 克里夫角:克里夫·摩尔论数学与计算
克里夫角:克里夫·摩尔论数学与计算 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 Simulin金宝appk上的家伙
Simulin金宝appk上的家伙 深度学习
深度学习 开发区
开发区 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 标题背后
标题背后 本周最佳文件交换选择
本周最佳文件交换选择 物联网上的汉斯
物联网上的汉斯 赛马休息室
赛马休息室 初创企业、加速器和企业家
初创企业、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー子集选择与正则化
本周,来自技术营销部的理查德·威利(Richard Willey)将在博客上发表关于子集选择和规范化的客座博客。本周的博客帖子是由应用曲线拟合中出现的两个常见挑战激发的。
- 第一个挑战是,当独立变量显示出很强的相关性时,如何最好地创建准确的预测模型。在许多情况下,如果您减少预测器的数量,或者将系数值缩小到接近于零,那么您可以改进普通最小二乘回归的结果。
- 第二个挑战涉及当您所使用的预测器数量受到限制时,生成准确的预测模型。例如,假设您需要将模型嵌入到控制器中。您有20个可能的预测变量可供选择,但您的内存只够容纳8个独立变量。
这篇博客文章将展示两组不同的技术来解决这些相关的挑战。第一组技术基于特征选择和交叉验证的组合。第二组技术是使用正则化算法,如岭回归、套索和弹性网。所有这些算法都可以在统计学工具箱.
内容
创建一个数据集
首先,我将生成一个精心设计的数据集,它很难使用传统的线性回归进行匹配。数据集有三个特点,这给线性回归带来了挑战
- 数据集非常“广泛”。与观察的数量相比,有相对大量的(可能的)预测因素。
- 这些预测因子之间有很强的相关性
- 数据集中存在大量噪声
清楚的所有clc rng (1998);
创造八个X变量。每个变量的平均值将等于零。
mu=[0 0 0 0];
变量之间相互关联。协方差矩阵指定为
我= 1:8;矩阵= abs (bsxfun (@minus,我,我));协方差= repmat(5 8 8)。^矩阵;
使用这些参数生成一组多元正态随机数。
X = mvnrnd(mu,协方差,20);
创建一个描述Y=f(X)然后加上一个噪声向量。注意,8个预测因子中只有3个具有> 0的系数值。这意味着8个预测因子中的5个对实际模型没有影响。
贝塔=[3;1.5;0;0;2;0;0;0];ds=数据集(Beta);Y=X*Beta+3*randn(20,1);
对于那些感兴趣的人来说,这个例子是由Robert提出的Tibshirani 1996年关于套索的经典论文:
Tibshirani, r(1996)。回归收缩和通过套索选择。j .皇家。中央集权。Soc B,第58卷,第1期,267-288页)。
我们的模型Y=f(X)使用普通最小二乘回归。我们将从使用传统的线性回归模型开始Y=f(X)并将回归模型估计的系数与已知向量进行比较贝塔.
b=回归(Y,X);ds.线性=b;disp (ds)
Beta线性3 3.5819 1.5 0.44611 0 0.92272 0 -0.84134 2 4.7091 0 -2.5195 0 0.17123 0 -0.42067
正如预期的那样,回归模型的表现非常糟糕。
- 回归是估计所有八个预测因子的系数值。客观地说,我们“知道”这些系数中有5个应该是零。
- 此外,正在估计的系数与真实值相差甚远。
让我们看看是否可以使用一种叫做“所有可能子集回归”的技术来改进这些结果。首先,我将生成255个不同的回归模型,其中包含8个预测因子的每一个可能组合。接下来,我将使用交叉验证的均方误差测量所产生的回归的准确性。最后,我将选择产生最准确结果的回归模型,并将其与我们原来的回归模型进行比较。
为回归子集创建索引。
index=dec2bin(1:255);index=index==' 1 ';结果=双(指数);结果:9)= 0(长度(结果),1);
生成回归模型。
为I = 1:length(index) foo = index(I,:);rng (1981);regf = @(XTRAIN, YTRAIN, XTEST)(XTEST*回归(YTRAIN,XTRAIN));结果(我,9)= crossval (“mse”,X(:,foo),Y,“kfold”5.“predfun”, regf);结束
按MSE对输出进行排序。我会给你看前几个。
Index = sortrows(results, 9);指数(1:10,:)
ans = 1到5列1 1 0 0 1 1 1 0 1 1 1 0 1 0 1 1 1 0 0 1 1 0 0 0 1 1 1 0 1 1 1 0 0 1 1 1 0 0 0 1 1 0 1 0 1 1 0 0 1 1列6至9年1 0 0 10.239 10.533 1 0 0 1 0 0 0 0 0 10.615 10.976 1 0 0 0 0 0 11.062 11.257 11.938 11.641 1 0 0 0 0 0 0 0 0 0 0 0 12.068 12.249
比较结果
beta = return (Y, X(:,逻辑(index(1,1:8))));子集= 0 (8,1);ds。子集=子集;ds.Subset(逻辑(索引(1:8)))=β;disp (ds)
Beta线性子集3 3.5819 3.4274 1.5 0.44611 1.1328 0 0.92272 00 0.84134 0 2 4.7091 4.1048 0 -2.5195 -2.0063 0 0.17123 00 0 -0.42067 0
结果相当惊人。
- 我们的新模型只包括4个预测因子。变量3、4、7和8已从回归模型中剔除。此外,被排除的变量是那些我们“知道”应该被归零的变量。
- 同样重要的是,根据所得回归模型估算的系数更接近“真实”值。
所有可能的子集回归似乎产生了一个更好的模型R^2此回归模型的值不如原始线性回归;但是,如果我们试图从新数据集生成预测,我们预计此模型的性能会显著提高。
执行一个模拟
依赖单一观察的结果总是危险的。如果我们改变任意一个用于生成原始数据集的噪声向量,我们可能会得到完全不同的结果。下一个代码块将重复我们最初的实验100次,每次添加不同的噪声向量。我们的输出将是一个柱状图,显示每个不同变量被包含在结果模型中的频率。我使用并行计算来加快速度,尽管你可以在串行中执行(更慢)。
matlabpool打开sumin=0(1,8);parforj=1:100亩=0;贝塔=[3;1.5;0;0;2;0;0;0];i=1:8;矩阵=abs(bsxfun(@负,i',i));协方差=repmat(.5,8,8)。^矩阵;X=mvnrnd(μ,协方差,20);Y=X*Beta+3*randn(尺寸(X,1),1);指数=dec2bin(1:255);索引=索引==' 1 ';结果=双(指数);结果:9)= 0(长度(结果),1);为foo = index(K,:);regf = @(XTRAIN, YTRAIN, XTEST)(XTEST*回归(YTRAIN,XTRAIN));结果(k, 9) = crossval (“mse”,X(:,foo),Y,“kfold”5....“predfun”, regf);结束%按MSE对输出进行排序指数=sortrows(结果,9);sumin=sumin+指数(1,1:8);结束% parformatlabpool关闭
使用'local4'配置启动matlabpool…连接3个实验室。向所有实验室发出停止信号…停止了。
%绘制结果。酒吧(苏敏)
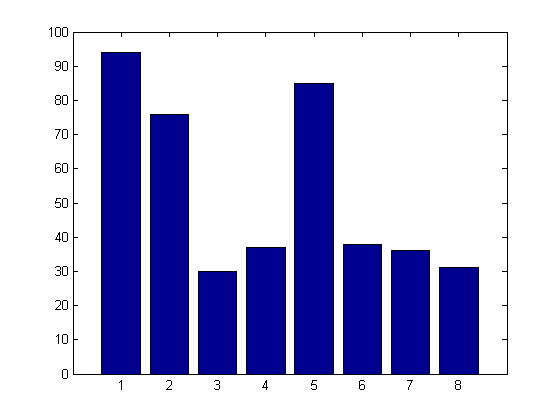
结果清楚地表明,“所有可能的子集选择”在识别驱动我们模型的关键变量方面做得非常好。变量1、2和5出现在大多数模型中。个体干扰因素也在模型中发挥作用,然而,它们的频率远没有真正的预测因素那么高。
介绍序列特征选择
所有可能的子集选择都受到一个巨大的限制。将这种技术应用于包含大量(潜在)预测器的数据集在计算上是不可行的。我们的第一个例子有8个可能的预测因子。测试所有可能的子集需要生成(2^8)-1 = 255个不同的模型。假设我们正在评估一个有20个可能预测因子的模型。所有可能的子集都需要测试1,048,575种不同的模型。有了40个预测器,我们将会看到10亿种不同的组合。
顺序特征选择是一种更现代的方法,它试图在搜索空间中定义一条智能路径。反过来,这应该允许我们识别一组好的系数,但确保这个问题仍然是计算上可行的。
序列特征选择工作如下:
- 首先,一次测试一个可能的预测值。确定生成最精确模型的单一预测值。此预测值将自动添加到模型中。
- 接下来,一次一个,将剩余的预测因子添加到包含单个最佳变量的模型中。确定最能提高模型精度的变量。
- 测试两个模型的统计显著性。如果新模型没有比原始模型更精确,则停止该过程。但是,如果新模型在统计上更显著,则搜索第三个最佳变量。
- 重复这个过程,直到您不能确定一个新的变量,它在统计上对模型有显著的影响。
下面的代码将向您展示如何使用顺序特性%选择以解决明显更大的问题。
生成数据集
清楚的所有clc rng(1981);Z12=randn(100,40);Z1=randn(100,1);X=Z12+repmat(Z1,1,40);B0=0(10,1);B1=1(10,1);Beta=2*vertcat(B0,B1,B0,B1);ds=dataset(Beta);Y=X*Beta+15*randn(100,1);
使用线性回归拟合模型。
b=回归(Y,X);ds.线性=b;
使用序列特征选择来拟合模型。
选择= statset (“显示”,“通路”); fun=@(x0,y0,x1,y1)范数(y1-x1*(x0\y0))^2;%残差平方和,历史上[]= sequentialfs(有趣,X, Y,“简历”5.“选项”,选项)
开始正向顺序特征选择:包含初始列:无不能包含的列:无步骤1、添加列26、标准值868.909步骤2、添加列31、标准值566.166步骤3、添加列9、标准值425.096步骤4、添加列35、标准值369.597步骤5、添加列16、标准值314.445步骤6,添加第5列,标准值283.324步骤7,添加第18列,标准值269.421步骤8,添加第15列,标准值253.78步骤9,添加第40列,标准值242.04步骤10,添加第27列,标准值234.184步骤11,添加第12列,标准值223.271步骤12,添加第17列,标准值216.464步骤13,增加第14列,标准值212.635步骤14,增加第22列,标准值207.885步骤15,增加第7列,标准值205.253步骤16,增加第33列,标准值204.179最终列包括:5 7 9 12 14 15 16 17 18 22 26 27 31 33 35 40 in=第1列至第12 0 0 0 0 1 0 1 0 1 0 0 1 0 1 1列13至24 0 1 1 1 1列1 1 1 0 0 0 1 0 0 0列25至36 0 1 1 0 0 0 1 0 1 0 1 0列37至40 0 0 1历史记录=In:[16x40逻辑]临界值:[1x16双精度]
我已经配置了顺序来显示特征选择过程的每次迭代。你可以看到每个变量被添加到模型中,以及交叉验证均方误差的变化。
使用最佳特征集生成线性回归
β=回归(Y,X(:,in));ds.Sequential=零(长度(ds),1);ds.Sequential(in)=β
ds=贝塔线性序贯0-0.741670-0.66373 0 0 1.20250-1.7087 0 0 1.6493 2.5441 0 1.3721 0-1.6411-1.16170-3.5482 0 0 0 4.1643 2.9544 0-1.9067 0 2 0.28763 0 2 1.7454 2 2.9983 2 0.1005 0 2 2 2 2 2 2 2 2.2226 3.5806 2 4.4912 4.0527 2 2 2 4.7129 5.3879 2 0.9606 1.992 5.34 5.989 2 0 2 2 0 2 2 0 2 2 2 0 2 2 0 2 2 2 2 0.962 0 2 0 2 0 2 0.432 0-1.862 0.472 0-1-0.24 0-1.868677 0 0 -0.51398 0 0 3.6856 4.0398 0 -3.3103 -4.1396 0 -0.98227 0 0 1.4756 0 0 0.026193 0 2 2.9373 3.8792 2 0.63056 0 2 2.3509 1.9472 2 0.8035 0 2 2.9242 4.35 2 0.4794 0 2 -0.6632 0 2 0.6066 0 2 -0.70758 0 2 4.4814 3.8164
如你所见,顺序产生了一个比普通最小二乘回归更简洁的模型。我们也有一个模型,可以产生更准确的预测。此外,如果我们需要(假设)提取5个最重要的变量,我们可以简单地从步骤1:5中获取输出。
进行模拟
作为最后一步,我们将再次运行一个模拟来对该技术进行基准测试。在这里,再一次,我们可以看到特征选择技术在甄别干扰因素的同时,在识别真正的预测因素方面做得非常好。
matlabpool打开sumin = 0;parforj=1:100 Z12 = randn(100,40);Z1 = randn (100 1);X = Z12 + repmat(Z1, 1,40);B0 = 0 (10, 1);B1 = 1 (10, 1);= 2 * vertcat(B0,B1,B0,B1);Y = X * Beta + 15*randn(100,1); / /Fun = @(x0,y0,x1,y1)模(y1-x1*(x0\y0))^2;%残差平方和,历史上[]= sequentialfs(有趣,X, Y,“简历”,5); sumin=in+sumin;结束栏(sumin) matlabpool关闭
使用'local4'配置启动matlabpool…连接3个实验室。向所有实验室发出停止信号…停止了。

最后一句话:正如你所见,两者都不是顺序也不是所有可能的子集选择都是完美的。这两种方法都不能在排除干扰因素的情况下捕捉到所有的真实变量。重要的是要认识到这些数据集是故意设计成难以匹配的。[我们不想使用任何旧技术都可能成功的“简单”问题来进行性能测试。]
下周的博客文章将集中讨论一种完全不同的方法来解决这些相同类型的问题。请继续关注正则化技术,如脊回归,套索和弹性网。
以下是您可能需要考虑的几个问题:#所有可能的子集方法都是O(2^n)。顺序特征选择的复杂度顺序是什么?#除了缩放问题,您能想到顺序特征选择可能存在的问题吗?是否存在算法可能遗漏重要变量的情况?




评论
如需留言,请点击在这里登录到您的MathWorks帐户或创建新帐户。