 克里夫的角落:克里夫硅藻土在数学和计算
克里夫的角落:克里夫硅藻土在数学和计算 MATLAB的博客
MATLAB的博客 史蒂夫与MATLAB图像处理
史蒂夫与MATLAB图像处理 人在仿真软件金宝app
人在仿真软件金宝app 人工智能
人工智能 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 文件交换的选择
文件交换的选择 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー 创业、加速器,和企业家
创业、加速器,和企业家 自治系统
自治系统 定量金融学
定量金融学
缩放和MapReduce市场购物篮分析
在之前一篇竹内古原,今天的嘉宾给我们介绍市场购物篮分析。本周,他将讨论如何扩展这种技术使用MapReduce处理大数据。

内容
101年MATLAB MapReduce
R2014b MATLAB核心功能是一个重大更新,一些新的令人兴奋的特性之一是MapReduce。我感兴趣的主要是市场购物篮分析分析点击流数据,我知道网络使用数据从web服务器日志中提取是非常大的。
MapReduce是处理大规模数据集开发的分布式并行计算,并使大数据分析的关键技术之一。
MapReduce由映射器和还原剂。映射器从文件读取数据存储一个块和解析数据生成键-值对。还原剂将接收键和键值对的处理值与这些值有关。所以你需要做的是:
- 使用数据存储指定数据源
- 定义映射器和减速机的功能
- 使用mapreduce与数据存储mapper和减速机来处理数据
- 存储处理过的数据进行进一步分析

尽管映射器和还原剂执行相当简单的操作,可以把它们串在一起处理更复杂的操作。在先验的算法,最耗时的步骤生成事务和1-itemset数据。让我们使用MapReduce解决这些瓶颈。
我们开始通过设置数据存储。在这个例子中,我们将使用一个相当小的CSV文件在本地驱动器,但是数据存储可以
- 读数据太大了,适合在一台计算机内存,或
- 读文件在多个位置上一个集群,包括那些在Hadoop分布式文件系统(HDFS),以适当的附加产品。下载188bet金宝搏
开始时是很重要的一个小子集的数据原型和测试算法在你使用它之前真的大数据。MATLAB使得它很容易原型算法在本地机器上,然后扩展到集群或云后。
设置源数据存储。
source_ds =数据存储(“sampleData.csv”,“ReadVariableNames”假的,…“NumHeaderLines”,1“VariableNames”,{“VisitorCookieID”,“页面”,“访问”});source_ds。SelectedVariableNames = {“VisitorCookieID”,“页面”};
一个访问者饼干id列表数据和相关的页面id。
让我们来回顾一下数据。
disp(预览(source_ds)重置(source_ds)
VisitorCookieID页面__________________________________ ___________________________________________________________________________‘3821337 fdad7a6132253b10b602c4616 ' / matlabcentral /答案/ ' ' 3821337 fdad7a6132253b10b602c4616 ' ' / matlabcentral /答案/ 152931 - - - -如何翻译- -以下代码从…“3821337 fdad7a6132253b10b602c4616“数量/ matlabcentral /答案/ 153109 - - -比-最大积极……“3821337 fdad7a6132253b10b602c4616 ' ' /帮助/ matlab / ref /最大浮点数。html ' ' 3821337 fdad7a6132253b10b602c4616 ' ' / matlabcentral /答案/ 153201 - -如何评价-大-阶乘“3821337 fdad7a6132253b10b602c4616 ' ' /帮助/ matlab / matlab_prog /浮点数。html ' ' 3821337 fdad7a6132253b10b602c4616 ' ' / matlabcentral /贡献者/ 5560534 - tigo /问题/回答“3821337 fdad7a6132253b10b602c4616 ' ' / matlabcentral /新闻阅读器/ view_thread / 297433”
步骤1:集团项目事务
如果你认为游客的购物,你可以认为访问页面的购物车中的项目(事务)。访问者可以访问同一页面多次,但这样的重复访问不计入项目集计数。
