单向方差分析
单向方差分析简介
你可以使用这个函数anova1进行单向方差分析(ANOVA)。单因素方差分析的目的是确定一个因素的几个组(水平)的数据是否有一个共同的平均值。也就是说,单因素方差分析可以让你发现不同组的自变量是否对响应变量有不同的影响y.假设,一家医院想要确定这两种新的预约方法是否比旧的预约方法更能减少病人等待时间。在这种情况下,自变量为调度方法,响应变量为患者的等待时间。
单因素方差分析是一种简单的特殊情况线性模型.模型的单因素方差分析形式为
假设如下:
y我j是一个观察,在哪个我表示观测数,和j表示变量的不同组(级别)y.所有y我j是独立的。
αj的总体均值j组(水平或治疗)。
ε我j为均值为零,方差为常数的独立正态分布随机误差,即:ε我j~ N (0,σ2).
该模型也称为意味着模型.该模型假设y是常数αj加上误差分量ε我j.方差分析有助于确定这些常量是否都是相同的。
方差分析检验所有组均值相等的假设(
)反对另一种假设,即至少有一个群体与其他群体不同(
至少一个我和j).anova1 (y)测试矩阵中数据的列平均值的相等性y,其中每一列是不同的组,有相同数量的观察(即平衡设计)。anova1 (y组)测试组平均值的相等性,在集团,表示向量或矩阵中的数据y.在这种情况下,每个组或列可以有不同数量的观察(即,不平衡设计)。
方差分析是基于所有样本总体是正态分布的假设。众所周知,它对适度违反这一假设是稳健的。您可以使用正态图直观地检查正态假设(normplot).或者,您可以使用统计学和机器学习工具箱™函数之一来检查正态性:Anderson-Darling测试(adt),卡方拟合优度检验(chi2gof)、贾克-贝拉测试(制造商jbt),或Lilliefors测试(lillietest).
准备数据进行单因素方差分析
您可以以向量或矩阵的形式提供示例数据。
如果样本数据在向量中,
y,则必须使用集团输入变量:anova1 (y组).集团必须是数字向量、逻辑向量、类别向量、字符数组、字符串数组或字符向量的单元格数组,每个元素都有一个名称y.的anova1函数将y的相同值对应的值集团作为同一群体的一部分。例如,
当组有不同数量的元素时使用这种设计(不平衡方差分析)。
如果样本数据是一个矩阵,
y,提供组信息是可选的。如果不指定输入变量
集团,然后anova1处理每一列y作为一个单独的组,并评估各列的总体均值是否相等。例如,
当每组有相同数量的元素时使用这种设计形式(平衡方差分析)。
如果指定输入变量
集团,然后输入每个元素集团中对应列的组名y.的anova1函数将具有相同组名的列视为同一组的一部分。例如,



anova1忽略任何一个南值y.同样,如果集团包含空的或南值,anova1中对应的观察值忽略y.的anova1函数在忽略空或后,如果每组有相同数量的观察,则进行平衡方差分析南值。否则,anova1执行不平衡的方差分析。
执行单向方差分析
这个例子展示了如何执行单因素方差分析来确定来自几个组的数据是否有一个共同的平均值。
加载并显示示例数据。
负载霍格霍格
豪格=6×524 14 11 7 19 15 7 9 7 24 21 12 7 4 19 27 17 13 7 15 33 14 12 12 10 23 16 18 18 20
这些数据来自Hogg和Ledolter(1987)对牛奶运输中细菌数量的研究。矩阵的列霍格代表不同的出货量。这些列是随机从每批货物中挑选的牛奶盒中的细菌计数。
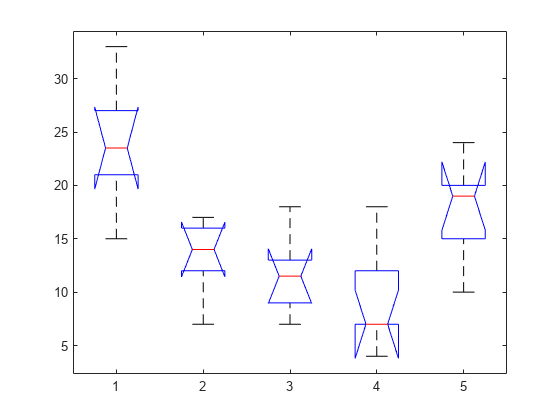
测试一些货物的计数是否高于其他货物。默认情况下,anova1返回两个数字。一个是标准的方差分析表,另一个是分组数据的箱形图。
[p(资源统计]= anova1(何克);
p
p = 1.1971 e-04
小p-值约为0.0001表示不同货物的细菌计数不相同。
你可以通过查看箱形图来确定均值是不同的。然而,凹槽比较的是中值,而不是平均值。有关此显示的更多信息,请参见箱线图.
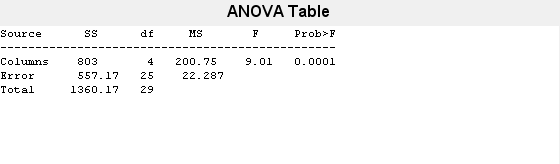
查看标准方差分析表。anova1将标准方差分析表保存为输出参数中的单元格数组资源描述.
资源描述
台=4×6单元阵列列1到5{‘源’}{“党卫军”}{“df”}{‘女士’}{' F '}{“列”}{[803.0000]}{[4]}{[200.7500]}{[9.0076]}{‘错误’}{[557.1667]}{[25]}{[22.2867]}{0 x0双}{“总”}{[1.3602 e + 03]} {[29]} {0 x0双}{0 x0双}列6{遇到的问题> F '} {[1.1971 e-04]} {0 x0双}{0 x0双}
保存F-变量中的统计值函数.
函数=台{2、5}
函数= 9.0076
查看必要的统计数据,以进行组平均数的多个两两比较。anova1将这些统计信息保存在结构中统计数据.
统计数据
统计=结构体字段:Gnames: [5x1 char] n: [6 666 6] source: 'anova1' means: [23.8333 13.3333 11.6667 9.1667 17.8333] df: 25 s: 4.7209
方差分析拒绝了所有组均值相等的无效假设,所以你可以使用多重比较来确定哪些组均值与其他组均值不同。要进行多次比较测试,请使用该函数multcompare,接受统计数据作为输入参数。在这个例子中,anova1拒绝无效假设,即所有四批货物的平均细菌计数彼此相等,即:
.
执行多重比较测试,以确定在平均细菌计数方面,哪些发货与其他发货不同。
multcompare(统计)
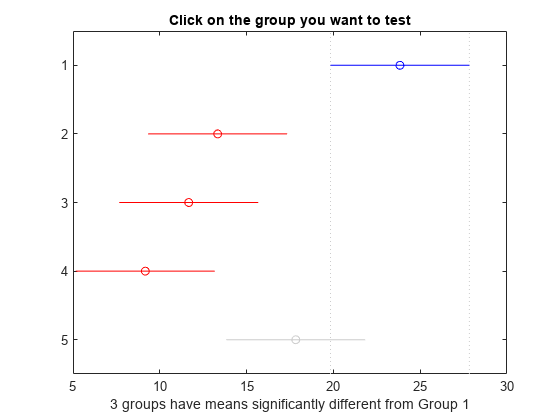
ans =10×61.0000 2.0000 2.4953 10.5000 18.5047 0.0059 1.0000 3.0000 4.1619 12.1667 20.1714 0.0013 1.0000 4.0000 6.6619 14.6667 22.6714 0.0001 1.0000 5.0000 -2.0047 6.0000 6.0047 0.2119 2.0000 3.0000 -6.3381 1.6667 9.6714 0.9719 2.0000 4.0000 -3.8381 4.1667 12.1714 0.5544 2.0000 5.0000 -12.5047 -4.5000 3.5047 0.4806 3.0000 4.0000 -5.5047 2.5000 10.50470.8876 3.0000 5.0000 -14.1714 -6.1667 1.8381 0.1905 4.0000 5.0000 -16.6714 -8.6667 -0.6619 0.0292
前两列显示了哪些组的平均值相互比较。例如,第一行比较组1和组2的平均值。最后一列显示p测试的-值。的p- 0.0059、0.0013和0.0001表示第一批装运的牛奶中的平均细菌计数与第二、第三和第四批装运的不同。的p-value为0.0292表示第四次发货的牛奶中的平均细菌计数与第五次发货的牛奶中的平均细菌计数不同。这个程序不能拒绝假设,即另一组的方法是不同的。
该图也说明了同样的结果。蓝色条表示第一组平均值的比较区间,与第二、第三、第四组平均值的比较区间不重叠,红色部分表示。第五组平均值的比较区间为灰色,与第一组平均值的比较区间重叠。因此,第一组和第五组的组均值彼此之间没有显著差异。
数学细节
对组内差异的方差分析测试意味着将数据的总变异分为两个部分:
组均值与总均值的变异,即: (组间变异),其中 是组的样本均值吗j, 为总体样本均值。
每一组的观察值与他们的组平均值估计值的差异, (组内变异)。
也就是说,方差分析将总平方和(SST)分解为组间效应平方和(SSR)和误差平方和(SSE)。
在哪里nj样品尺寸是多少jth集团,j= 1, 2,…k.
然后用方差分析比较组间差异和组内差异。如果组间变异与组内变异之比显著高,则可以得出组间平均数显著不同的结论。你可以用一个测试统计量来衡量F分布(k- 1,N- - - - - -k)自由度:
在哪里MSR是均方处理,均方误差为均方误差,k是组数,和N为观测总数。如果p价值的F-统计量小于显著性水平,则检验拒绝所有组均值相等的原假设,并得出组均值中至少有一个与其他组均值不同的结论。最常见的显著性水平为0.05和0.01。
方差分析表
方差分析表捕获了模型的可变性的来源,F-检验此变异的显著性的统计量,以及p-值,用于决定此可变性的重要性。的p返回的值anova1取决于随机扰动的假设ε我j在模型方程中。为p-值要正确,这些扰动必须是独立的、正态分布的,并且具有常数方差。标准的方差分析表是这样的:

anova1返回标准的方差分析表作为有六列的单元格数组。
| 列 | 定义 |
|---|---|
源 |
可变性的来源。 |
党卫军 |
每个源的平方和。 |
df |
与每个源相关的自由度。假设N是观察总数和k为组的个数。然后,N- - - - - -k为组内自由度(错误),k- 1为组间自由度(列),N- 1为总自由度:N- 1 = (N- - - - - -k) + (k- 1)。 |
女士 |
每个源的均方,也就是比值SS / df. |
F |
F-statistic,即均方比。 |
概率F > |
p-value,也就是F-statistic可以取一个大于计算的test-statistic值的值。anova1从CDF推导出这个概率F分布。 |
方差分析表的行显示了数据的可变性,除以来源。
| 行(源) | 定义 |
|---|---|
组或列 |
变异性由于组间的差异意味着(变异性)之间的组) |
错误 |
变异性由于每组数据与组均值之间的差异(变异性)在组) |
总计 |
总变化 |
参考文献
吴昌芳,M. Hamada。实验:规划、分析和参数设计优化, 2000年。
Neter, J., M. H. Kutner, C. J. Nachtsheim, W. Wasserman.第四版。应用线性统计模型.欧文出版社,1996年。
另请参阅
anova1|multcompare|kruskalwallis
相关的话题
你也可以从以下列表中选择一个网站:
