 克里夫的角落:克里夫硅藻土在数学和计算
克里夫的角落:克里夫硅藻土在数学和计算 MATLAB的博客
MATLAB的博客 史蒂夫与MATLAB图像处理
史蒂夫与MATLAB图像处理 人在仿真软件金宝app
人在仿真软件金宝app 人工智能
人工智能 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 文件交换的选择
文件交换的选择 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー 创业、加速器,和企业家
创业、加速器,和企业家 自治系统
自治系统
调查显示“学习编码”运动的多样性
你使用任何免费的“学会代码”网站自学编程?你可能已经知道如何在MATLAB程序,但你很可能学习其他技能MOOCs。
今天的嘉宾博客古原,一个公开的调查数据进行分析,以理解自学的程序员的人口。
内容
加载数据
我遇到Techcrunch的一篇文章中,自由阵营的调查显示人口的自学的程序员的代码,我很好奇,因为很多人似乎对学习感兴趣的代码,和行业和政府还鼓励这一趋势。但是编程是很困难的。到底是谁的人已经暴跌?我们的免费在线互动编程课程MATLAB学院或gamifiedMATLAB科迪也越来越受欢迎,我想了解他们的动机,这个兴趣。
匿名的调查并在网站上发布和推广通过社会媒体从3月28日到5月2日,2016年,针对相对较新的编程的人。
下面的分析显示了显著的多样性在性别和种族混合自学的程序员和网络公开课的影响开放访问服务不足人群的传统STEM教育路径。
我第一次下载2016个新编码器从Github的调查结果。我然后CSV文件解压缩到当前文件夹。有两个文件-第1部分和第2部分,我们将读到不同的表中。或许,我们可以将它们合并使用innerjoin主要感兴趣,但在这种情况下我在第2部分中,我们将从第1部分丢弃至少1000响应,响应的差异数量。
警告(“关闭”,“MATLAB:表:ModifiedVarnames”)%抑制警告csv =2016年新程序员调查1. csv的一部分;%文件名part1 = readtable (csv);%读入表part1.Properties。VariableNames =…%变量名格式regexprep (part1.Properties.VariableNames“_ + $”,”);%通过删除额外的“_”csv =2016年新程序员2. csv的一部分;%文件名第二部分= readtable (csv);%读入表part2.Properties。VariableNames =…%变量名格式regexprep (part2.Properties.VariableNames“_ + $”,”);%通过删除额外的“_”警告(“上”,“MATLAB:表:ModifiedVarnames”)%启用警告part1。SubmitDate_UTC = datetime (part1.SubmitDate_UTC);%日期字符串转换为日期时间第二部分。SubmitDate_UTC = datetime (part2.SubmitDate_UTC);%日期字符串转换为日期时间s = sprintf (part1 % d反应%年代通过% s \ n”,…%总结part1高度(part1) datestr (min (part1.SubmitDate_UTC)),…%的反应,开始日期datestr (max (part1.SubmitDate_UTC)));%和结束日期流(' % spart2 % d反应从% s通过% s的,…%总结第二部分年代,身高(第二部分),datestr (min (part2.SubmitDate_UTC)),…%的反应,开始日期datestr (max (part2.SubmitDate_UTC)));%和结束日期
part1 15653响应从29 - 3月- 2016 21:23:43通过02 - 14625年5月- 2016年19:12:44 part2反应从29 - 3月- 2016 21:25:36通过02 - 2016年5月——18:35:59
比预期更高的女性代表
让我们开始策划一个年龄批发的柱状图。罗兰指出我们可以使用omitnan国旗在中位数处理缺失值代替nanmedian。
直方图显示,很多人对这个调查陷入所谓的“黄金时代”的类别。有趣的是回应这项调查的女性的数量,考虑到经常被引用在干细胞领域的性别差异。目前还不清楚这反映了真正的人口或女性比例过高通过自己挑选吗?或者以某种方式自学编程比传统教学更吸引女人?
年龄= part2.HowOldAreYou;%得到年龄从第二部分性别=分类(part2.What_sYourGender);%从第二部分获得性别分类第二部分。What_sYourGender =性别;%更新表图%的新人物x =年龄(年龄性别= = ~ = 0 &“男”);年龄,性别%子集直方图(x)%绘制柱状图文本(50550年,sprintf (平均年龄(男):% d ',…%注释中位数(x,“omitnan”)))文本(50470年,sprintf (”模式年龄(男):% d '模式(x)))%注释持有在%不覆盖x =年龄(年龄性别= = ~ = 0 &“女”);年龄,性别%子集直方图(x)%绘制柱状图文本(50520年,sprintf (的年龄中位数(女性):% d ',…%注释中位数(x,“omitnan”)))文本(50440年,sprintf (”模式年龄(女):% d '模式(x)))%注释持有从%恢复默认标题(按性别年龄分布的)%添加标题包含(“年龄”)%添加x轴标签ylabel (“数”)%添加y轴标签传奇(“男”,“女”)%添加传奇

主要留学国家的国籍
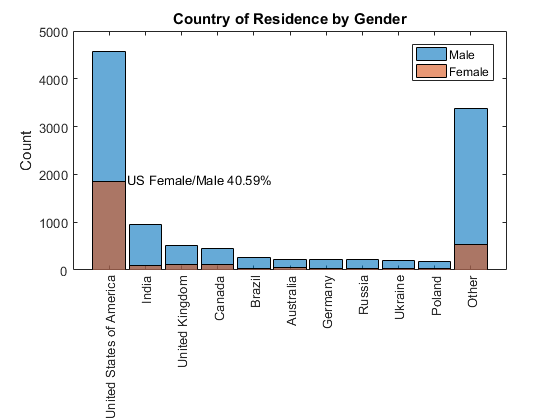
自网上的调查是,任何人都可以参与。让我们检查一下地理细分。如你所愿,最大的部分响应来自美国。您还可以看到,女性的反应在美国,40.59%的男性反应证实高女性代表的反应。
中国十大国家的明显缺失。也许是“学会代码”巴兹没有了吗?
第二部分。WhichCountryDoYouCurrentlyLiveIn =…%转换为分类分类(part2.WhichCountryDoYouCurrentlyLiveIn);国家= part2.WhichCountryDoYouCurrentlyLiveIn;%获得居住国catcount = countcats(国家);%得到类别数猫=类别(国家);%得到类别[~,排名]=排序(catcount,“下”);%等级分类计数below_top10 = setdiff(猫,猫(等级(1:10)));%类别下面的前10名below_top10 = mergecats(国家,“其他”);%将它们合并到其他= reordercats(国家,猫(等级(1:10)),{“其他”}));%重新排序猫的排名率=(国家= =“美利坚合众国”&…%的女性/男性比例性别= =“女”)/笔(国家= =“美利坚合众国”&性别= =“男”);图%的新人物直方图(国家(性别= =“男”))%绘制柱状图持有在%不覆盖直方图(国家(性别= =“女”))%绘制柱状图持有从%恢复默认甘氨胆酸ax =;%得到当前的斧柄斧子。XTickLabelRotation = 90;%旋转x标记标签标题(“居住国的性别”)%添加标题ylabel (“数”)%添加y轴标签传奇(“男”,“女”)%添加传奇文本(1.5,1900年,sprintf (“我们女性/男性% .2f % %”比率* 100))%注释
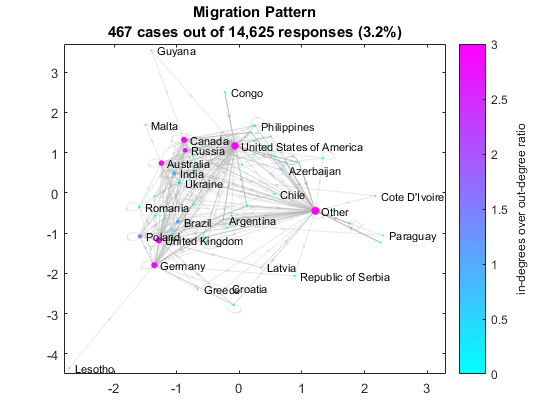
你也可以想象迁徙模式映射国家公民的居住的国家。边的数量是467,这意味着只有467的14625反应可能来自移民,大多数人在他们的国家公民的生活和学习。如果你把移民在移民,比美国、英国、加拿大、澳大利亚德国和俄罗斯享受净收益人才流失。
第二部分。WhichCountryAreYouACitizenOf =…%转换为分类分类(part2.WhichCountryAreYouACitizenOf);国籍= part2.WhichCountryAreYouACitizenOf;%获得国籍台=表(cellstr(国籍),cellstr(国家));%创建表的住所和国籍台(isundefined(国籍)& isundefined(国家):)= [];%下降空行台。(1)(strcmp(台。(1),“<定义>”))=…%使用住宅是否emtpy国籍台。(2)(strcmp(台。(1),“<定义>”));台。(2)(strcmp(台。(2),“<定义>”))=…如果住宅emtpy %使用公民身份台。(1)(strcmp(台。(2),“<定义>”));(资源描述,~,idx] =独特(资源描述,“行”);%消除重复的行w = accumarray (idx, 1);%使用重复的计算重量G =有向图(台。(1),(资源。(2),w);%建立一个有向图indeg =入度(G);%得到度比率= indeg. /出度(G);%得到度比/出度图%的新人物colormap很酷的%设置colormapw = G.Edges.Weight;%得到权重h =情节(G,“MarkerSize”日志(indeg + 2),“NodeCData”比,…%绘制方向图“EdgeColor”,(。7。7。7],“EdgeAlpha”,0.3,“线宽”10 * w / max (w));caxis ([0 3])%设置颜色轴缩放轴([-2.8 - 3.3 -4.5 - 3.7])%设置轴的限制标题({“迁移模式”;…%添加标题的467例14625反应(3.2%)})labelnode (h,猫(等级(1:10)),猫(等级(1:10)))%标签前10名的节点nlabels = {“阿根廷”,“阿塞拜疆”,“智利”,“刚果”,…%额外的节点标签“科特迪瓦“象牙”,克罗地亚的,“希腊人”,圭亚那的,拉脱维亚的,莱索托的,…“马耳他”,“其他”,“巴拉圭”,“菲律宾”,“塞尔维亚共和国”,“罗马尼亚”};labelnode (h, nlabels, nlabels);%标签附加节点h = colorbar;%添加colorbarylabel (h,有关学位比度过去)%增加指标
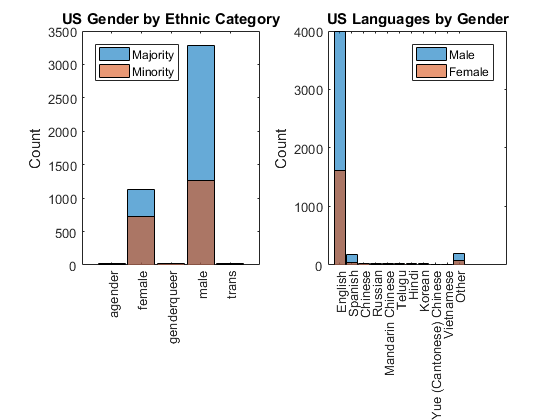
种族多元化的英语为母语的人在美国
让我们关注美国。如前所述,大多数新自学的程序员回应这项调查是美国公民,但其民族化妆品非常多样化。超过一半的女性是少数民族,所以是男性的1/3。他们也以英语为主,考虑到移民的比例低。然而,我们应该注意到,调查本身是英语和提升英语通过社会媒体。
isminority = part2.AreYouAnEthnicMinorityInYourCountry;%得到monority状态图%的新人物次要情节(1、2、1)%创建一个次要情节性别(x = = =“美利坚合众国”…%子集& isminority = = 0);%我们non-minority直方图(x)%绘制柱状图持有在%不覆盖性别(x = = =“美利坚合众国”…%子集性别& isminority = = 1);%由美国少数民族直方图(x)%绘制柱状图持有从%恢复默认标题(“我们性别种族类别”)%添加标题ylabel (“数”)%添加y轴标签传奇(“大多数”,“少数民族”,“位置”,“西北”)%添加传奇第二部分。WhichLanguageDoYouYouSpeakAtHomeWithYourFamily =…%转换为分类分类(part2.WhichLanguageDoYouYouSpeakAtHomeWithYourFamily);语言= part2.WhichLanguageDoYouYouSpeakAtHomeWithYourFamily;%获得语言美国=语言(国家= =“美利坚合众国”);%提取我们数据catcount = countcats(美国);%得到类别数猫=类别(美国);%得到类别[~,排名]=排序(catcount,“下”);%等级分类计数below_top10 = setdiff(猫,猫(等级(1:10)));%类别下面的前10名美国= mergecats(美国、below_top10、“其他”);%将它们合并到其他美国= reordercats(美国,猫(等级(1:10));{“其他”}));%重新排序猫的排名甘氨胆酸ax =;%得到当前的斧柄斧子。XTickLabelRotation = 90;%旋转x标记标签次要情节(1、2、2)%创建一个次要情节直方图(美国(性别(国家= =…%绘制柱状图“美利坚合众国”)= =“男”))%我们性别语言的子集持有在%不覆盖直方图(美国(性别(国家= =…%绘制柱状图“美利坚合众国”)= =“女”))%我们性别语言的子集持有从%恢复默认标题(“我们按性别语言”)%添加标题ylabel (“数”)%添加y轴标签传奇(“男”,“女”)%添加传奇
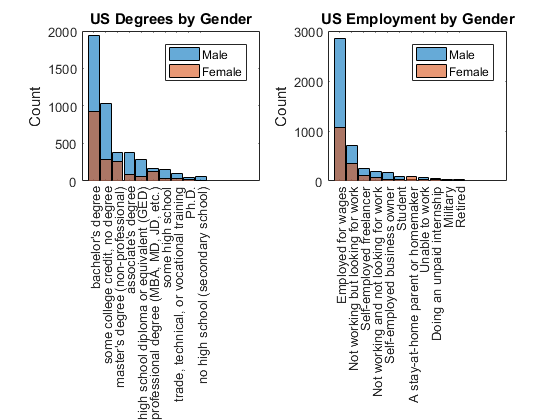
很多人都受过高等教育,已经在美国就业
我们已经知道网络公开课很多人已经获得大学学历和工作。这个调查还显示相同的结果。
第二部分。What_sTheHighestDegreeOrLevelOfSchoolYouHaveCompleted =…%转换为分类分类(part2.What_sTheHighestDegreeOrLevelOfSchoolYouHaveCompleted);度= part2.What_sTheHighestDegreeOrLevelOfSchoolYouHaveCompleted;%获得学位美国(国家= = =学位“美利坚合众国”);%提取我们数据catcount = countcats(美国);%得到类别数猫=类别(美国);%得到类别[~,排名]=排序(catcount,“下”);%等级分类计数美国= reordercats(美国,猫(等级);%重新排序猫的排名图%的新人物次要情节(1、2、1)%创建一个次要情节直方图(美国(性别(国家= =…%绘制柱状图“美利坚合众国”)= =“男”))%由性别子集美国学位持有在%不覆盖直方图(美国(性别(国家= =…%绘制柱状图“美利坚合众国”)= =“女”))%由性别子集美国学位持有从%恢复默认标题(“我们度按性别”)%添加标题ylabel (“数”)%添加y轴标签传奇(“男”,“女”)%添加传奇第二部分。RegardingEmploymentStatus_AreYouCurrently =…%转换为分类分类(part2.RegardingEmploymentStatus_AreYouCurrently);就业= part2.RegardingEmploymentStatus_AreYouCurrently;%得到就业其他= part2.Other;%得到其他就业isstudent = 0(大小(其他));%建立一个累加器有趣= @ (x, y) ~ cellfun (@isempty, strfind(低(x), y));%匿名函数处理isstudent(有趣,“学生”))= 1;%如果找到“学生”isstudent(有趣,“学习”))= 1;如果找到‘学习’%国旗isstudent(有趣,“学校”))= 1;%如果找到“学校”isstudent(有趣,“大学”))= 1;%如果找到“大学”isstudent(有趣,“度”))= 1;如果发现‘度’%国旗isstudent(有趣,“博士”))= 1;如果发现‘博士’%国旗就业(逻辑(isstudent)) =“学生”;%更新就业美国就业(国家= = =“美利坚合众国”);%提取我们数据catcount = countcats(美国);%得到类别数猫=类别(美国);%得到类别[~,排名]=排序(catcount,“下”);%等级分类计数美国= reordercats(美国,猫(等级);%重新排序猫的排名次要情节(1、2、2)%创建一个次要情节直方图(美国(性别(国家= =…%绘制柱状图“美利坚合众国”)= =“男”))我们就业的性别%子集持有在%不覆盖直方图(美国(性别(国家= =…%绘制柱状图“美利坚合众国”)= =“女”))我们就业的性别%子集持有从%恢复默认标题(“我们就业的性别”)%添加标题ylabel (“数”)%添加y轴标签传奇(“男”,“女”)%添加传奇
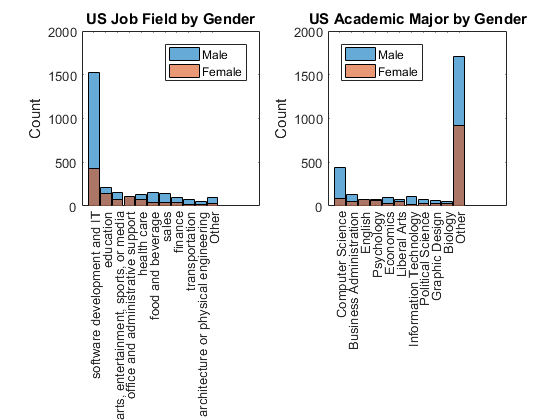
许多人已经在软件开发和它在我们工作
事实证明,许多受访者已经在软件开发领域工作,来自非常不同acadamic背景,包括干细胞以及non-STEM科目。因为女性的比例往往是高non-STEM专业,这也许可以解释为什么我们看到在这个调查比预期更高的女性代表。看来,女性受访者研究non-STEM主修本科现在追求从事软件开发。
奇怪的是,我们还看到许多计算机科学专业,他们往往是男人。为什么人已经有一个计算机科学背景追求自我编程吗?难道他们在学校学过了吗?
第二部分。WhichFieldDoYouWorkIn =…%转换为分类分类(part2.WhichFieldDoYouWorkIn);工作= part2.WhichFieldDoYouWorkIn;%得到工作工作= mergecats(工作,{软件开发和它的,…%合并相似的类别“软件开发”});us_job(国家= = =工作“美利坚合众国”);%提取我们数据catcount = countcats (us_job);%得到类别数猫=类别(us_job);%得到类别[~,排名]=排序(catcount,“下”);%等级分类计数below_top10 = setdiff(猫,猫(等级(1:10)));%类别下面的前10名us_job = mergecats (us_job below_top10,“其他”);%将它们合并到其他us_job = reordercats (us_job,猫(等级(1:10));{“其他”}));%重新排序猫的排名图%的新人物次要情节(1、2、1)%创建一个次要情节直方图(us_job(性别(国家= =…%绘制柱状图“美利坚合众国”)= =“男”))我们按性别主题%子集持有在%不覆盖直方图(us_job(性别(国家= =…%绘制柱状图“美利坚合众国”)= =“女”))我们按性别主题%子集持有从%恢复默认标题(“我们就业领域性别”)%添加标题ylabel (“数”)%添加y轴标签传奇(“男”,“女”)%添加传奇第二部分。WhatWasTheMainSubjectYouStudiedInUniversity =…%转换为分类分类(part2.WhatWasTheMainSubjectYouStudiedInUniversity);主要= part2.WhatWasTheMainSubjectYouStudiedInUniversity;%得到学术大us_maj主要(国家= = =“美利坚合众国”);%提取我们数据catcount = countcats (us_maj);%得到类别数猫=类别(us_maj);%得到类别[~,排名]=排序(catcount,“下”);%等级分类计数below_top10 = setdiff(猫,猫(等级(1:10)));%类别下面的前10名us_maj = mergecats (us_maj below_top10,“其他”);%将它们合并到其他us_maj = reordercats (us_maj,猫(等级(1:10));{“其他”}));%重新排序猫的排名次要情节(1、2、2)%创建一个次要情节直方图(us_maj(性别(国家= =…%绘制柱状图“美利坚合众国”)= =“男”))我们按性别主题%子集持有在%不覆盖直方图(us_maj(性别(国家= =…%绘制柱状图“美利坚合众国”)= =“女”))我们按性别主题%子集持有从%恢复默认标题(“美国学术主要由性别”)%添加标题ylabel (“数”)%添加y轴标签传奇(“男”,“女”,“位置”,“西北”)%添加传奇
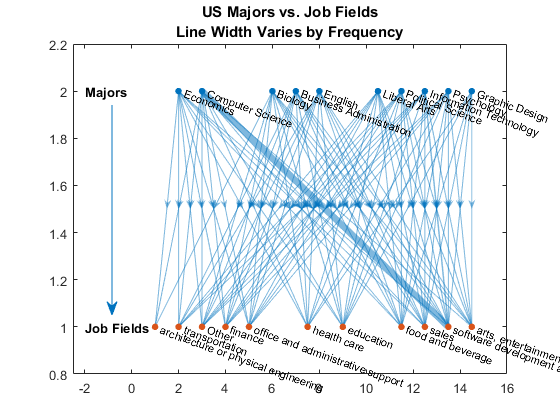
这是一个快速检查。是的,那些计算机科学专业似乎在软件开发工作,表明它们之间的线宽边。
台=表(cellstr (us_maj) cellstr (us_job));我们主要和我们工作的%创建表台(isundefined (us_maj) | isundefined (us_job) |…%去除未定义us_maj = =“其他”:)= [];%删除“其他”从我们的专业(资源描述,~,idx] =独特(资源描述,“行”);%消除重复的行w = accumarray (idx, 1);%使用重复的计算重量G =有向图(台。(1),(资源。(2),w);%建立一个有向图图%的新人物w = G.Edges.Weight;%得到权重h =情节(G,“布局”,“分层”,“线宽”5 * w / max (w));%画出有向图xlim (-2.5 [16])% x轴的限制突出(h,独特的(台(2)),“NodeColor”,(。85。33。1])%突出工作节点标题({我们专业与工作领域的;…%添加标题线宽随频率的})文本(2,2,“专业”,“FontWeight”,“大胆”)%注释文本(2,1,“田野工作”,“FontWeight”,“大胆”)%注释注释(“箭头”,(。2。2],[.75 .25],“颜色”,[0点。)%注释
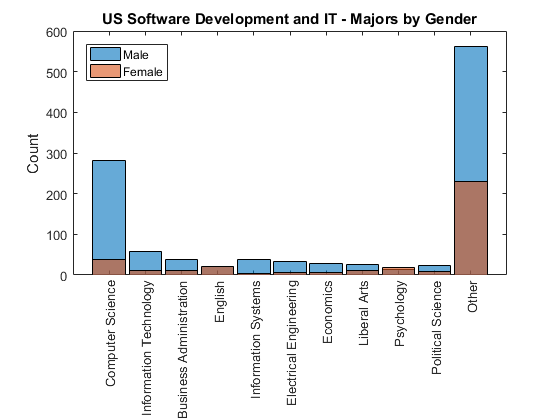
在软件开发和学术背景
深潜水在软件开发,我们发现并不是每个人都是一个计算机科学专业,不同学术背景反映在该行业,在不同的职业轨迹,也许他们说的是基于他们的背景。女性代表比例在英语、心理学等。
us_maj_it主要(国家= = =“美利坚合众国”…主要由国家%子集&工作= =软件开发和它的);%和工作catcount = countcats (us_maj_it);%得到类别数猫=类别(us_maj_it);%得到类别[~,排名]=排序(catcount,“下”);%等级分类计数below_top10 = setdiff(猫,猫(等级(1:10)));%类别下面的前10名us_maj_it = mergecats (us_maj_it below_top10,“其他”);%将它们合并到其他us_maj_it = reordercats (us_maj_it,猫(等级(1:10));{“其他”}));%重新排序猫的排名图%的新人物直方图(us_maj_it(性别(国家= =…%绘制柱状图“美利坚合众国”&…%子集我们课题的工作工作= =软件开发和它的)= =“男”))%和性别持有在%不覆盖直方图(us_maj_it(性别(国家= =…%绘制柱状图“美利坚合众国”&…%子集我们课题的工作工作= =软件开发和它的)= =“女”))%和性别持有从%恢复默认甘氨胆酸ax =;%得到当前的斧柄斧子。XTickLabelRotation = 90;%旋转x标记标签标题(“我们软件开发和它——专业性别的)%添加标题ylabel (“数”)%添加y轴标签传奇(“男”,“女”,“位置”,“西北”)%添加传奇
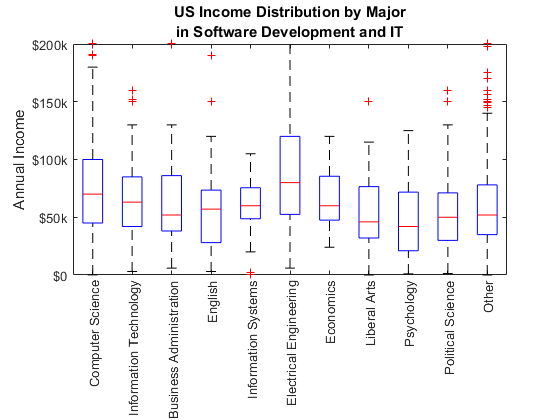
在软件开发中,它的收入差距
让我们来比较一下工作范围的收入领域使用箱线图。底部和顶部的盒子代表第一和第三分位数和中间的红线代表中间,和胡须代表+ / - 2.7个标准差。红色的“+”s显示异常值。
与其他工作领域相比,收入在软件开发中,它有一个宽范围传播(如elongnated框所示形状和长晶须),意思是有很好的潜力做得更好。
收入= part2.AboutHowMuchMoneyDidYouMakeLastYear_inUSDollars;%获得收入收入= str2double(收入);%转换为数字收入(收入= = 0)=南;%不计数为零us_income = = =收入(国家“美利坚合众国”);%提取我们数据图%的新人物箱线图(us_income us_job)%创建一个箱线图ylim ([0 2 * 10 ^ 5])%设置上限标题(美国收入分配的工作领域的)%添加标题甘氨胆酸ax =;%得到当前的斧柄斧子。XTickLabelRotation = 90;%旋转x标记标签斧子。YTickLabel = {“0”,“$ 50 k”,“100美元”,“150美元”,“200美元”};%集合y蜱虫标签ylabel (的年收入)%添加y轴标签

它会影响收入在软件开发和什么?
第一个因素可能影响收入在软件开发和学术背景。箱线图显示,计算机科学和电子工程给你最优势的获得更高的薪水。这可能是自主学习的动机,编码的趋势——人们想切换到一个更lucrativie职业道路从他们当前的路径或更快地推进在同一行业。
us_income_it = = =收入(国家“美利坚合众国”…%子集收入的国家&工作= =软件开发和它的);%和工作图%的新人物箱线图(us_income_it us_maj_it)%创建一个箱线图ylim ([0 2 * 10 ^ 5])%设置上限标题({美国收入分配的主要的,…。%添加标题在软件开发中,它的甘氨胆酸ax =});%得到当前的斧柄斧子。XTickLabelRotation = 90;%旋转x标记标签斧子。YTickLabel = {“0”,“$ 50 k”,“100美元”,“150美元”,“200美元”};%集合y蜱虫标签ylabel (的年收入)%添加y轴标签
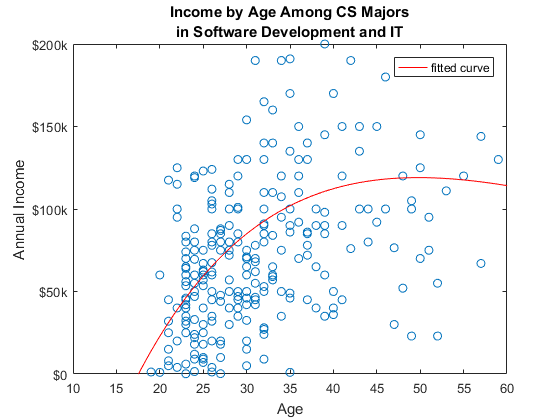
年龄因素
另一个重要的要考虑的因素是年龄。如果你把年龄与收入在软件开发和,你看到一个年轻的计算机科学专业之间的收入差距也很大。25岁可以赚0和110000美元一年。收入也随着你的年龄似乎高原。您可以使用适合与exp2选项应用一个连任两届指数曲线所以你可以很容易看到奥运会场址的数据。也许这为计算机科学专业提供了动力,尽快提高他们的技能和经验?
us_age_it = = =年龄(国家“美利坚合众国”…%子集年龄&工作= =软件开发和它的);%和工作X = us_age_it (us_maj_it = =“计算机科学”);只是CS %子集Y = us_income_it (us_maj_it = =“计算机科学”);只是CS %子集图%的新人物情节(X, Y,“o”)%绘制数据持有在%不覆盖missingrows = isnan (X) | isnan (Y);%找到nanX (missingrows) = [];%去除nanY (missingrows) = [];%去除nanfitresult =适合(X, Y,“exp2”);%适合exp2情节(fitresult)%绘制曲线持有从%恢复默认标题({的收入,年龄在计算机科学专业;…%添加标题在软件开发中,它的})xlim (60 [10])%设置x轴的极限ylim ([0 2 * 10 ^ 5])%限定y轴甘氨胆酸ax =;%得到当前的斧柄斧子。YTick = 0:50000:200000;%集合y蜱虫斧子。YTickLabel = {“0”,“$ 50 k”,“100美元”,“150美元”,“200美元”};%集合y蜱虫标签包含(“年龄”)%添加x轴标签ylabel (的年收入)%添加y轴标签
大公司不喜欢
如果你看看未来就业的人,他们更喜欢大公司。由于人们没有获得正式的学位,他们可能在其他就业选择期望更大的灵活性。
最受欢迎的选择是中型企业,但许多人感兴趣为创业公司工作,开始自己的生意,或者自由职业者。人们在软件开发中,它更倾向于为启动或中型企业工作。男性更倾向于为创业做自己的生意或工作,而女性倾向于自由的道路。
第二部分。want_employment_type =…%转换为分类分类(part2.want_employment_type);interested_emp = part2.want_employment_type;%得到感兴趣的工作类型图%的新人物次要情节(1、2、1)%创建一个次要情节us_int_emp_it = interested_emp(国家= =…%子集通过国家和工作“美利坚合众国”&工作= =软件开发和它的);us_int_emp_it (isundefined (us_int_emp_it)) = [];%去除未定义us_int_emp_it = removecats (us_int_emp_it);%删除未使用的类别直方图(us_int_emp_it“归一化”,“概率”)%绘制柱状图持有在%不覆盖us_int_emp_non_it = interested_emp(国家= =…%子集通过国家和工作“美利坚合众国”~ = &工作软件开发和它的);us_int_emp_non_it (isundefined (us_int_emp_non_it)) = [];%去除未定义us_int_emp_non_it = removecats (us_int_emp_non_it);%删除未使用的类别直方图(us_int_emp_non_it“归一化”,“概率”)%绘制柱状图持有从%恢复默认标题({“我们期望的就业类型”;在工作领域的})%添加标题甘氨胆酸ax =;%得到当前的斧柄斧子。XTickLabelRotation = 90;%旋转x标记标签斧子。YTick = 0:0.1:0.6;%集合y蜱虫斧子。YTickLabel = {“0%”,“10%”,“20%”,“30%”,“40%”,“50%”,“60%”};%集合y蜱虫标签传奇(“软件开发和IT”,“别人”)%添加传奇ylim (0.6 [0])%限定y轴次要情节(1、2、2)%创建一个次要情节us_int_emp_m = interested_emp(国家= =…%的子集“美利坚合众国”&性别= =“男”);%的性别us_int_emp_m (isundefined (us_int_emp_m)) = [];%去除未定义us_int_emp_m = removecats (us_int_emp_m);%删除未使用的类别直方图(us_int_emp_m“归一化”,“概率”)%绘制柱状图持有在%不覆盖us_int_emp_f = interested_emp(国家= =…%的子集“美利坚合众国”&性别= =“女”);%的性别us_int_emp_f (isundefined (us_int_emp_f)) = [];%去除未定义us_int_emp_f = removecats (us_int_emp_f);%删除未使用的类别直方图(us_int_emp_f“归一化”,“概率”)%绘制柱状图持有从%恢复默认标题({“我们期望的就业类型”;“性别”})%添加标题甘氨胆酸ax =;%得到当前的斧柄斧子。XTickLabelRotation = 90;%旋转x标记标签斧子。YTick = 0:0.1:0.6;%集合y蜱虫斧子。YTickLabel = {“0%”,“10%”,“20%”,“30%”,“40%”,“50%”,“60%”};%集合y蜱虫标签传奇(“男”,“女”)%添加传奇ylim (0.6 [0])%限定y轴

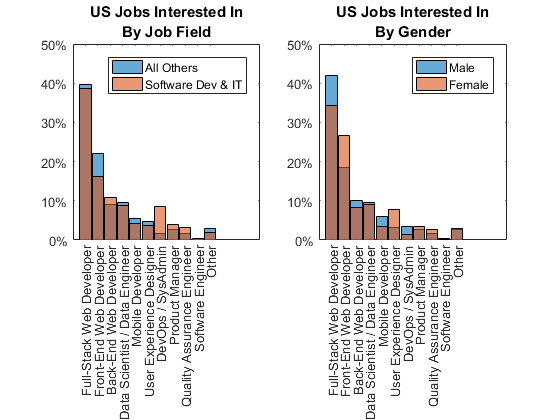
梦想的工作
当涉及到实际工作感兴趣的人,他们大多是web开发职位。人们已经在软件开发中,更倾向于具有较高技术技能——的角色后端Web开发,DevOps,或系统管理员而不是前端Web开发或其他非开发性产品经理或质量工程师等角色。在性别方面,女性更愿意前端Web开发用户体验设计。
int_job =分类(strtrim (part2.jobs_interested_in));%得到感兴趣的工作catcount = countcats (int_job);%得到类别数猫=类别(int_job);%得到类别[~,排名]=排序(catcount,“下”);%等级分类计数below_top10 = setdiff(猫,猫(等级(1:10)));%类别下面的前10名int_job = mergecats (int_job below_top10,“其他”);%将它们合并到其他int_job = reordercats (int_job,猫(等级(1:10)),{“其他”}));%重新排序猫的排名图%的新人物次要情节(1、2、1)%创建一个次要情节us_int_job_non_it = int_job(国家= =…%子集int工作由国家和工作“美利坚合众国”~ = &工作软件开发和它的);直方图(us_int_job_non_it“归一化”,“概率”)%绘制柱状图持有在%不覆盖us_int_job_it = int_job(国家= =…%子集int工作由国家和工作“美利坚合众国”&工作= =软件开发和它的);直方图(us_int_job_it“归一化”,“概率”)%绘制柱状图持有从%恢复默认标题({“我们感兴趣的工作”;在工作领域的})%添加标题传奇(“其他”,“软件开发&”)%添加传奇甘氨胆酸ax =;%得到当前的斧柄斧子。YTick = 0:0.1:0.5;%集合y蜱虫斧子。YTickLabel = {“0%”,“10%”,“20%”,“30%”,“40%”,“50%”};%集合y蜱虫标签ylim (0.5 [0])%限定y轴次要情节(1、2、2)%创建一个次要情节us_int_job_m = int_job(国家= =…%子集int工作的国家“美利坚合众国”&性别= =“男”);%和性别直方图(us_int_job_m“归一化”,“概率”)%绘制柱状图持有在%不覆盖us_int_job_f = int_job(国家= =…%子集int工作的国家“美利坚合众国”&性别= =“女”);%和性别直方图(us_int_job_f“归一化”,“概率”)%绘制柱状图持有从%恢复默认标题({“我们感兴趣的工作”;“性别”})%添加标题传奇(“男”,“女”)%添加传奇甘氨胆酸ax =;%得到当前的斧柄斧子。YTick = 0:0.1:0.5;%集合y蜱虫斧子。YTickLabel = {“0%”,“10%”,“20%”,“30%”,“40%”,“50%”};%集合y蜱虫标签ylim (0.5 [0])%限定y轴
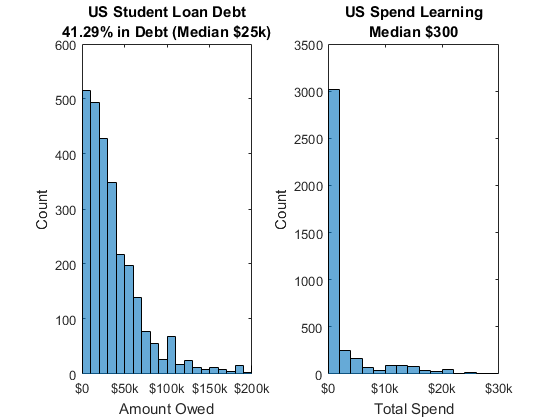
学生贷款债务
调查还回答了多少学生贷款债务受访者和他们花多少学习代码。超过41%的受访者有学生贷款债务和欠量中值是25000美元。此外,人们花在学习代码,和中位数总花费是300美元。鉴于很多人债务,他们不能花更多的钱,增加赤字,这也反映出在未来更为保守的选择就业。
债务= part2.AboutHowMuchDoYouOweInStudentLoans_inUSDollars;%得到学生负担债务债务= str2double(债务);%转换为数字负债(债务= = 0)=南;%不计数为零us_debt = = =债务(国家“美利坚合众国”);%提取我们数据pct_in_debt =总和(~ isnan (us_debt)) /长度(us_debt) * 100;%的债务比例median_debt = nanmedian (us_debt) / 1000;%的平均债务图%的新人物次要情节(1、2、1)%创建一个次要情节直方图(us_debt)%绘制柱状图xlim ([0 2 * 10 ^ 5])%限定y轴甘氨胆酸ax =;%得到当前的斧柄斧子。XTick = 0:50000:200000;%集合x蜱虫斧子。XTickLabel = {“0”,“$ 50 k”,“100美元”,“150美元”,“200美元”};%集合x标记标签包含(“金额”)%添加x轴标签ylabel (“数”)%添加y轴标签标题({美国学生贷款债务的;…%添加标题sprintf (' %。2f%% in Debt (Median $%dk)'、pct_in_debt median_debt)})次要情节(1、2、2)%创建一个次要情节花= part2.total_spent_learning;%得到总花花= str2double(花);%转换为数字花(花= = 0)=南;%不计数为零us_spend =花(国家= =“美利坚合众国”);%提取我们数据直方图(us_spend)%绘制柱状图xlim ([0 3 * 10 ^ 4])%限定y轴甘氨胆酸ax =;%得到当前的斧柄斧子。XTick = 0:10000:30000;%集合x蜱虫斧子。XTickLabel = {“0”,“10 k美元”,“$ 20 k”,“$ 30 k”};%集合x标记标签包含(“花总”)%添加x轴标签ylabel (“数”)%添加y轴标签标题({“我们花学习”;sprintf (的中位数$ % d ',…%添加标题nanmedian (us_spend))})
