updateMetrics
描述
给定的流数据,updateMetrics措施的性能配置的朴素贝叶斯分类模型的增量学习(incrementalClassificationNaiveBayes对象)。updateMetrics存储性能指标的输出模型。
updateMetrics允许灵活的增量学习。后调用该函数来更新模型性能指标对传入的数据,您可以执行其他操作之前火车模型的数据。例如,您可以决定你是否需要培训模型基于业绩分配一个数据块。或者,您可以更新模型性能指标和训练模型数据到达时,在一个调用中,通过使用updateMetricsAndFit函数。
测量模型的性能在一个指定的一批数据,调用损失代替。
例子
增量模型的跟踪性能
火车通过使用朴素贝叶斯分类模型fitcnb,把它转换成增量学习,然后跟踪流数据的性能。
加载和数据预处理
载入人类活动数据集。随机洗牌数据。
负载humanactivityrng (1)%的再现性n =元素个数(actid);idx = randsample (n, n);X =壮举(idx:);Y = actid (idx);
细节的数据集,输入描述在命令行中。
朴素贝叶斯分类模型进行训练
适合朴素贝叶斯分类模型的随机样本数据的一半。
idxtt = randsample((真假),n, true);TTMdl = fitcnb (X (idxtt:), Y (idxtt))
TTMdl = ClassificationNaiveBayes ResponseName:‘Y’CategoricalPredictors::[]类名(1 2 3 4 5)ScoreTransform:“没有一个”NumObservations: 12053 DistributionNames: {1} x60细胞DistributionParameters: {5} x60细胞属性,方法
TTMdl是一个ClassificationNaiveBayes模型对象代表了一个传统的训练模式。
转换训练模型
传统训练分类模型转换为一个朴素贝叶斯分类模型的增量学习。
IncrementalMdl = incrementalLearner (TTMdl)
IncrementalMdl = incrementalClassificationNaiveBayes IsWarm: 1指标:[1 x2表]一会:(1 2 3 4 5)ScoreTransform:“没有一个”DistributionNames: {1} x60细胞DistributionParameters: {5} x60细胞属性,方法
增量模型是温暖的。因此,updateMetrics可以跟踪模型给定的性能指标数据。
跟踪性能指标
跟踪模型性能对其余数据使用updateMetrics函数。模拟数据流处理50观测一次。在每一次迭代:
调用
updateMetrics更新的累积和窗口最小成本模型的输入块的观察。覆盖前面的增量式模型更新的损失指标财产。注意,函数不符合模型的一部分数据,大部分是“新”的数据模型。存储的最小成本,意味着在第一节课第一次预测 。
%预先配置idxil = ~ idxtt;nil =总和(idxil);numObsPerChunk = 50;nchunk =地板(nil / numObsPerChunk);(nchunk mc = array2table (0, 2),“VariableNames”,(“累积”“窗口”]);mu11 = [IncrementalMdl.DistributionParameters {1} (1);0 (nchunk 1)];自= X (idxil:);Yil = Y (idxil);%增量式拟合为j = 1: nchunk ibegin = min (nil, numObsPerChunk * (j - 1) + 1);iend = min (nil, numObsPerChunk * j);idx = ibegin: iend;IncrementalMdl = updateMetrics (IncrementalMdl自(idx:), Yil (idx));mc {j:} = IncrementalMdl.Metrics {“MinimalCost”,:};mu11 (j + 1) = IncrementalMdl.DistributionParameters {1 1} (1);结束
IncrementalMdl是一个incrementalClassificationNaiveBayes模型对象,追踪观察的数据流模型的性能。
跟踪性能指标的情节和情节 。
t = tiledlayout (2, 1);nexttile h =情节(mc.Variables);xlim ([0 nchunk]) ylabel (“最小成本”传奇(h, mc.Properties.VariableNames) nexttile情节(mu11) ylabel (“\ mu_ {11}”)xlim ([0 nchunk])包含(t)“迭代”)
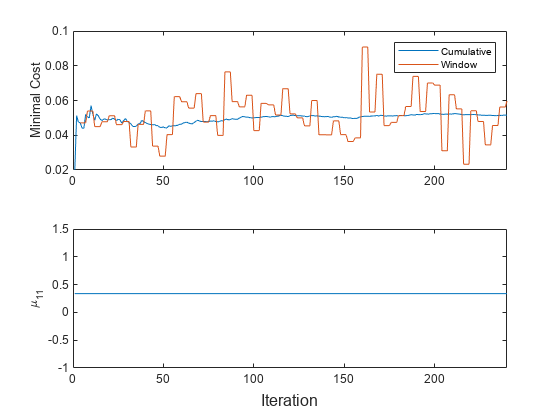
累计损失是稳定的,而窗口失去跳跃在整个培训。
不会改变,因为updateMetrics不符合模型的数据。
配置增量式模型跟踪性能指标和指定权重
创建一个朴素贝叶斯分类模型的增量学习通过调用incrementalClassificationNaiveBayes并指定最多5类的数据。指定跟踪错误分类错误率除了最小的成本。
Mdl = incrementalClassificationNaiveBayes (“MaxNumClasses”5,“指标”,“classiferror”);
Mdl是一个incrementalClassificationNaiveBayes模型。所有的属性是只读的。
确定模型是温暖通过查询模型属性。
isWarm = Mdl.IsWarm
isWarm =逻辑0
Mdl.IsWarm是0;因此,Mdl没有温暖。
确定数量的观察增量的拟合函数,如适合之前,必须处理测量模型的性能通过显示加热时间大小的指标。
numObsBeforeMetrics = Mdl.MetricsWarmupPeriod
numObsBeforeMetrics = 1000
载入人类活动数据集。随机洗牌数据。
负载humanactivityn =元素个数(actid);rng (1)%的再现性idx = randsample (n, n);X =壮举(idx:);Y = actid (idx);
细节的数据集,输入描述在命令行中。
假设一个固定的数据主题(Y< = 2)双数据从一个移动的质量问题。创建一个重量变量分配一个重量2从固定观察主体和1到一个移动的主题。
W = 1 (n, 1) + (Y < = 2);
实现增量学习在每个迭代中执行以下操作:
模拟数据流处理一块50的观察。
测量模型的性能指标的一部分使用
updateMetrics。指定相应的观察重量和覆盖输入模型。符合模型的一部分。指定相应的观察重量和覆盖输入模型。
商店 和错误分类错误率,看看他们在增量学习发展。
%预先配置numObsPerChunk = 50;nchunk =地板(n / numObsPerChunk);ce = array2table (0 (nchunk, 2),“VariableNames”,(“累积”“窗口”]);mu11 = 0 (nchunk, 1);%增量学习为j = 1: nchunk ibegin = min (n, numObsPerChunk * (j - 1) + 1);iend = min (n, numObsPerChunk * j);idx = ibegin: iend;Mdl = updateMetrics (Mdl X (idx:), Y (idx),“重量”W (idx));ce {j:} = Mdl.Metrics {“ClassificationError”,:};Mdl =适合(Mdl X (idx:), Y (idx),“重量”W (idx));mu11 (j) = Mdl.DistributionParameters {1} (1);结束
现在,Mdl是一个incrementalClassificationNaiveBayes模型对象培训中的所有数据流。
在增量学习看到参数如何演变,把它们在不同的瓷砖。
t = tiledlayout (2, 1);nexttile情节(mu11) ylabel (“\ mu_ {11}”)包含(“迭代”)轴紧nexttile情节(ce.Variables) ylabel (“ClassificationError”)参照线(numObsBeforeMetrics / numObsPerChunk,r -。)xlim ([0 nchunk])传说(ce.Properties.VariableNames)包含(t)“迭代”)
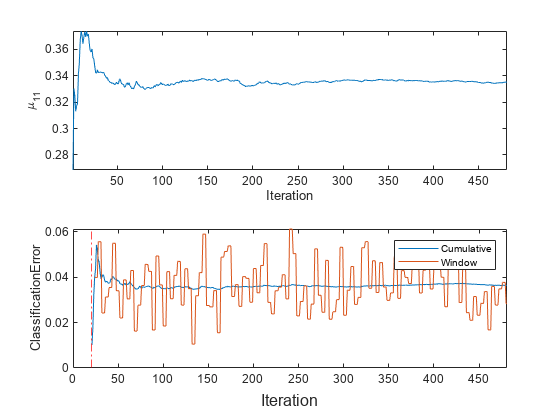
mdlIsWarm = numObsBeforeMetrics / numObsPerChunk
mdlIsWarm = 20
情节表明适合总是适合模型数据,updateMetrics没有跟踪指标后的分类错误,直到预热期(20块)。
执行条件的培训
逐步培养朴素贝叶斯分类模型只有当性能就会降低。
载入人类活动数据集。随机洗牌数据。
负载humanactivityn =元素个数(actid);rng (1)%的再现性idx = randsample (n, n);X =壮举(idx:);Y = actid (idx);
细节的数据集,输入描述在命令行中。
配置一个朴素贝叶斯分类模型的增量学习,以便将类的最大数量是5,跟踪性能指标包括误分类错误率,和指标窗口大小是1000。第一个1000年观测符合配置的模型。
Mdl = incrementalClassificationNaiveBayes (“MaxNumClasses”5,“MetricsWindowSize”,1000,…“指标”,“classiferror”);initobs = 1000;Mdl =适合(Mdl X (1: initobs,:), Y (1: initobs));
Mdl是一个incrementalClassificationNaiveBayes模型对象。
执行增量学习,条件合适,每个迭代遵循这个过程:
模拟数据流处理一块100年的观察。
更新模型性能传入的数据块。
符合模型的数据块只有当误分类错误率大于0.05。
当跟踪性能和装配,覆盖前面的增量式模型。
存储错误分类错误率的意思是第二等的预测 看他们如何训练中发展。
跟踪时
适合火车模型。
%预先配置numObsPerChunk = 100;地板nchunk = ((n - initobs) / numObsPerChunk);mu21 = 0 (nchunk, 1);ce = array2table (nan (nchunk, 2),“VariableNames”,(“累积”“窗口”]);训练= false (nchunk, 1);%增量式拟合为j = 1: nchunk ibegin = min (n, numObsPerChunk * (j - 1) + 1 + initobs);iend = min (n, numObsPerChunk * j + initobs);idx = ibegin: iend;Mdl = updateMetrics (Mdl X (idx:), Y (idx));ce {j:} = Mdl.Metrics {“ClassificationError”,:};如果ce {j 2} > 0.05 Mdl =适合(Mdl X (idx:), Y (idx));训练(j) = true;结束mu21 (j) = Mdl.DistributionParameters {1}, (1);结束
Mdl是一个incrementalClassificationNaiveBayes模型对象培训中的所有数据流。
模型的性能和 进化在训练,放到单独的瓷砖。
t = tiledlayout (2, 1);nexttile情节(mu21)在情节(找到(训练),mu21(训练),“r”。)xlim ([0 nchunk]) ylabel (“\ mu_ {21}”)传说(“\ mu_ {21}”,培训发生的,“位置”,“最佳”)举行从nexttile情节(ce.Variables) xlim ([0 nchunk]) ylabel (“误分类错误率”)传说(ce.Properties.VariableNames“位置”,“最佳”)包含(t)“迭代”)
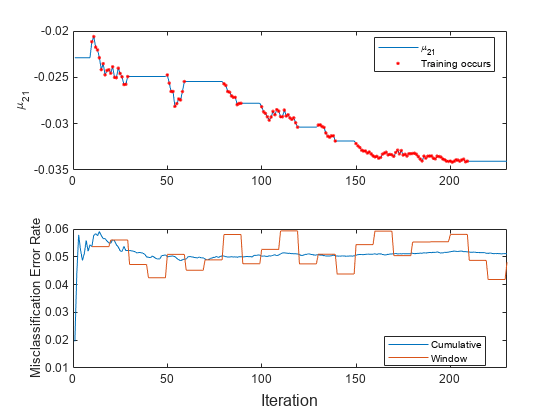
跟踪的情节 显示时间的常量值,在此期间,先前的观察窗内的损失最多是0.05。
输入参数
输出参数
提示
与传统的培训、增量学习可能没有一个单独的测试(抵抗)。因此,将每个传入的数据作为测试集,通过增量式模型和每个传入的块
updateMetrics在训练模型相同的数据使用适合。
算法
版本历史
介绍了R2021a