ClassificationBaggedEnsemble
包裹:classreg.learning.classif
超类:ClassificationEnsemble
通过重采样生长的分类集成
描述
ClassificationBaggedEnsemble将一组经过训练的弱学习者模型和训练这些学习者的数据结合起来。它可以通过聚合来自弱学习者的预测来预测对新数据的整体反应。
建设
使用。创建一个袋装分类集成对象fitcensemble.设置名称-值对参数“方法”的fitcensemble来“包”使用引导聚合(例如,套袋,随机森林)。
属性
|
数值预测器的箱边,指定为P数值向量,P是预测值的数量。每个向量包括数值预测器的箱边。分类预测器单元格数组中的元素为空,因为软件不存储分类预测器。 仅当您指定 您可以复制被分类的预测器数据 X = mdl.X;%预测数据Xbinned = 0 (size(X));边缘= mdl.BinEdges;找到被分类的预测器的指数。idxNumeric =找到(~ cellfun (@isempty边缘));if iscolumn(idxNumeric) idxNumeric = idxNumeric';end for j = idxNumeric x = x (:,j);%如果x是一个表,则将x转换为数组。If istable(x) x = table2array(x);将x组到bin中
Xbinned包含用于数字预测器的容器索引,范围从1到容器数量。Xbinned分类预测值的值为0。如果X包含楠S,然后对应的Xbinned价值观是楠年代。 |
|
分类预测指标,指定为一个正整数向量。 |
|
中的元素列表 |
|
描述如何 |
|
扩展的预测器名称,存储为字符向量的单元格数组。 如果模型对分类变量使用编码,那么 |
|
拟合信息的数字数组。这个 |
|
字符向量描述的含义 |
|
数字之间的标量 |
|
超参数的交叉验证优化描述,存储为
|
|
描述创建方法的字符向量 |
|
训练参数 |
|
受过训练的弱学习者的数量 |
|
预测器变量的名称单元格数组,按它们出现的顺序排列 |
|
描述原因的字符向量 |
|
逻辑值,指示集合是否经过替换训练( |
|
带有响应变量名称的字符向量 |
|
用于转换分数的函数句柄,或表示内置转换函数的字符向量。 添加或更改 ens.ScoreTransform = '函数' 或 ens.ScoreTransform = @函数 |
|
经过培训的学习者,一组紧凑的分类模型。 |
|
网络中弱学习者训练权重的数值向量 |
|
大小逻辑矩阵 |
|
按比例缩小的 |
|
训练集合的预测值矩阵或表。每一列的 |
|
具有相同行数的类别数组、字符向量单元格数组、字符数组、逻辑向量或数字向量 |
目标函数
紧凑的 |
紧凑分类集成 |
比较控股 |
使用新数据比较两个分类模型的准确性 |
克罗斯瓦尔 |
旨在合奏 |
边缘 |
分类的优势 |
石灰 |
局部可解释模型不可知解释(LIME) |
损失 |
分类错误 |
保证金 |
分类的利润率 |
oobEdge |
Out-of-bag分类边缘 |
oobLoss |
出袋分类错误 |
oobMargin |
袋外分类边距 |
面向对象编程的重要性 |
分类树的随机森林的预测重要度由袋外预测观察的排列估计 |
oobPredict |
预测总体的包外响应 |
部分依赖 |
计算部分依赖 |
plotPartialDependence |
创建部分依赖图(PDP)和单个条件期望图(ICE) |
预测 |
使用分类模型的集合对观测结果进行分类 |
预测重要性 |
决策树分类集成中预测器重要性的估计 |
removeLearners |
移除紧凑分类集成的成员 |
再沉积 |
通过重新替换对边缘进行分类 |
恢复 |
重新替换导致的分类错误 |
resubMargin |
通过重新替换的分类边距 |
再预测 |
在分类模型集合中对观察进行分类 |
简历 |
恢复训练合奏 |
夏普利 |
沙普利值 |
testckfold |
通过重复交叉验证比较两种分类模型的准确率 |
复制语义
价值。要了解值类如何影响复制操作,请参见复制对象.
例子
训练袋装分类树集合
加载电离层数据集。
负载电离层
你可以用所有的测量方法训练100棵分类树。
Mdl = fitcensemble (X, Y,“方法”,“包”)
fitcensemble使用默认的模板树对象templateTree ()作为一个弱的学习者“方法”是“包”.在本例中,为了再现性,请指定“重现”,真的当你创建一个树模板对象,然后使用对象作为弱学习器。
rng (“默认”)%的再现性t=模板树(“复制”,真正的);%随机预测选择的再现性Mdl = fitcensemble (X, Y,“方法”,“包”,“学习者”, t)
Mdl=ClassificationBaggedAssemble ResponseName:'Y'分类预测值:[]类名:{'b''g'}ScoreTransform:'none'NumBrained:100方法:'Bag'LearnerNames:{'Tree'}ReasonForTermination:'在完成请求的训练周期数后正常终止。'FitInfo:[]FitInfoDescription:“无”F示例:1替换:1 UseObsForLearner:[351x100逻辑]属性、方法
Mdl是一个ClassificationBaggedEnsemble模型对象。
Mdl.训练有素是存储经过训练的分类树的100×1单元向量的属性(CompactClassificationTree组成集合的模型对象。
绘制第一个训练的分类树的图。
视图(Mdl.Trained{1},“模式”,“图”)
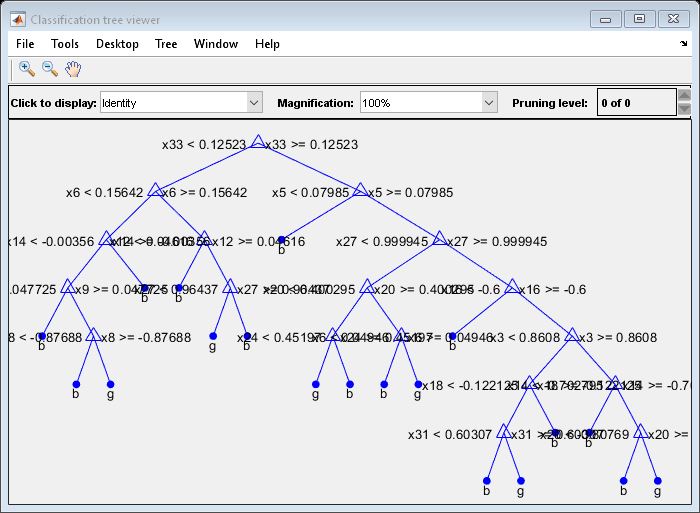
默认情况下,fitcensemble为袋装组合生长深决策树。
估计样本内误分类率。
L = resubLoss (Mdl)
L = 0
L是0,表示什么Mdl非常擅长对训练数据进行分类。
提示
对于一个袋装分类树的集合,训练有素的性质恩斯存储的细胞载体ens.NumTrainedCompactClassificationTree模型对象。用于树的文本或图形显示T在细胞载体中,输入
视图(实体。训练有素的{T})
扩展功能
您还可以从以下列表中选择网站:
