压缩伪影。
视觉上比较去块前后的图像。
通过量化压缩和去块图像与未失真参考图像的相似性来评估压缩和去块图像的质量。
创建块效应样照
创建样本图像,以评估使用DnCNN网络JPEG图像分块的结果。测试数据集,testImages包含在发货图像处理工具箱™21个不失真的图像。加载图像到imageDatastore。
扩展={名为.jpg,'.png'};文件名={'夏洛克.jpg','car2.jpg','织物.png','绿色.jpg','hands1.jpg','科比.png',...'lighthouse.png','micromarket.jpg','办公室4.jpg','洋葱.png','pears.png','yellowlily.jpg',...'indiancorn.jpg','火烈鸟.jpg','塞维利亚.jpg','llama.jpg','parkavenue.jpg',...'peacock.jpg','car1.jpg','草莓.jpg','wagon.jpg'};文件路径=[fullfile(matlabroot,'工具箱','图片','IMDATA')filesep];filePathNames=strcat(filePath,fileNames);testImages=imageDatastore(filePathNames,'FileExtensions',EXTS);
显示检测的图像作为一个蒙太奇。
蒙太奇(testImages)

选择要用作JPEG解块参考图像的图像之一。您可以选择使用自己的未压缩图像作为参考图像。
INDX = 7;%从测试图像数据存储中读取的图像索引irereference=readimage(testImages,indx);imshow(irereference)标题('未压缩的参考图像')

使用JPEG创建三个压缩测试图像质量的10,20,和50的值。
imwrite(Ireference,完整文件(TEMPDIR,'testQuality10.jpg'),'质量',10);imwrite(Ireference,完整文件(TEMPDIR,'testQuality20.jpg'),'质量',20);imwrite(引用,完整文件(tempdir,'测试质量50.jpg'),'质量',50分);
预处理的图像压缩
将图像的压缩版本读入工作区。
I10=imread(完整文件(tempdir,'testQuality10.jpg'));I20 = imread(完整文件(TEMPDIR,'testQuality20.jpg'));I50=imread(完整文件(tempdir,'测试质量50.jpg'));
显示压缩图像作为一个蒙太奇。
蒙太奇({I50,I20,I10},'大小'[1 3])标题(“带有质量因子的jpeg压缩图像:50、20和10(从左到右)”)

回想一下,DnCNN是因为人类的感知是在亮度比在颜色变化的变化更敏感仅利用图像的亮度信道训练。从转换RGB色彩空间的JPEG压缩图像使用YCbCr色彩空间rgb2ycbcr函数。
I10ycbcr = rgb2ycbcr(I10);I20ycbcr = rgb2ycbcr(I20);I50ycbcr = rgb2ycbcr(I50);
应用DnCNN网络
要执行网络的前向传递,请使用去噪功能。此函数使用完全相同的训练和测试过程对图像进行去噪。您可以将JPEG压缩伪影视为一种图像噪声。
I10y_predicted = denoiseImage(I10ycbcr(:,:,1),净);I20y_predicted = denoiseImage(I20ycbcr(:,:,1),净);I50y_predicted = denoiseImage(I50ycbcr(:,:,1),净);
色度通道不需要处理。将解块亮度通道与原始色度通道连接以获得YCbCr颜色空间中的解块图像。
I10ycbcr_predicted=cat(3,I10y_predicted,I10ycbcr(:,:,2:3));I20ycbcr_predicted=cat(3,I20y_predicted,I20ycbcr(:,:,2:3));I50ycbcr_predicted=cat(3,I50y_predicted,I50ycbcr(:,:,2:3));
通过使用去块YCbCr图像转换为RGB色彩空间ycbcr2rgb公司函数。
I10_predicted = ycbcr2rgb(I10ycbcr_predicted);I20_predicted = ycbcr2rgb(I20ycbcr_predicted);I50_predicted = ycbcr2rgb(I50ycbcr_predicted);
显示图像解封作为一个蒙太奇。
蒙太奇({I50预测,I20预测,I10预测},'大小'[1 3])标题(“与品质因数50,20和10(从左至右)解封图像”)

为了对这些改进有更好的视觉理解,检查每个图像内部的一个更小的区域。使用向量指定感兴趣的区域(ROI)投资回报率格式为[Xÿ宽度高度]。这些元素定义左上角的x坐标和y坐标,以及ROI的宽度和高度。
ROI = [30 440 100 80];
将压缩图像裁剪到此ROI,并将结果显示为蒙太奇。
i10=imcrop(i10,roi);i20=imcrop(i20,roi);i50=imcrop(i50,roi);蒙太奇({i50 i20 i10},'大小'[1 3])标题('质量因子为50、20和10(从左到右)的JPEG压缩图像的修补程序')

将解除锁定的图像裁剪到此ROI,并将结果显示为蒙太奇。
i10predicted = imcrop(I10_predicted,ROI);i20predicted = imcrop(I20_predicted,ROI);i50predicted = imcrop(I50_predicted,ROI);蒙太奇({i50predicted,i20predicted,i10predicted}'大小'[1 3])标题(“质量因子为50、20和10(从左到右)的去块图像的补丁”)

定量比较
通过四个指标量化解封图像的质量。您可以使用显示JPEG结果helper函数用于计算质量因子10、20和50处压缩和解除锁定图像的这些度量。此函数作为支持文件附加到示例。金宝app
结构相似度指数(SSIM)。SSIM评估的图像的三个特征的视觉影响:亮度,对比度和结构,针对参考图像。越接近SSIM值是1,更好的测试图像与基准图像一致。这里,参考图像是无失真的原始图像,
Ireference,在JPEG压缩之前。见SSIM有关此度量的详细信息。峰值信噪比(PSNR)。PSNR值越大,信号相对于失真越强。见
峰值信噪比有关此度量的详细信息。自然性图像质量评估器(NIQE)。NIQE使用从自然场景训练的模型测量感知图像质量。NIQE分数越小,知觉质量越好。见
咬有关此度量的详细信息。盲/无参考图像空间质量评估器(BRISQUE)。BRISQUE使用从具有图像失真的自然场景中训练的模型来测量感知图像质量。轻快的分数越小,知觉质量越好。见
必胜有关此度量的详细信息。
显示JPEG结果(Ireference,I10,I20,I50,I10_predicted,I20_predicted,I50_predicted)
------------------------------------------SSIM比较====I10:0.90624 I10_预测值:0.91286 I20:0.94904 I20_预测值:0.95444 I50:0.97238 I50_预测值:0.97482----------PSNR比较===I10:26.6046 I10_预测值:27.0793 I20:28.8015 I20_预测值:29.3378 I50:31.4512I50}u预测值:31.8584~~~~~~~~~~~~~~~~~~52.372 I10_预测值:38.9271 I20:45.3772 I20_预测值:30.8991 I50:27.7093 I50_预测值:24.3845注:轻快的分数意味着更好的感知质量
参考
[1]张,K,W佐,Y.陈,孟D.和L.张,“超越高斯去噪:深CNN图像去噪的残余学习。”电气与电子工程师协会®图像处理事务. 2017年2月。
[2] Grubinger,M.,P.克拉夫,H.米勒和T. Deselaers。“该IAPR TC-12基准测试:一种新的评价资源的可视化信息系统”2006年OntoImage语言资源的法律程序基于内容的图像检索. 意大利热那亚。第5卷,2006年5月,第10页。
也可以看看
去噪|dnCNNLayers公司|随机补丁提取数据存储|rgb2ycbcr|列车网络|培训选项|ycbcr2rgb公司
相关主题
你也可以从以下列表中选择一个网站:
