 克利夫角:克利夫莫勒的数学和计算
克利夫角:克利夫莫勒的数学和计算 罗兰谈MATLAB的艺术
罗兰谈MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 Simulin金宝appk上的Guy
Simulin金宝appk上的Guy 深度学习
深度学习 开发区域
开发区域 Stuart的MATLAB视频
Stuart的MATLAB视频 头条新闻背后
头条新闻背后 本周文件交换选择
本周文件交换选择 汉斯谈物联网
汉斯谈物联网 学生休息室
学生休息室 创业公司、加速器和企业家
创业公司、加速器和企业家 MATLAB社区
MATLAB社区 Matlabユザコミュニティ
Matlabユザコミュニティ用MapReduce进行市场篮子分析
在以前的文章,今天的客座博主竹内敏给我们介绍了市场篮子分析。本周,他将讨论如何使用这种技术MapReduce处理更大的数据。

内容
MapReduce在MATLAB 101
R2014b是对MATLAB核心功能的重大更新,对我来说几个令人兴奋的新特性之一是MapReduce。我主要对分析点击流数据的Market Basket Analysis感兴趣,我知道从web服务器日志中提取的web使用数据会非常大。
MapReduce是为了在分布式并行计算中处理海量数据集而开发的,它是实现大数据分析的关键技术之一。
MapReduce由映射器和简化器组成。映射器每次从文件存储块读取数据,并解析数据以生成键-值对。然后还原器将按键和与这些值相关的过程值接收这些键-值对。因此,你需要做的是:
- 使用数据存储指定数据源
- 定义mapper和reducer函数
- 使用mapreduce与数据存储,映射器和减速器对数据进行处理
- 存储处理后的数据以供进一步分析

尽管映射器和简化器执行相当简单的操作,但您可以将它们链接在一起以处理更复杂的操作。在Apriori算法中,最耗时的步骤是生成事务和1项集数据。因此,让我们使用MapReduce来解决这些瓶颈。
我们从设置开始数据存储.在本例中,我们将在本地驱动器上使用一个相当小的CSV文件,但是数据存储可以
- 读取过大的数据,无法装入单个计算机的内存,或者
- 在集群的多个位置读取文件,包括在Hadoop分布式文件系统(HDFS)上的文件,使用适当的附加产品。下载188bet金宝搏
在将算法应用于真正的大数据之前,从数据的一小部分开始构建原型并测试它是很重要的。MATLAB使您可以很容易地在本地机器上创建算法原型,然后将其扩展到集群或云。
设置源数据存储。
数据源=数据存储“sampleData.csv”,“ReadVariableNames”假的,...“NumHeaderLines”, 1“VariableNames”, {“VisitorCookieID”,“页面”,“访问”});source_ds。SelectedVariableNames = {“VisitorCookieID”,“页面”};
数据是访问者Cookie id和与这些id相关联的页面的列表。
让我们回顾一下数据。
disp(预览(source_ds)重置(source_ds)
VisitorCookieID页面 __________________________________ ___________________________________________________________________________ ' 3821337 fdad7a6132253b10b602c4616 ' ' / matlabcentral /答案/“3821337 fdad7a6132253b10b602c4616 ' ' / matlabcentral /答案/ 152931 - - - -如何翻译- -以下代码从…' '3821337fdad7a6132253b10b602c4616' '/matlabcentral/answers/153109-number-greater-than-the- biggest -positive…' '3821337fdad7a6132253b10b602c4616' '/help/matlab/ref/realmax.html' '3821337fdad7a6132253b10b602c4616' '/matlabcentral/answers/ 15321 -how-to- evaluatedlarge - fac' '3821337fdad7a6132253b10b602c4616' '/help/matlab/matlab_prog/浮点数。html' '3821337fdad7a6132253b10b602c4616' '/matlabcentral/answers/贡献者/5560534-tigo/questions' '3821337fdad7a6132253b10b602c4616' '/matlabcentral/newsreader/view_thread/297433'
第一步:按事务分组
如果将访问者视为购物者,则可以将访问的页面视为购物车中的项目(事务)。访问者可以多次访问同一页面,但这种重复访问不计入项目集。
在设计MapReduce算法时,一个重要的考虑因素是尽量减少生成的键的数量。出于这个原因,一个很好的起点是通过使用按事务分组项目VisitorCookieID作为键,因为我们有有限的访问者集合,但他们可以访问更多的页面。
类型transactionMapper
function transactionMapper(data, info, intermKVStore) tid = data. visitorcookieid;item = data.Page;u_tid = unique(tid);%遍历数据块,将多个条目映射到唯一的tid items = cell(size(u_tid));如果I = 1:length(tid) row = ismember(u_tid,tid{I});item{row}{end+1} = item{i};addmulti(intermKVStore, u_tid, items) end .使用addmulti加快进程
然后,映射器将这个键-值对传递给减速器。
类型transactionReducer
function transactionReducer(key, value, outKVStore) items = {};* hasnext(value) items = [items, getnext(value)];消除重复u_items = unique(items);%将数据保存到键值存储add(outKVStore, key, u_items);结束
减速器按键接收键-值对,并将具有相同键的多个单元格数组合并为单个单元格数组,并删除任何重复的单元格数组。然后,我们可以将结果存储在new数据存储.
现在让我们运行这个工作。
按事务分组项目。
transaction_ds = mapreduce(source_ds, @transactionMapper, @transactionReducer);事务= readall(transaction_ds);disp(事务(1:5,:))
并行执行mapreduce在本地集群 : ******************************** * MAPREDUCE的进展 * ******************************** 地图地图100%减少50% 100% 0%减少0%键值减少100% __________________________________ ___________ ' 00927996 b5566e6347e55463dc7c6273“{1乘16细胞}”01 c5f379d2e475d727eec2c711fb83f8“{1 x11细胞}”0717615157 c000c4955c21b958b7866d ' {1 x1细胞}’0 f29597bff2a611013a4333f027b4f1a“{1}x12细胞”13027 f74a9c7402bf7b8f699b557815f“{1}x12细胞
步骤2:生成1项集
现在我们知道事务中的所有项目都是唯一的。我们所需要做的就是计算一个项目在事务中出现的次数,以查看有多少事务包含该项目。在前面的步骤中,页面被存储为一个值,因此我们只需要检索这些页面并计算其内容。
类型oneItemsetMapper
函数oneItemsetMapper(data, info, intermKVStore) % key在单元格数组中keys = data. value {1};%创建一个单元格数组1的值= num2cell(ones(size(keys)));将数据保存到键值存储addmulti(intermKVStore, keys, values)结束
映射器将页面的每个实例传递为1。
类型oneItemsetReducer
函数oneItemsetReducer(key, value, outKVStore) count = 0;当hasnext(value) count = count + getnext(value);end add(outKVStore, key, count);结束
然后,减速器收集给定页面的计数并将其相加。现在让我们运行这个作业并将完成的结果读入内存。
获取1个项目集oneItemset_ds = mapreduce(transaction_ds, @oneItemsetMapper, @oneItemsetReducer);将结果读入内存oneItemsets = readall(oneItemset_ds);disp (oneItemsets (655:659:))
在本地集群上并行执行mapreduce:******************************** * MAPREDUCE的进展 * ******************************** 地图0%减少0%地图地图100%减少50% 100% 50%减少0%键值减少100% __________________________________________________________________ _____ '/ 罗兰/”[2]/罗兰/ 2006/07/05 / when-is-a-numeric-result-not-a-number /”[1]/罗兰2009/10/02 / using-parfor-loops-getting-up-and-running /”[1]/罗兰/ 2011/11/14 / generating-c-code-from-your-matlab-algorithms /”[1]“/罗兰/ 2012/02/06 / using-gpus-in-matlab /”[1]
生成频繁项目集
现在,我们准备将事务和oneItemsets数据提供给findFreqItemsets,它还接受一个包含1个项目集的表作为可选输入。代码是可用的,如果你去之前的帖子.
让我们基于最小支持阈值0.02生成频繁项集,这意味着我们在至少2%的访问者中看到相同的模式。金宝app
minSup = 0.02;流('使用最小支持阈值处理数据集= %.2f\n…\n'金宝app,minSup) [F,S,items] = findFreqItemsets(事务,minSup,oneItemsets);流('发现的频繁项目集:%d\n', sum(arrayfun(@(x) size(x. freqsets,1), F))) fprintf('最高水平:k = %d\n',长度(F))'支持数据数量:%d\金宝appn\n'长度(S))
处理最小支持阈值= 0.02的数据集…金宝app发现的频繁项集:151最大级别:k = 4支持数据数量:4107金宝app
生成规则
这一步与前面文章中的例子没有什么不同。让我们使用最小置信阈值0.6。
minConf = 0.6;rules = generateRules(F,S,minConf);流('最小置信度:%.2f\n', minConf) fprintf('Rules Found: %d\n\n'长度(规则))
最小置信:0.60规则发现:99
通过支持、信心和提升来想象规则金宝app
现在我们可以可视化生成的规则了。这个样本数据集非常小,规则的数量也有限。
conf = arrayfun(@(x) x. conf, rules);% get conf作为一个向量lift = arrayfun(@(x) x. lift,规则);%得到升力作为一个矢量sup = arrayfun(@(x) x.p up,规则);%得到支持作金宝app为一个向量colormap很酷的散射(一口,相依,解除* 5,升力,“填充”)包含(“金宝app支持”);ylabel (“信心”t = colorbar(“对等”甘氨胆酸,);集(get (t)“ylabel”),“字符串”,“取消”);标题(样本数据的)
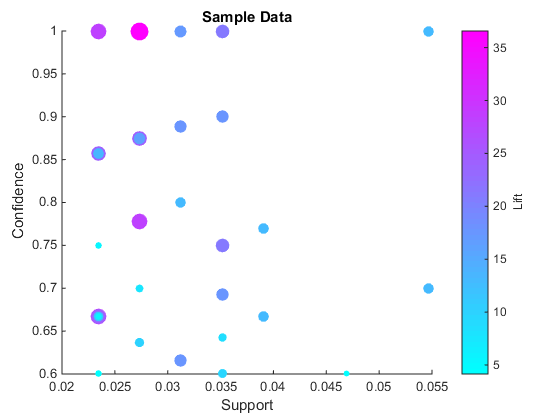
微软网络数据
不幸的是,我们不能分享此示例数据供您尝试,但使用公开可用的数据集(如)很容易调整此代码匿名微软Web数据数据集来自UCI机器学习知识库。这些数据是从原始点击流日志中预先处理的,我们需要将其处理回示例数据中使用的原始格式。您可以在下面看到用于处理此数据集的代码。
当您将市场篮子分析应用于此数据集时,您应该会得到类似这样的结果。

规则1 {Windows 95} => {Windows Family of os} Conf: 0.91, Lift: 6.46
规则2 {Windows95 Supp金宝apport} => {isapi} Conf: 0.84, Lift: 5.16
规则#3 {SiteBuilder网络成员}=>{开发人员的互联网网站建设}Conf: 0.80, Lift: 8.17
规则#5{知识库,isapi} =>{支持桌面}Conf: 0.71, 金宝appLift: 5.21
规则#18 {Windows系列操作系统,isapi} => {Windows95支持}Conf: 0.64金宝app, Lift: 11.66
样例代码还包括精简数据集上的MapReduce步骤。我减少了数据集,因为我的MapReduce代码对这个数据集不是最优的,运行非常慢。我的代码假设页面比访问者多,并且在这个Microsoft数据集中,访问者比页面多。
如果你想在完整的微软数据集上使用MapReduce,我强烈建议你编写自己的MapReduce代码,为这个数据集进行更优化。
总结和下一步
现在我们制作了算法原型并进行了测试。我可以看看我是否能通过这个过程获得我所寻找的洞察力。一旦我对它感到满意,我仍然需要找出在集群或云上存储较大数据的位置。这更像是一个商业挑战,而不是技术挑战,我还在这个过程中。
在MATLAB中编程MapReduce非常简单直接。在本例中,源数据是本地的,但您也可以将其用于跨多个位置的更大数据集,例如HDFS文件。您可以在本地创建MapReduce算法原型,然后更改配置以扩展到更大的数据集。
在这个例子中,MapReduce只用于初始数据处理,其余的仍然在内存中完成。只要处理后的结果能装进内存,我们就可以使用这种方法。
但是,如果处理的数据变大,那么我们就需要在Apriori算法的其他步骤中更多地使用MapReduce。
关键是使算法适应并行处理。在当前的版本中,在候选修剪阶段只有一个线程。
相反,我们将数据集细分为几个块,并通过在每个块中生成规则来完成整个过程。如果我们这样做,我们需要调整最小支持,以考虑子集中交易计数的金宝app减少。然后我们可以结合最终的输出。这可能不能提供与单线程进程相同的结果,但应该相当接近。
你的想法呢?
你认为如何利用MapReduce来处理更大的数据分析项目?让我们知道在这里.
附录-处理微软网络数据
下面是我用来处理微软数据集的代码。
类型processMicrosoftWebData.m
UCI数据集不是原始日志格式,而是一种特殊的%非表格ASCII格式。我们需要将数据处理成%可以使用的格式。当您使用实际%原始点击流数据时,这不是一个典型的过程。% clear一切clearvars;关闭所有;源数据的URL filename = 'anonymous-mswe .data';如果te文件不存在,下载UCI网站如果存在(filename,'file') == 0 url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/anonymous/anonymous-msweb.data';Filepath = websave('anonymous-mswe .data',url);End %累加器辅助= [];%属性id vroot = {}; % vroot - page name url = {}; % url of the page vid = []; % visitor id visits = []; % aid of vroots visited by a visitor VisitorCookieID = {}; % same as vid but as string % open the file fid = fopen(filename); % read the first line tline = fgetl(fid); % if the line contains a string while ischar(tline) % if the line contains attribute if strcmp(tline(1),'A') c = textscan(tline,'%*s%d%*d%q%q','Delimiter',','); aid = [aid;c{1}]; vroot = [vroot;c{2}]; url = [url;c{3}]; % if the line contains case elseif strcmp(tline(1),'C') user = textscan(tline,'%*s%*q%d','Delimiter',','); % if the line contains vote elseif strcmp(tline(1),'V') vid = [vid;user{1}]; vote = textscan(tline,'%*s%d%*d','Delimiter',','); visits = [visits; vote{1}]; VisitorCookieID = [VisitorCookieID;['id',num2str(user{1})]]; end tline = fgetl(fid); end % close the file fclose(fid); % sort attributes by aid [~,idx] = sort(aid); aid = aid(idx); vroot = vroot(idx); url = url(idx); % populate |Page| with vroot based on aid Page = cell(size(visits)); for i = 1:length(aid) Page(visits == aid(i)) = vroot(i); end % create table and write it to disk if it doesn't exist transactions = table(VisitorCookieID,Page); if exist('msweb.transactions.csv','file') == 0 % just keep the first 318 rows to use as sample data transactions(319:end,:) = []; % comment out to keep the whole thing writetable(transactions,'msweb.transactions.csv') end %% Association Rule Mining without MapReduce % Since we already have all necessary pieces of data in the workspace, we % might as well do the analysis now. % get unique uid uniq_uid = unique(vid); % create a cell array of visits that contains vroots visited transactions = cell(size(uniq_uid)); for i = 1:length(uniq_uid) transactions(i) = {visits(vid == uniq_uid(i))'}; end % find frequent itemsets of vroots from the visits minSup = 0.02; fprintf('Processing dataset with minimum support threshold = %.2f\n...\n', minSup) [F,S,items] = findFreqItemsets(transactions,minSup); fprintf('Frequent Itemsets Found: %d\n', sum(arrayfun(@(x) size(x.freqSets,1), F))) fprintf('Max Level : k = %d\n', length(F)) fprintf('Number of Support Data : %d\n\n', length(S)) % generate rules minConf = 0.6; rules = generateRules(F,S,minConf); fprintf('Minimum Confidence : %.2f\n', minConf) fprintf('Rules Found : %d\n\n', length(rules)) % plot the rules conf = arrayfun(@(x) x.Conf, rules); % get conf as a vector lift = arrayfun(@(x) x.Lift, rules); % get lift as a vector sup = arrayfun(@(x) x.Sup, rules); % get support as a vector colormap cool scatter(sup,conf,lift*5, lift, 'filled') xlabel('Support'); ylabel('Confidence') t = colorbar('peer',gca); set(get(t,'ylabel'),'String', 'Lift'); title('Microsoft Web Data') % display the selected rules selected = [1,2,3,5,18]; for i = 1:length(selected) fprintf('Rule #%d\n', selected(i)) lenAnte = length(rules(selected(i)).Ante); if lenAnte == 1 fprintf('{%s} => {%s}\nConf: %.2f, Lift: %.2f\n\n',... vroot{rules(selected(i)).Ante(1)},vroot{rules(selected(i)).Conseq},... rules(selected(i)).Conf,rules(selected(i)).Lift) elseif lenAnte == 2 fprintf('{%s, %s} => {%s}\nConf: %.2f, Lift: %.2f\n\n',... vroot{rules(selected(i)).Ante(1)},vroot{rules(selected(i)).Ante(2)},... vroot{rules(selected(i)).Conseq},rules(selected(i)).Conf,rules(selected(i)).Lift) end end %% MapReduce % My MapReduce code is not well suited for this dataset and runs extremely % slow if you use the whole dataset. I will just use just a subset for % demonstration purpose. If you want to try this on the full dataset, you % should write your own MapReduce code optimized for it. % clear everything clearvars; close all; clc % set up source datastore source_ds = datastore('msweb.transactions.csv'); disp(preview(source_ds)) % step 1: Group items by transaction transaction_ds = mapreduce(source_ds, @transactionMapper, @transactionReducer); transactions = readall(transaction_ds); % step 2: Generate 1-itemsets oneItemset_ds = mapreduce(transaction_ds, @oneItemsetMapper, @oneItemsetReducer); oneItemsets = readall(oneItemset_ds);






评论
如欲留言,请点击在这里登录您的MathWorks帐户或创建一个新帐户。