克里夫的角落:克里夫硅藻土在数学和计算
克里夫的角落:克里夫硅藻土在数学和计算 MATLAB的博客
MATLAB的博客 史蒂夫与MATLAB图像处理
史蒂夫与MATLAB图像处理 人在仿真软件金宝app
人在仿真软件金宝app 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 文件交换的选择
文件交换的选择 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー 创业、加速器,和企业家
创业、加速器,和企业家
子集选择和正规化
本周理查德·威利从技术博客营销将客人关于子集选择和正规化。本周的博客是出于共同的挑战,发生在应用曲线拟合。
- 第一个挑战是如何建立精确的预测模型自变量时表现出很强的相关性。在许多情况下可以改进一个普通最小二乘回归的结果如果你减少预测的数量,另外,缩小系数值为零。
- 第二个挑战涉及限制时生成一个精确的预测模型对预测你处理的数量。例如,假设您需要模型嵌入到控制器。你有20个可能的预测因素可供选择,但你只有足够的内存允许8个独立变量。
这篇文章将显示两种不同的技术来解决这些相关的挑战。第一组的技术是基于组合特征选择和交叉验证。第二组技术是使用正则化算法和岭回归一样,套索和弹性。所有这些算法中可以找到统计工具箱。
内容
创建一个数据集
首先,我要生成一个数据集,故意设计出来很难适合使用传统线性回归。数据集有三个特征呈现线性回归的挑战
- 数据集是非常“宽”。有相对大量的(可能)预测相比,观察的数量。
- 预测是强烈相关
- 有大量噪声的数据集
清晰的所有clc rng (1998);
创建八X变量。每个变量的均值就等于零。
μ= [0 0 0 0 0 0 0 0];
变量是相关的。协方差矩阵被指定为
我= 1:8;矩阵= abs (bsxfun (@minus,我,我));协方差= repmat(5 8 8)。^矩阵;
使用这些参数来生成一组多元正态随机数。
X = mvnrnd(μ,协方差,20);
创建一个超平面,描述Y = f (X)和添加噪声向量。注意,只有三个八个预测因子的系数值> 0。这意味着五的八个预测因子为零对实际模型的影响。
β= [3;1.5;0;0;2;0;0;0);ds =数据集(β);Y = X *β+ 3 * randn (20, 1);
对于那些有兴趣,这个例子是出于罗伯特在套索Tibshirani 1996年的经典文章:
Tibshirani, r (1996)。通过套索回归收缩和选择。j .皇家。中央集权。Soc B。,Vol. 58, No. 1, pages 267-288).
我们的模型Y = f (X)用普通最小二乘回归。我们首先使用传统的线性回归模型Y = f (X)和比较的系数估计的回归模型已知向量β。
b =回归(Y、X);ds。线性= b;disp (ds)
β线性0 3 0 3.5819 1.5 0.44611 0.92272 -0.42067 0.17123 -2.5195 4.7091 -0.84134 - 2 0 0 0
正如所料,回归模型表现很差。
- 所有八个预测因子的回归估计系数值。客观地讲,我们“知道”,五个系数应该是零。
- 此外,系数的估计是非常远离真正的价值。
让我们看看如果我们能改进这些结果使用了一种叫做“所有可能的子集回归”。首先,我要产生255不同的regession模型包含所有可能的combinate的八个预测因子。接下来,我要测量的准确性使用交叉验证均方误差产生的回归。最后,我要选择产生最精确的回归模型结果和比较原来的回归模型。
创建索引的回归子集。
指数= dec2bin (1:255);指数=指数= =' 1 ';结果=双(指数);结果:9)= 0(长度(结果),1);
生成回归模型。
为i = 1:长度(指数)foo =指数(我:);rng (1981);regf = @ (XTRAIN YTRAIN XTEST) (XTEST *回归(YTRAIN XTRAIN));结果(我,9)= crossval (mse的X (: foo), Y,“kfold”5,“predfun”,regf);结束
输出的均方误差。我将向您展示的前几。
指数= sortrows(结果,9);指数(1:10,:)
ans = 1到5列1 1 0 0 1 1 1 0 1 1 1 0 1 0 1 1 1 0 0 1 1 0 0 0 1 1 1 0 1 1 1 0 0 1 1 1 0 0 0 1 1 0 1 0 1 1 0 0 1 1列6至9年1 0 0 10.239 10.533 1 0 0 1 0 0 0 0 0 10.615 10.976 1 0 0 0 0 0 11.062 11.257 11.938 11.641 1 0 0 0 0 0 0 0 0 0 0 0 12.068 12.249
比较结果
β=回归(Y、X(:逻辑(索引(1:8))));子集= 0 (8,1);ds。子集=子集;ds.Subset(逻辑(索引(1:8)))=β;disp (ds)
β3线性子集-0.84134 0.92272 3.5819 3.4274 1.5 0.44611 1.1328 0 0 0 0 2 0.17123 4.7091 - 4.1048 -2.5195 - -2.0063 0 0 0 -0.42067 0
结果相当惊人。
- 我们的新模型只包括4预测。变量3、4、7和8取消了自回归模型。此外,exluded的变量是那些我们“知道”应该是0。
- 同样意味深长的是,被估计的系数所得的回归模型更接近“真实”的值。
所有可能的子集回归似乎已经生成了一个更好的模型。这R ^ 2这个回归模型价值不如原来的线性回归;然而,如果我们试图从一个新的数据集生成预测,我们认为这个模型也表现得明显更好。
执行一个模拟
它总是危险的依赖一个观察的结果。如果我们改变的噪声向量,我们用来产生原始数据集可能得到完全不同的结果。下一个代码块会重复原来的实验一百次,每次添加在不同噪声向量。我们的输出是一个条形图显示频率每个不同的变量是包含在最终的模型。我用并行计算来加快速度虽然你可能在串行执行这个(较慢)。
matlabpool开放sumin = 0 (1,8);parforj = 1:10 0μ= [0 0 0 0 0 0 0 0];β= [3;1.5;0;0;2;0;0;0);我= 1:8; matrix = abs(bsxfun(@minus,i',i)); covariance = repmat(.5,8,8).^matrix; X = mvnrnd(mu, covariance, 20); Y = X * Beta + 3 * randn(size(X,1),1); index = dec2bin(1:255); index = index ==' 1 ';结果=双(指数);结果:9)= 0(长度(结果),1);为k = 1:长度(指数)foo =指数(k,:);regf = @ (XTRAIN YTRAIN XTEST) (XTEST *回归(YTRAIN XTRAIN));结果(k, 9) = crossval (mse的X (: foo), Y,“kfold”5,…“predfun”,regf);结束%输出的均方误差指数= sortrows(结果,9);sumin = sumin +指数(1:8);结束% parformatlabpool关闭
matlabpool开始使用“local4”配置…连接到3实验室。发送停止信号的所有实验室……停止了。
%的阴谋的结果。栏(sumin)
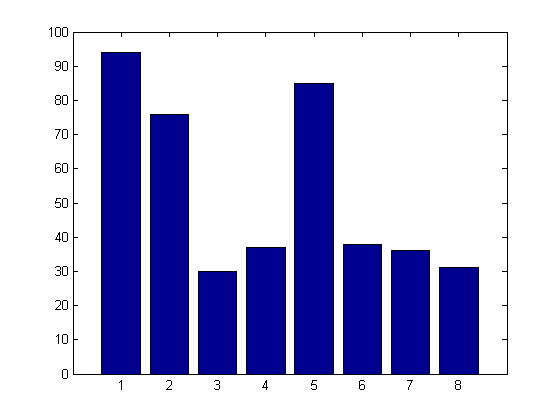
结果清楚地表明,“所有可能的子集选择”做一个很好的工作驱动我们的模型识别的关键变量。变量1、2和5出现在大多数的模型。个人干扰工作进入模型,然而,它们的频率高达附近是没有真正的预测因子。
引入序列特征选择
所有可能的子集选择遭受从一个巨大的限制。这是计算上不可行的将这种技术应用到数据集,其中包含大量的(潜在的)预测。我们的第一个例子有八个可能的预测因素。测试所需的所有可能的子集生成(2 ^ 8)1 = 255个不同的模型。假设我们和20个可能的预测评估模型。所有可能的子集需要使用测试1048575个不同的模型。与40个预测我们会看十亿种不同的组合。
连续的特征选择是一种更现代的方法,试图定义一个智能的搜索空间路径。反过来,这应该让我们识别一套好的cofficients但仍确保问题是计算上可行。
连续的特征选择工作如下:
- 首先测试每一个可能的预测一次。确定生成的单一预测最准确的模型。这个预测是自动添加到模型中。
- 接下来,一次一个,每次添加剩余的预测模型,包括最好的变量。识别变量,提高了模型的精度。
- 测试两个模型的统计学意义。如果新模式不是原始模型更准确,停止的过程。但是,如果新模型是统计上更重要的,最好去寻找第三个变量。
- 重复这个过程,直到你不能确定一个新变量有显著影响的模型。
%下面的代码将向您展示如何使用连续的特性%选择显著解决一个更大的问题。
生成数据集
清晰的所有clc rng (1981);Z12 = randn(100年,40);Z1 = randn (100 1);X = Z12 + repmat (Z1, 1 40);B0 = 0 (10, 1);B1 = 1 (10, 1);β= 2 * vertcat (B0, B1, B0, B1);ds =数据集(β);Y = X *β+ 15 * randn (100 1);
使用线性回归模型来适应。
b =回归(Y、X);ds。线性= b;
使用连续的特性选择合适的模型。
选择= statset (“显示”,“通路”);有趣= @ (x0, y0 (x1, y1)规范(y1-x1 * (x0 \ y0)) ^ 2;%残差平方和,历史上[]= sequentialfs(有趣,X, Y,“简历”5,“选项”选择)
开始向前连续特征选择:初始列包括:没有列不能包括:步骤1,添加列26日标准价值868.909步骤2,添加列31日标准价值566.166步骤3,添加列9,则价值425.096步骤4,添加列35,标准价值369.597步骤5,添加列16日标准价值314.445步骤6,添加列5、准则值283.324步骤7,添加列18日标准价值269.421步骤8,添加列15,则价值253.78步骤9,添加列40,则值242.04步骤10,添加列27日标准价值234.184第11步,添加列12、准则值223.271步骤12,添加列17日标准价值216.464 13步,添加列14日标准价值212.635步骤14日添加列22日标准价值207.885步骤15,添加列7,则价值205.253步骤16,添加列33岁的准则值204.179最后一列包括:5 7 9 12 14 15 16 17 18 22日26日27日31日33 35 40 =列1到12 0 0 0 0 1 0 1 0 1 0 0 1列13到24 0 1 1 1 1 1 0 0 0 1 0 0列25到36 0 1 1 0 0 0 1 0 1 0 1 0列通过40 0 0 0 1历史= 37:[16 x40逻辑]暴击:[1乘16双]
我已经配置了sequentialfs显示每个迭代的特征选择过程。你可以看到每一个变量,因为它被添加到模型中,随着交叉验证均方误差的变化。
使用最优的特征集生成一个线性回归
β=回归(Y、X (:,));ds。顺序= 0(长度(ds), 1);ds.Sequential() =β
ds =β线性顺序0 -0.74167 -0.66373 0 0 0 0 0 0 0 0 0 1.6493 -1.7087 2.5441 1.3721 1.2025 -3.5482 0 0 -1.6411 -1.1617 0 0 0 4.1643 1.7454 - 2.9983 2.9544 0.28763 -1.9067 0 2 0 2 2 0 2 2.2226 - 3.5806 4.4912 - 4.0527 0.1005 4.7129 - 5.3879 3.9699 0.9606 5.9834 - 5.1789 1.9982 - 2 2 0 2 0 0 2.861 0 0 0.94454 -0.51398 1.8677 -1.6324 -2.1236 - -2.4748 0 0 0 0 0 0 0 -0.98227 3.6856 - 4.0398 -3.3103 - -4.1396 0 0 0 0 0 0.026193 1.4756 2.3509 - 1.9472 2.9373 0.63056 3.8792 - 2 0 2 2 0 2 2.9242 - 4.35 0.4794 0.8035 -0.70758 0.6066 -0.6632 0 2 0 2 0 2 4.4814 - 3.8164
正如您可以看到的,sequentialfs产生了一个更简洁的比普通最小二乘回归模型。我们也有一个模型,生成更准确的预测。此外,如果我们需要(假设)提取五个最重要的变量,我们可以简单的获取步骤的输出1:5。
运行一个仿真
作为最后一步,我们将再一次运行一个模拟基准的技术。在这里,再一次,我们可以看到,特征选择技术是做得很好识别真正的预测,同时屏蔽干扰。
matlabpool开放sumin = 0;parforj = 1:10 0 Z12 = randn (100, 40);Z1 = randn (100 1);X = Z12 + repmat (Z1, 1 40);B0 = 0 (10, 1);B1 = 1 (10, 1);β= 2 * vertcat (B0, B1, B0, B1);Y = X *β+ 15 * randn (100 1);有趣= @ (x0, y0 (x1, y1)规范(y1-x1 * (x0 \ y0)) ^ 2;%残差平方和,历史上[]= sequentialfs(有趣,X, Y,“简历”5);在+ sumin sumin =;结束栏(sumin) matlabpool关闭
matlabpool开始使用“local4”配置…连接到3实验室。发送停止信号的所有实验室……停止了。

最后一个评论:正如你所看到的,都不是sequentialfs也不是所有可能的子集选择是完美的。这些技术能够捕获所有的真正的变量,同时排除干扰选项。重要的是要认识到,这些数据集是故意设计成难以适应。(我们不想使用“简单”问题,任何基准性能旧技术可能会成功。)
下周的博客将专注于一种截然不同的方式来解决这些类型的问题。请继续关注看看正则化技术,如岭回归,套索和弹性。
这里有几个问题,你可能要考虑:#所有可能的子集方法O (2 ^ n)。复杂的时序特征选择的顺序是什么?#扩展问题以外,你还能想到任何可能的序列特征选择问题?有算法的情况下可能会错过重要的变量?