ClassificationTree类
用于多类分类的二叉决策树
描述
一个ClassificationTree对象表示具有二叉分类功能的决策树。类的对象可以使用预测方法。该对象包含用于训练的数据,因此它也可以计算重新替换预测。
建设
创建一个ClassificationTree对象的使用fitctree.
属性
|
的单元格数组指定为数值预测器的Bin边p数值向量,p是预测器的数量。每个向量包括一个数字预测器的箱边。用于分类预测器的单元格数组中的元素为空,因为软件没有将分类预测器存储在存储单元中。 只有当您指定 您可以复制被分类的预测器数据 X = mdl.X;%预测数据Xbinned = 0 (size(X));边缘= mdl.BinEdges;找到被分类的预测器的指数。idxNumeric =找到(~ cellfun (@isempty边缘));if iscolumn(idxNumeric) idxNumeric = idxNumeric';end for j = idxNumeric x = x (:,j);%如果x是一个表,则将x转换为数组。If istable(x) x = table2array(x);将x组到bin中
Xbinned包含用于数字预测器的容器索引,范围从1到容器数量。Xbinned对于分类预测器,值为0。如果X包含南S,然后对应的Xbinned值是南年代。 |
|
分类预测指标,指定为一个正整数向量。 |
|
一个n-by-2 cell array |
|
一个n-by-2数组,其中包含每个节点的子节点编号 |
|
一个n——- - - - - -k中的节点的类计数数组 |
|
中的元素列表 |
|
一个n——- - - - - -k中的节点的类概率数组 |
|
方阵, |
|
一个n中分支使用的类别的单元格数组
|
|
一个n元素向量的值用作切入点
|
|
一个n中每个节点的切割类型
|
|
一个n中的每个节点中用于分支的变量名称的单元格数组
|
|
一个n中的每个节点中用于分支的变量的数字索引数组 |
|
扩展的预测器名称,存储为字符向量的单元格数组。 如果模型对分类变量使用编码,那么 |
|
超参数的交叉验证优化描述,存储为
|
|
一个n元素逻辑向量 |
|
训练参数 |
|
训练数据中的观测数,数值标量。 |
|
一个n的每个节点中最有可能的类的名称 |
|
一个n中节点误差的元素向量 |
|
一个n中节点的概率的元素向量 |
|
一个n-树中节点风险的元素向量,其中n为节点数。每个节点的风险是该节点的杂质(基尼系数或偏差)的度量,由节点概率加权。如果树是按两步增长的,则每个节点的风险为零。 |
|
一个n中的节点大小的元素向量 |
|
节点的数量 |
|
一个n-元素向量,其中包含每个节点的父节点数 |
|
包含预测器名称的字符向量的单元格数组,按它们出现的顺序排列 |
|
每个类的先验概率的数字向量。元素的顺序 |
|
数字向量,每个修剪级别有一个元素。修剪级别的取值范围为0 ~米,然后 |
|
一个n的每个节点中具有修剪级别的元素数值向量 |
|
指定响应变量名称的字符向量( |
|
一个n元素逻辑向量,指示原始预测器数据的哪些行( |
|
用于转换预测分类分数的函数句柄,或表示内置转换函数的字符向量。
例如,要将分数转换函数更改为:
|
|
一个n-element用于分割的代理项的单元格数组 |
|
一个n用于代理拆分的数字切割赋值的单元格数组 |
|
一个n用于代理的数值的单元格数组 |
|
一个n中每个节点的代理分割类型 |
|
一个n中每个节点中用于代理分割的变量名的单元格数组 |
|
一个n-element单元阵列的预测关联度量为代理分裂 |
|
的比例 |
|
预测值的矩阵或表每一列的 |
|
类别数组、字符向量的单元数组、字符数组、逻辑向量或数字向量。每一行的 |
对象的功能
紧凑的 |
紧凑的树 |
compareHoldout |
使用新数据比较两个分类模型的准确性 |
crossval |
旨在决策树 |
cvloss |
交叉验证的分类误差 |
边缘 |
分类的优势 |
收集 |
收集的属性统计和机器学习工具箱对象从GPU |
石灰 |
局部可解释的模型不可知解释(LIME) |
损失 |
分类错误 |
保证金 |
分类的利润率 |
partialDependence |
计算部分依赖 |
plotPartialDependence |
创建部分依赖图(PDP)和个人条件期望图(ICE) |
预测 |
使用分类树预测标签 |
predictorImportance |
分类树中预测因子重要性的估计 |
修剪 |
通过修剪产生分类子树序列 |
resubEdge |
边的再替换分类 |
resubLoss |
再代换造成的分类错误 |
resubMargin |
再替换的分类边缘 |
resubPredict |
预测分类树的再替换标签 |
沙普利 |
沙普利值 |
surrogateAssociation |
分类树中代理分裂关联的平均预测度量 |
testckfold |
通过重复交叉验证比较两种分类模型的准确率 |
视图 |
视图分类树 |
复制语义
价值。要了解值类如何影响复制操作,请参见复制对象.
例子
生成分类树
生成一个分类树电离层数据集。
负载电离层tc = fitctree (X, Y)
tc = ClassificationTree ResponseName: 'Y' CategoricalPredictors: [] ClassNames: {'b' ' 'g'} ScoreTransform: 'none' NumObservations: 351属性,方法
控制树的深度
控件可以控制树的深度MaxNumSplits,MinLeafSize,或MinParentSize名称-值对参数。fitctree默认情况下,生成深度决策树。您可以种植较浅的树,以减少模型复杂性或计算时间。
加载电离层数据集。
负载电离层
对于正在生长的分类树,树深度控制器的默认值是:
n - 1为MaxNumSplits.n为训练样本量。1为MinLeafSize.10为MinParentSize.
对于大的训练样本大小,这些默认值趋向于长出深度树。
使用默认值训练分类树以控制树的深度。采用10倍交叉验证对模型进行交叉验证。
rng (1);%的再现性MdlDefault = fitctree (X, Y,“CrossVal”,“上”);
画一个直方图的数量强加的分裂的树。还有,看看其中一棵树。
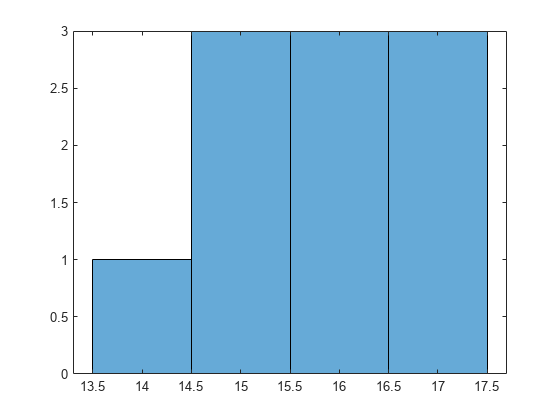
numBranches = @ (x)和(x.IsBranch);mdldefaultnumpartitions = cellfun(numBranches, mdldefault . training);图;直方图(mdlDefaultNumSplits)
视图(MdlDefault。训练有素的{1},“模式”,“图”)
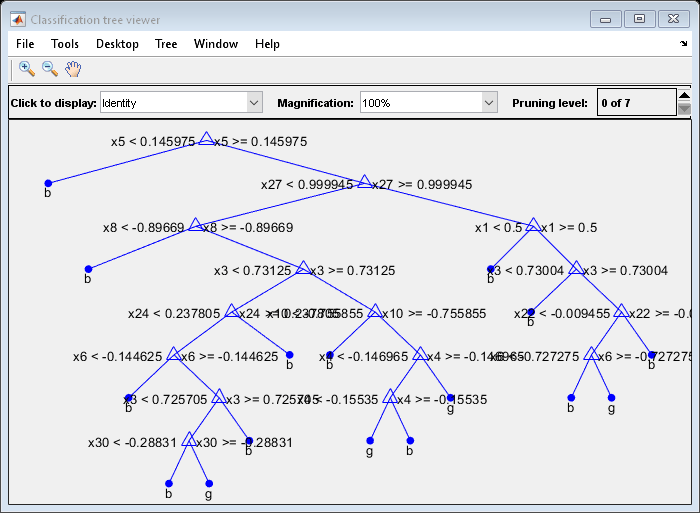
平均拆分次数约为15次。
假设您想要一个不像使用默认分割次数训练的分类树那么复杂(深度)的分类树。训练另一棵分类树,但将最大拆分次数设置为7次,这大约是默认分类树平均拆分次数的一半。采用10倍交叉验证对模型进行交叉验证。
Mdl7 = fitctree (X, Y,“MaxNumSplits”7“CrossVal”,“上”);视图(Mdl7。训练有素的{1},“模式”,“图”)
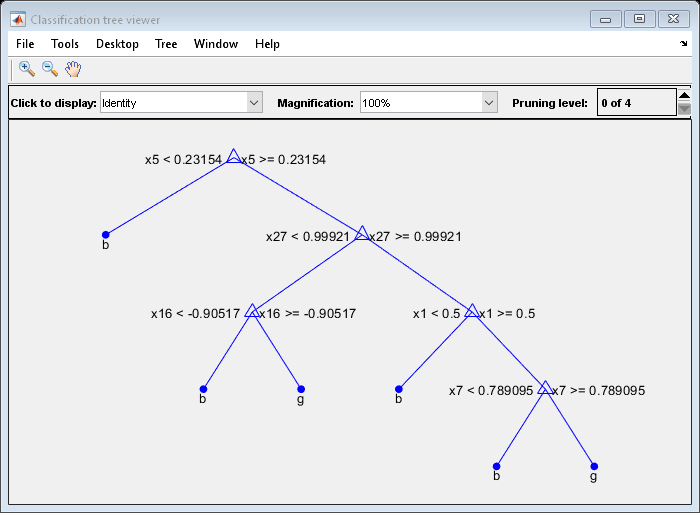
比较模型的交叉验证分类误差。
classErrorDefault = kfoldLoss (MdlDefault)
classErrorDefault = 0.1168
classError7 = kfoldLoss (Mdl7)
classError7 = 0.1311
Mdl7比MdlDefault.
更多关于
参考文献
[1] Breiman, L., J. Friedman, R. Olshen, C. Stone。分类与回归树.佛罗里达州博卡拉顿:CRC出版社,1984。
扩展功能
你也可以从以下列表中选择一个网站:
