 克利夫角:克利夫莫勒的数学和计算
克利夫角:克利夫莫勒的数学和计算 MATLAB博客
MATLAB博客 用MATLAB进行图像处理
用MATLAB进行图像处理 Simulin金宝appk上的Guy
Simulin金宝appk上的Guy 人工智能
人工智能 开发区域
开发区域 Stuart的MATLAB视频
Stuart的MATLAB视频 头条新闻背后
头条新闻背后 本周文件交换选择
本周文件交换选择 汉斯谈物联网
汉斯谈物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 Matlabユザコミュニティ
Matlabユザコミュニティ 创业公司、加速器和企业家
创业公司、加速器和企业家 自治系统
自治系统深度学习在行动-第1部分
大家好!请允许我简单介绍一下我自己。我叫约翰娜史蒂夫允许我不时接管博客,谈论深度学习。
今天我想开始一个系列,叫做:
演示:看图说词 画图游戏指的是一个人或团队画一个物体,另一个人或团队试着猜这个物体是什么。 Pictionary demo的开发者其实是我!这个演示是MathWorks开发人员在内部留言板上发布的: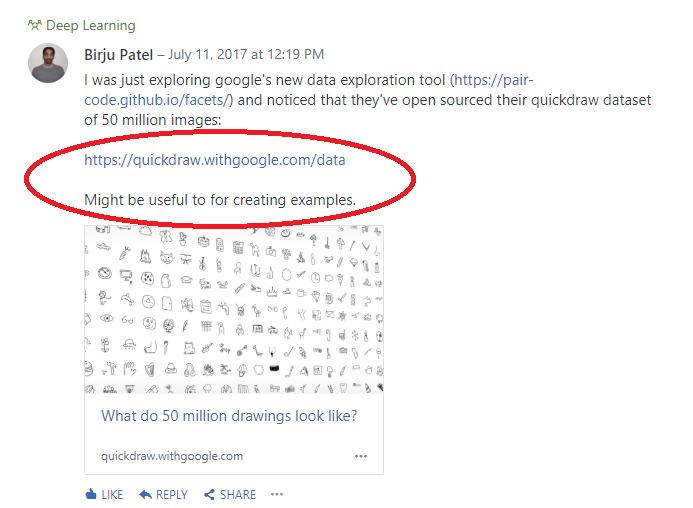 我们已经有了例子用MNIST数据集进行笔迹检测,但这是对这个概念的独特诠释。因此,创建一个Pictionary示例的想法诞生了。
读取数据集中的图像
第一个挑战(说实话,这个例子中最难的部分)是阅读图像。每张图像都包含一个对象类别的许多图纸,例如,有一个“蚂蚁”类别中有数千只手绘蚂蚁存储在JSON文件中。文件的每一行看起来像这样:
我们已经有了例子用MNIST数据集进行笔迹检测,但这是对这个概念的独特诠释。因此,创建一个Pictionary示例的想法诞生了。
读取数据集中的图像
第一个挑战(说实话,这个例子中最难的部分)是阅读图像。每张图像都包含一个对象类别的许多图纸,例如,有一个“蚂蚁”类别中有数千只手绘蚂蚁存储在JSON文件中。文件的每一行看起来像这样:
该文件的想法是捕捉单个的“笔画”,即在没有举起钢笔的情况下所画的内容。让我们以Stroke #1为例:
图像上的X和Y值如下图所示:
然后我们玩了一个“连接点”的小游戏,我们得到了像画一样的第一笔。用一个叫做iptui.intline的函数在MATLAB中连接这些点是相当容易的
 我们对剩下的笔画也这样做,我们得到:
我们对剩下的笔画也这样做,我们得到:
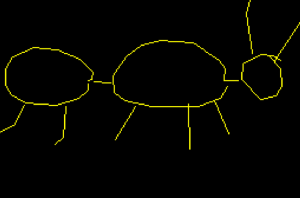 终于!一幅有点像蚂蚁的画。
现在我们可以从这些x,y点创建图像,我们可以创建一个函数,并快速地为文件中的所有蚂蚁和多个类别重复此操作。
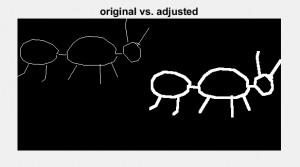
现在,这个数据集假设人们是用铅笔或其他细的东西画的,因为线条的粗细只有1个像素。我们可以用图像处理工具,如图像膨胀,快速改变图纸的厚度。我想象人们会在有记号笔的白板上玩这个游戏,所以在粗线上训练会有助于这个假设。
终于!一幅有点像蚂蚁的画。
现在我们可以从这些x,y点创建图像,我们可以创建一个函数,并快速地为文件中的所有蚂蚁和多个类别重复此操作。
现在,这个数据集假设人们是用铅笔或其他细的东西画的,因为线条的粗细只有1个像素。我们可以用图像处理工具,如图像膨胀,快速改变图纸的厚度。我想象人们会在有记号笔的白板上玩这个游戏,所以在粗线上训练会有助于这个假设。
 对于这个示例,我提取了5000张训练图像和500张测试图像。文件中还有很多(很多很多!)更多的示例图像,所以如果您愿意,可以随意增加这些数字。
创建和培训网络
现在我们的数据集已经准备好了,让我们开始训练。
这是网络的结构:
对于这个示例,我提取了5000张训练图像和500张测试图像。文件中还有很多(很多很多!)更多的示例图像,所以如果您愿意,可以随意增加这些数字。
创建和培训网络
现在我们的数据集已经准备好了,让我们开始训练。
这是网络的结构:
我承认,这是一个相当无聊的图层图因为它都是一条直线,但如果你在处理DAG网络,你可以很容易地看到一个复杂网络的连接。
我用NVIDIA P100 GPU训练了大约20分钟。搁置的测试图像的准确度约为90%。对于自动驾驶场景,我需要回过头来改进算法。在我看来,对于一个画图猜词游戏来说,这是一个完全可以接受的数字。
 其中一件事是蚂蚁和手表容易混淆分类器。这似乎是合理的混淆。如果我们把酒杯和蚂蚁搞混了,那就有问题了。
我们的Pictionary分类器出现错误的原因有两个:
其中一件事是蚂蚁和手表容易混淆分类器。这似乎是合理的混淆。如果我们把酒杯和蚂蚁搞混了,那就有问题了。
我们的Pictionary分类器出现错误的原因有两个:
 我敢说,这些蚂蚁中至少有18只根本不应该被称为蚂蚁。为我的分类器辩护,假设你在玩画图猜词游戏,有人画了这个:
我敢说,这些蚂蚁中至少有18只根本不应该被称为蚂蚁。为我的分类器辩护,假设你在玩画图猜词游戏,有人画了这个:
你称它为蚂蚁的可能性有多大?如果计算机将其归类为雨伞,这真的是一个错误吗?
在新图像上尝试分类器
现在,这个例子的全部意义在于看看新图像在现实生活中会是什么样子。我画了一只蚂蚁……
 ...训练过的模型现在可以告诉我它认为这是什么。让我们再加入一个信心评级。
...训练过的模型现在可以告诉我它认为这是什么。让我们再加入一个信心评级。
 我使用了图像处理创建的分割函数,它可以找到我绘制的对象,并将黑色翻转为白色,将白色翻转为黑色。
看来我的画图技能还不错啊!
这个代码是打开的FileExchange,您可以在网络研讨会我和我的同事加布里埃尔·哈一起录制。
如果你有任何问题,请在下方评论。下次我将与MathWorks工程师讨论如何使用cnn进行点云分割!
我使用了图像处理创建的分割函数,它可以找到我绘制的对象,并将黑色翻转为白色,将白色翻转为黑色。
看来我的画图技能还不错啊!
这个代码是打开的FileExchange,您可以在网络研讨会我和我的同事加布里埃尔·哈一起录制。
如果你有任何问题,请在下方评论。下次我将与MathWorks工程师讨论如何使用cnn进行点云分割!
“深度学习在行动:
在MathWorks创建的酷项目 ” 这篇文章的目的是让您深入了解我们在MathWorks所做的工作:我将展示一些演示,并让您访问代码,甚至可能发布一两个视频。 今天的演示叫做看图说词”这是系列文章的第一篇,包括:- 使用cnn的三维点云分割
- GPU编码器
- 年龄检测
- 也许还有更多!
演示:看图说词 画图游戏指的是一个人或团队画一个物体,另一个人或团队试着猜这个物体是什么。 Pictionary demo的开发者其实是我!这个演示是MathWorks开发人员在内部留言板上发布的:
 我们已经有了例子用MNIST数据集进行笔迹检测,但这是对这个概念的独特诠释。因此,创建一个Pictionary示例的想法诞生了。
读取数据集中的图像
第一个挑战(说实话,这个例子中最难的部分)是阅读图像。每张图像都包含一个对象类别的许多图纸,例如,有一个“蚂蚁”类别中有数千只手绘蚂蚁存储在JSON文件中。文件的每一行看起来像这样:
我们已经有了例子用MNIST数据集进行笔迹检测,但这是对这个概念的独特诠释。因此,创建一个Pictionary示例的想法诞生了。
读取数据集中的图像
第一个挑战(说实话,这个例子中最难的部分)是阅读图像。每张图像都包含一个对象类别的许多图纸,例如,有一个“蚂蚁”类别中有数千只手绘蚂蚁存储在JSON文件中。文件的每一行看起来像这样:
{“单词”:“蚂蚁”,“countrycode”:“我们”,“时间戳”:“2017-03-27 00:14:57.31033UTC”、“认可”:真的,”key_id”:“5421013154136064”、“画”:[[[27日,17日,16日,21日,34岁,50岁,49岁,34岁,23日,17],[47,58岁的73、81、84、67年,54岁,46岁,47岁,51]],[[22日0],[51岁,18]],[[41岁,46岁,43],[45 11 0]],[[53,65,64,69,91119135148159158149126,87,68,62],[68、68、58岁的51岁,36岁,34岁,38岁,48岁,64,78,85,90,90,83,73]],[[161175],[70、69]],[[180177176187206226244250250245233207188180180],[68、67、61、50、42岁,40岁,48岁,今年58岁,72,80,87,89,83,76,71]],[[73、61],[85113]],[[95、94],[88126]],[[140157],[90118]],[[199201208],[90116122]],[[234242年,255], [89105112]]]}
你能看到图像吗?我也不。图像包含x,y连接点。如果我们从文件中取出x,y点,我们可以看到绘图开始成型。
| 中风 | X值 | Y值 |
| 1 | 27日,17日,16日,21日,34岁,50岁,49岁,34岁,23岁,17岁 | 47、58、73、81、84、67年,54岁,46岁,47岁的51 |
| 2 | 22日0 | 51岁,18岁 |
| 3. | 41岁,46岁,43岁 | 45岁,11日,0 |
| 4 | 53, 65, 64, 69, 91119135148159158149126, 87, 68, 62 | 58 68年,68年,51岁,36岁,34岁,38岁,48岁,64,78,85,90,90,83,73 |
| 完整的图片: | 放大: |

输入文件中的X Y值用粉色表示 |

同样的图片,只是放大了 |
>> help iptui.intline [X, Y] = intline(X1, X2, Y1, Y2)用整数坐标计算连接(X1, Y1)和(X2, Y2)的线段的近似值。

绘制的X、Y值(粉色)和连接它们的“笔画”(黄色)

黄色只是为了视觉上的强调。实际图像将具有黑色背景和白色绘图。
larger_im = imdilate(im2,strel('Disk',3));
当我们清理东西的时候,让我们也把图像居中:
 对于这个示例,我提取了5000张训练图像和500张测试图像。文件中还有很多(很多很多!)更多的示例图像,所以如果您愿意,可以随意增加这些数字。
创建和培训网络
现在我们的数据集已经准备好了,让我们开始训练。
这是网络的结构:
对于这个示例,我提取了5000张训练图像和500张测试图像。文件中还有很多(很多很多!)更多的示例图像,所以如果您愿意,可以随意增加这些数字。
创建和培训网络
现在我们的数据集已经准备好了,让我们开始训练。
这是网络的结构:
layers = [imageInputLayer([256 256 1]) convolution2dLayer(3,16,“填充”,1) maxPooling2dLayer(2,“步”32岁的,2)convolution2dLayer (3“填充”,1) maxPooling2dLayer(2,“步”64年)convolution2dLayer(3日,“填充”,1) batchNormalizationLayer reluLayer fullyConnectedLayer(5) softmaxLayer classificationLayer];我是怎么选择这个结构的?很高兴你发问。我从那些已经建立了网络的人那里偷来的。这个特定的网络结构在MNIST数据集上的准确率为99%,所以我认为这是这些手写图纸的一个很好的起点。 下面是用这段代码创建的一个方便的图:
lgraph = layerGraph(图层);情节(层)

predLabelsTest = net. category (uint8(imgDataTest));testAccuracy = sum(predLabelsTest == labelsTest') / numel(labelsTest)
testAccuracy = 0.8996调试网络 让我们深入研究精度,以更深入地了解经过训练的网络。 观察特定类别预测的一种方法是创建一个混淆矩阵。一个非常简单的选择是创建一个热图。这类似于一个混淆矩阵——假设你在每个类别中有相同数量的图像——我们做的是:每个类别有500个测试图像。
可视化预测的标签与实际不符的地方。tt = table(predLabelsTest, categorical(labelsTest'),'VariableNames',{' expected ','Actual'});图(“名字”,“混淆矩阵”);热图(tt,“实际”,“预测”);
 其中一件事是蚂蚁和手表容易混淆分类器。这似乎是合理的混淆。如果我们把酒杯和蚂蚁搞混了,那就有问题了。
我们的Pictionary分类器出现错误的原因有两个:
其中一件事是蚂蚁和手表容易混淆分类器。这似乎是合理的混淆。如果我们把酒杯和蚂蚁搞混了,那就有问题了。
我们的Pictionary分类器出现错误的原因有两个:
- 的人猜测无法识别物体,还是
- 的人画不能很好地描述物体。
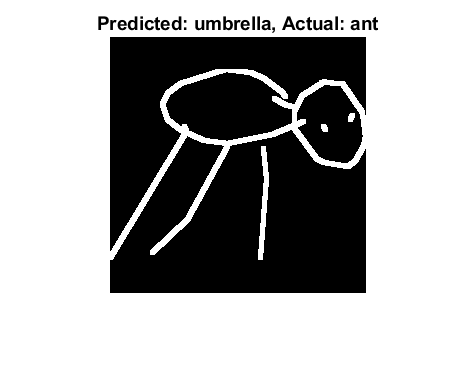
找出预测标签与实际不符的时间。idx = find(prelabelstest ~= labelsTest');Loser_ants = idx(idx < 500);蒙太奇(imgDataTest (:,: 1 loser_ants));
 我敢说,这些蚂蚁中至少有18只根本不应该被称为蚂蚁。为我的分类器辩护,假设你在玩画图猜词游戏,有人画了这个:
我敢说,这些蚂蚁中至少有18只根本不应该被称为蚂蚁。为我的分类器辩护,假设你在玩画图猜词游戏,有人画了这个:
%从一堆图像中选择一个ii = 169 img = squeeze(uint8(imgDataTest(:,:,1,ii)));actualLabel = labelsTest(ii);predictedLabel = net. category (img);imshow (img, []);标题([的预测:char (predictedLabel)', Actual: 'char (actualLabel)))

我自己画的蚂蚁
S =快照(网络摄像头);myDrawing = segmentmage (s(:,:,2));myDrawing = imresize(myDrawing,[256,256]);确保这是正确的大小处理[predval,conf] = net. category (uint8(myDrawing));imshow (myDrawing);标题(string (predval) + sprintf (“% .1f % %”马克斯(参看)* 100));
 我使用了图像处理创建的分割函数,它可以找到我绘制的对象,并将黑色翻转为白色,将白色翻转为黑色。
看来我的画图技能还不错啊!
这个代码是打开的FileExchange,您可以在网络研讨会我和我的同事加布里埃尔·哈一起录制。
如果你有任何问题,请在下方评论。下次我将与MathWorks工程师讨论如何使用cnn进行点云分割!
我使用了图像处理创建的分割函数,它可以找到我绘制的对象,并将黑色翻转为白色,将白色翻转为黑色。
看来我的画图技能还不错啊!
这个代码是打开的FileExchange,您可以在网络研讨会我和我的同事加布里埃尔·哈一起录制。
如果你有任何问题,请在下方评论。下次我将与MathWorks工程师讨论如何使用cnn进行点云分割!
- 类别:
- 深度学习








评论
如欲留言,请点击在这里登录您的MathWorks帐户或创建一个新帐户。