 Cleve的角落:数学和计算上的Clyver
Cleve的角落:数学和计算上的Clyver Loren on the Art of MATLAB
Loren on the Art of MATLAB Steve on Image Processing with MATLAB
Steve on Image Processing with MATLAB 在simuli金宝appnk上的家伙
在simuli金宝appnk上的家伙 深度学习
深度学习 开发人员区
开发人员区 Stuart’s MATLAB Videos
Stuart’s MATLAB Videos Behind the Headlines
Behind the Headlines File Exchange Pick of the Week
File Exchange Pick of the Week 汉斯在某地面
汉斯在某地面 学生休息室
学生休息室 初创公司,加速器和企业家
初创公司,加速器和企业家 MATLAB Community
MATLAB Community matlabユーザーコミュニティー
matlabユーザーコミュニティー机器人迅速教导自己使用强化学习行走
A team of researchers from the University of Southern California’sValero Labbuilt a relatively simple robotic limb that accomplished something simply amazing: The 3-tendon, 2-joint robotic leg taught itself how to move. Yes, autonomous learning via trial and error.
该团队由Francisco Valero-Cuevas教授和博士生Ali Marjaninejad领导。他们的研究是在3月份问题的封面上出现的自然机器智力。
The robotic limb is not programmed for a specific task. It learns autonomously first by modeling its own dynamic properties and then using a form of artificial intelligence (AI) known as reinforcement learning. Instead of weeks upon weeks of coding, the robotic leg is able to teach itself to move in just minutes.
Inspired by nature
机器人长期以来一直受到自然的启发,因为让我们面对它,母亲自然花了很长时间完善她的设计。今天,我们看到机器人像蜘蛛一样走路and underwater robotsinspired by sea snakes。
Bioinspiration also affects the way robots “think,” thanks to AI that mimics the way living organisms’ nervous systems process information. For example, artificial neural networks (ANNs) have been used tocopy an insect’s brain structureto improve computer recognition of handwritten numbers.
For this project, the design took its cues from nature, both for the physical design of the leg and for the AI that helped the leg “learn” to walk. For the physical design, this robotic leg used a tendon architecture, much like the muscle and tendon structure that powers animals’ movements. The AI also took its inspiration from nature, using an ANN to help the robot learn how to control its movements. Reinforcement learning then utilized the understanding of the dynamics to accomplish the goal of walking on a treadmill.
Reinforcement learning and “motor babbling”
通过将Motor Babbilly与强化学习结合,系统尝试随机动作,并通过运动结果来学习系统的性质。对于这项研究,团队开始让系统在随机或马达布布上播放,以了解肢体的属性及其动态。
In aninterview withPC杂志, Marjaninejad stated, “We then give [the system] a reward every time it approaches good performance of a given task. In this case, moving the treadmill forward. This is called reinforcement learning as it is similar to the way animals respond to positive reinforcement.”
The resulting algorithm is called G2P, (general to particular). It replicates the “general” problem that biological nervous systems face when controlling limbs by learning from the movement that occurs when a tendon moves the limb. It is followed by reinforcement (rewarding) the behavior that is “particular” to the task. In this case, the task is successfully moving the treadmill. The system creates a “general” understanding of its dynamics through motor babbling and then masters a desired “particular” task by learning from every experience, or G2P.
结果令人印象深刻。G2P算法可以在仅5分钟的非结构化播放后自行学习新的步行任务,然后适应其他任务,无需任何额外的编程。
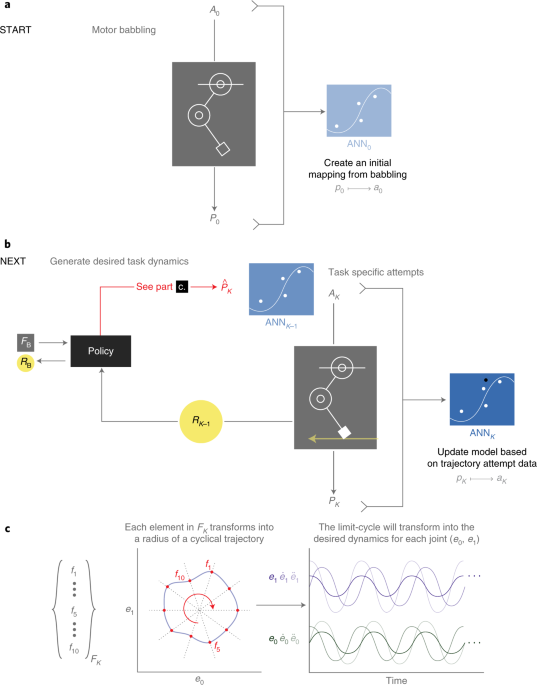
G2P算法。图片信用:Marjaninejad,等。
ANN使用来自Motor Babling的结果,在输入(移动运动学)和输出(电机激活)之间创建逆图。ANN根据在加强学习阶段期间对所需结果进行磨练的每次尝试更新模型。它记得每次最佳结果,如果新的输入创建更好的结果,它会使用新设置覆盖模型。
Generating and training of ANNs was carried out using MATLAB and the深度学习工具箱。The MATLAB code is available on the teams’GitHub。The reinforcement learning algorithm was also written inMATLAB。下面可以在机器人腿和训练结果的视频。





评论
要发表评论,请点击此处