其中一个重要的设计考虑MapReduce算法密钥生成的数量降到最低。由于这个原因,一个很好的起点是集团通过交易使用的物品VisitorCookieID的关键,因为我们有一个有限集的游客但是他们可以访问更多的页面。
类型transactionMapper
函数transactionMapper(数据、信息、intermKVStore) tid = data.VisitorCookieID;项= data.Page;%获得独特的tid u_tid =独特(tid);%遍历数据块将多个项目映射到一个独特的tid项=细胞(大小(u_tid));i = 1:长度(tid)行= ismember (u_tid, tid{我});项{行}{结束+ 1}{我}=项目;结束%使用addmulti加快流程addmulti (intermKVStore、u_tid项)
映射器会通过这个键-值对减速器。
类型transactionReducer
函数transactionReducer(价值,关键outKVStore)项= {};%连接项目从不同的映射器相同的密钥而hasnext(值)项目=(项目,getnext(值));结束%消除重复u_items =独特(项目);%将数据保存到一个键值存储添加(outKVStore、关键,u_items);结束
减速机接收键键-值对,并合并多个细胞数组具有相同关键到单个单元阵列和删除任何副本。我们可以将结果存储在一个新的数据存储。
现在,让我们来运行这个工作。
集团项目事务。
transaction_ds = mapreduce (source_ds @transactionMapper @transactionReducer);交易= readall (transaction_ds);disp(事务(1:5,:))
并行执行mapreduce在本地集群:* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * mapreduce进展* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *地图地图100%减少50% 100% 0%减少0%减少100%键值__________________________________ ___________ 00927996 b5566e6347e55463dc7c6273的{1乘16细胞}“01 c5f379d2e475d727eec2c711fb83f8”{1 x11细胞}“0717615157 c000c4955c21b958b7866d”{1 x1细胞}' 0 f29597bff2a611013a4333f027b4f1a ' {1} x12细胞“13027 f74a9c7402bf7b8f699b557815f”{1} x12细胞
步骤2:生成1-itemsets
我们现在知道,所有项目在一个事务中是独一无二的。所有我们需要做的是计算一个项目出现在交易的次数多少事务包含项目。页面被存储为一个值在前面的步骤中,我们只需要检索只是那些和计算它们的内容。
类型oneItemsetMapper
函数oneItemsetMapper(数据、信息、intermKVStore) %钥匙在细胞数组键= data.Value {1};% 1创建一个细胞数组的值= num2cell((大小(钥匙)));%将数据保存到键值存储addmulti (intermKVStore、键值)
映射器通过页面的每个实例1。
类型oneItemsetReducer
函数oneItemsetReducer(价值,关键outKVStore)数= 0;虽然hasnext(值)计算=数+ getnext(价值);最后添加(outKVStore,钥匙,数);结束
减速机然后收集给定页面的数量和金额。现在,让我们来运行这个任务和完成结果读入内存。
%得到1-itemsetsoneItemset_ds = mapreduce (transaction_ds @oneItemsetMapper @oneItemsetReducer);%结果读入内存oneItemsets = readall (oneItemset_ds);disp (oneItemsets (655:659:))
并行执行mapreduce在本地集群:* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * mapreduce进展* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *地图地图50%减少0% 100% 0%减少0%减少50%地图100%减少100%键值__________________________________________________________________ _____ /罗兰”[2]/罗兰/ 2006/07/05 / when-is-a-numeric-result-not-a-number /”[1]的/罗兰/ 2009/10/02 / using-parfor-loops-getting-up-and-running /[1] /罗兰/ 2011/11/14 / generating-c-code-from-your-matlab-algorithms /”[1]的/罗兰/ 2012/02/06 / using-gpus-in-matlab / [1]
生成频繁项集
现在我们已经准备好为事务和oneItemsets数据findFreqItemsets,也接受1-itemsets表作为一个可选的输入。如果你去可用的代码前面的文章。
让我们产生频繁项集0.02基于最小支持度阈值的方法,这意味着我们看到相同的模式中至少2%的游客。金宝app
度= 0.02;流(“处理数据集和最小支持度阈值= %….2f \ n \ n '金宝app度)[F S项目]= findFreqItemsets(事务、度oneItemsets);流(“发现频繁项集:% d \ n”总和(arrayfun (@ (x)大小(x.freqSets, 1), F)))流(“马克斯水平:k = % d \ n '、长度(F))流(支持数据数量:% d 金宝app\ n \ n '长度(S))
= 0.02处理数据集和最小支持度阈值的方法……金宝app频繁项集的发现:151 Max水平:k = 4支持数据数量:4107金宝app
生成规则
这一步是没有区别的例子在前面的帖子。我们使用最低置信阈值0.6。
minConf = 0.6;规则= generateRules (F,年代,minConf);流(“最低信心:% .2f \ n”minConf)流(“规则发现:% d \ n \ n '长度(规则))
最小的信心:0.60规则发现:99
可视化规则的支持、信心和升力金宝app
现在我们可以想象我们生成的规则。这个示例数据集非常微小,和规则的数量是有限的。
参看= arrayfun (@ x (x)。配置、规则);%得到配置作为一个向量取消= arrayfun (@ x (x)。电梯、规则);%得到提升作为一个向量一口= arrayfun (@ x (x)。吃晚饭、规则);%得到支持向金宝app量colormap很酷的散射(一口,相依,解除* 5,升力,“填充”)包含(“金宝app支持”);ylabel (“信心”)t = colorbar (“对等”甘氨胆酸,);集(get (t)“ylabel”),“字符串”,“取消”);标题(样本数据的)
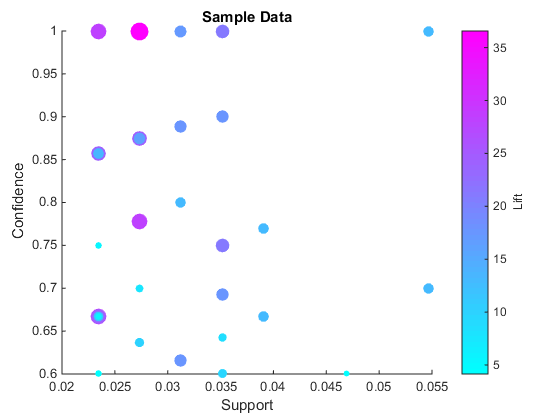
微软网络数据
不幸的是我们不能分享这个示例数据让你试一试,但是很容易适应这个代码使用公开数据集等匿名微软Web数据的数据集从UCI机器学习库。这个数据从原始preprossed点击流日志,我们需要处理它回到我们用于样本数据的原始格式。你可以看到下面的代码用于处理这个数据集。
市场购物篮分析应用到这个数据集时,您应该得到这样的东西。

规则# 1 {Windows 95} = > {Windows家庭OSs}相依:0.91,提升:6.46
规则# 2 {Windows95支持}金宝app= > {isapi}相依:0.84,提升:5.16
规则# 3 {SiteBuilder网络会员}= >{开发者网站建设}相依:0.80,提升:8.17
规则# 5{知识库,isapi} = >{支持桌面}相依:0.71,提升金宝app:5.21
规则# 18 {Windows的OSs, isapi} = > {Windows95支持}相依:0.64,提金宝app升:11.66
示例代码包括MapReduce步骤减少数据集。我减少了数据集,因为我的MapReduce代码不是最佳的数据集和运行非常缓慢。我的代码假设比游客有更多页,和我们有了更多的游客比页面在这个微软数据集。
如果你想使用MapReduce微软数据集,我强烈建议你写自己的MapReduce代码更优化的数据集。
总结和下一步
现在我们原型算法和测试它。我可以看看我的见解我寻找与此流程。曾经我很高兴,我还需要找出集群上或云存储更大的数据。它更多的业务挑战不是一个技术问题,我仍然在中间。
MATLAB中的MapReduce编程非常简单,容易。源数据是当地在这个例子中,但您还可以使用一个更大的数据集,在多个地点,比如HDFS文件。你可以原型MapReduce算法在本地,然后改变配置规模更大的数据集。
在这个例子中,MapReduce是仅用于初始数据处理,剩下的还在内存中完成。只要处理结果与记忆,我们可以使用这种方法。
然而,如果处理过的数据变大,那么我们需要更多的其他步骤中使用MapReduce先验的完成。
关键是要适应算法并行处理。在目前的化身,你有一个单线程的候选人修剪阶段。
相反,我们细分数据集分成几块,完成整个过程通过规则生成。我们需要调整最低支持占事务数的减少子集,如果我们这样做。金宝app然后我们可以把最终的输出。这可能不会提供相同的结果作为单线程的过程,但它应该是相当接近。
你的想法呢?
你看到的方式你可能利用MapReduce处理大数据分析项目?让我们知道在这里。
附录-流程微软Web数据
这是我用来处理微软数据集的代码。
类型processMicrosoftWebData.m
% % % UCI数据集加载数据集是在原始的日志格式,但在一个特殊的% non-tabular ASCII格式。我们需要处理数据格式%可以使用。这不是一个典型的过程当你工作与实际%原始点击流数据。%清楚一切clearvars;关闭所有;clc %源数据文件名的URL =“anonymous-msweb.data”;%如果te文件不存在,请下载UCI的网站如果存在(文件名,“文件”)= = 0 url = ' http://archive.ics.uci.edu/ml/machine-learning-databases/anonymous/anonymous-msweb.data ';filepath = websave (anonymous-msweb.data, url);结束%蓄电池援助= [];%属性id vroot = {}; % vroot - page name url = {}; % url of the page vid = []; % visitor id visits = []; % aid of vroots visited by a visitor VisitorCookieID = {}; % same as vid but as string % open the file fid = fopen(filename); % read the first line tline = fgetl(fid); % if the line contains a string while ischar(tline) % if the line contains attribute if strcmp(tline(1),'A') c = textscan(tline,'%*s%d%*d%q%q','Delimiter',','); aid = [aid;c{1}]; vroot = [vroot;c{2}]; url = [url;c{3}]; % if the line contains case elseif strcmp(tline(1),'C') user = textscan(tline,'%*s%*q%d','Delimiter',','); % if the line contains vote elseif strcmp(tline(1),'V') vid = [vid;user{1}]; vote = textscan(tline,'%*s%d%*d','Delimiter',','); visits = [visits; vote{1}]; VisitorCookieID = [VisitorCookieID;['id',num2str(user{1})]]; end tline = fgetl(fid); end % close the file fclose(fid); % sort attributes by aid [~,idx] = sort(aid); aid = aid(idx); vroot = vroot(idx); url = url(idx); % populate |Page| with vroot based on aid Page = cell(size(visits)); for i = 1:length(aid) Page(visits == aid(i)) = vroot(i); end % create table and write it to disk if it doesn't exist transactions = table(VisitorCookieID,Page); if exist('msweb.transactions.csv','file') == 0 % just keep the first 318 rows to use as sample data transactions(319:end,:) = []; % comment out to keep the whole thing writetable(transactions,'msweb.transactions.csv') end %% Association Rule Mining without MapReduce % Since we already have all necessary pieces of data in the workspace, we % might as well do the analysis now. % get unique uid uniq_uid = unique(vid); % create a cell array of visits that contains vroots visited transactions = cell(size(uniq_uid)); for i = 1:length(uniq_uid) transactions(i) = {visits(vid == uniq_uid(i))'}; end % find frequent itemsets of vroots from the visits minSup = 0.02; fprintf('Processing dataset with minimum support threshold = %.2f\n...\n', minSup) [F,S,items] = findFreqItemsets(transactions,minSup); fprintf('Frequent Itemsets Found: %d\n', sum(arrayfun(@(x) size(x.freqSets,1), F))) fprintf('Max Level : k = %d\n', length(F)) fprintf('Number of Support Data : %d\n\n', length(S)) % generate rules minConf = 0.6; rules = generateRules(F,S,minConf); fprintf('Minimum Confidence : %.2f\n', minConf) fprintf('Rules Found : %d\n\n', length(rules)) % plot the rules conf = arrayfun(@(x) x.Conf, rules); % get conf as a vector lift = arrayfun(@(x) x.Lift, rules); % get lift as a vector sup = arrayfun(@(x) x.Sup, rules); % get support as a vector colormap cool scatter(sup,conf,lift*5, lift, 'filled') xlabel('Support'); ylabel('Confidence') t = colorbar('peer',gca); set(get(t,'ylabel'),'String', 'Lift'); title('Microsoft Web Data') % display the selected rules selected = [1,2,3,5,18]; for i = 1:length(selected) fprintf('Rule #%d\n', selected(i)) lenAnte = length(rules(selected(i)).Ante); if lenAnte == 1 fprintf('{%s} => {%s}\nConf: %.2f, Lift: %.2f\n\n',... vroot{rules(selected(i)).Ante(1)},vroot{rules(selected(i)).Conseq},... rules(selected(i)).Conf,rules(selected(i)).Lift) elseif lenAnte == 2 fprintf('{%s, %s} => {%s}\nConf: %.2f, Lift: %.2f\n\n',... vroot{rules(selected(i)).Ante(1)},vroot{rules(selected(i)).Ante(2)},... vroot{rules(selected(i)).Conseq},rules(selected(i)).Conf,rules(selected(i)).Lift) end end %% MapReduce % My MapReduce code is not well suited for this dataset and runs extremely % slow if you use the whole dataset. I will just use just a subset for % demonstration purpose. If you want to try this on the full dataset, you % should write your own MapReduce code optimized for it. % clear everything clearvars; close all; clc % set up source datastore source_ds = datastore('msweb.transactions.csv'); disp(preview(source_ds)) % step 1: Group items by transaction transaction_ds = mapreduce(source_ds, @transactionMapper, @transactionReducer); transactions = readall(transaction_ds); % step 2: Generate 1-itemsets oneItemset_ds = mapreduce(transaction_ds, @oneItemsetMapper, @oneItemsetReducer); oneItemsets = readall(oneItemset_ds);







评论
要发表评论,请点击此处登录到您的MathWorks帐户或创建一个新帐户。