女性更喜欢更友好的场所
这项调查似乎显示更多女性参与“学习编码”运动相比,一个更传统的计算机科学教育。当你看女人喜欢的类型事件,他们表现出强烈的偏爱性别事件像“女孩开发”和“代码”的女人。当你看网上的资源,你看不到太多的性别差异。看来,实际存在的男性让女性感到不受欢迎。
events_attended = part2.attended_event_types;%得到事件了events_attended = cellfun (@ (x) strsplit (x,”、“),…%由逗号分割events_attended,“UniformOutput”、假);(events_attended events_attended_flatten = strtrim ({}):);% un-nest和修剪[ia ~, ib] =独特(低(events_attended_flatten));%得到指标的暗金物品事件= events_attended_flatten (ia);%获得独特的价值观数= accumarray (ib, 1);%计算独特的价值观事件(计数< 100)= [];%下降不受欢迎的事件事件(strcmpi(事件,“没有”))= [];%下降'没有'事件(cellfun (@isempty、事件))= [];%下降空单元参加= 0(长度尺寸(events_attended, 1),(事件));%设置蓄电池为i = 1:尺寸(events_attended, 1)%循环事件了参加了(我:)= ismember(事件,strtrim (…%之间找到交集events_attended{我}));%活动和参加活动结束attended_m =总和(参加了(国家= =…参加了国家%子集“美利坚合众国”&性别= =“男”:));%和性别attended_f =总和(参加了(国家= =…参加了国家%子集“美利坚合众国”&性别= =“女”:));%和性别gender_ratio = attended_m。/笔(attended_m);%被事件男性比率gender_ratio = [gender_ratio;attended_f. /笔(attended_f)];%增加男女比例图%的新人物次要情节(1、2、1)%创建一个次要情节b =酒吧(gender_ratio ',“FaceColor”,[0点。)…%创建一个条形图“FaceAlpha”6);%与直方图的颜色(2)。FaceColor = [。85 .33。1);%与直方图的颜色甘氨胆酸ax =;%得到当前的斧柄斧子。XTickLabel =事件;%集合x标记标签斧子。XTickLabelRotation = 90;%旋转x标记标签斧子。YTick = 0:0.1:0.4;%集合y蜱虫斧子。YTickLabel = {“0%”,“10%”,“20%”,“30%”,“40%”};%集合y蜱虫标签标题(美国受欢迎的活动参加的)%添加标题传奇(“男”,“女”)%添加传奇次要情节(1、2、2)%创建一个次要情节resources_used = part2.learning_resources;%得到资源使用resources_used = cellfun (@ (x) strsplit (x,”、“),…%由逗号分割resources_used,“UniformOutput”、假);(resources_used resources_used_flatten = strtrim ({}):);% un-nest和修剪[ia ~, ib] =独特(低(resources_used_flatten));%得到指标的暗金物品资源= resources_used_flatten (ia);%获得独特的价值观数= accumarray (ib, 1);%计算独特的价值观资源(数量< 100)= [];%下降不受欢迎的资源资源(cellfun (@isempty、资源))= [];%下降空单元使用= 0(长度尺寸(resources_used, 1),(参考资料));%设置蓄电池为i = 1:尺寸(resources_used, 1)%循环使用资源使用(我:)= ismember(资源、strtrim (…%之间找到交集resources_used{我}));%资源和资源使用结束usage_m = = =总和(使用(国家…使用%子集“美利坚合众国”&性别= =“男”:));%和性别usage_f = = =总和(使用(国家…使用%子集“美利坚合众国”&性别= =“女”:));%和性别gender_ratio = usage_m。/笔(usage_m);%得到男性比资源gender_ratio = [gender_ratio;usage_f。/笔(usage_f)];%增加男女比例b =酒吧(gender_ratio ',“FaceColor”,[0点。)…%创建一个条形图“FaceAlpha”6);%与直方图的颜色(2)。FaceColor = [。85 .33。1);%与直方图的颜色甘氨胆酸ax =;%得到当前的斧柄斧子。XTickLabel =资源;%集合x标记标签斧子。XTickLabelRotation = 90;%旋转x标记标签斧子。YTick = 0:0.1:0.3;%集合y蜱虫斧子。YTickLabel = {“0%”,“10%”,“20%”,“30%”};%集合y蜱虫标签标题(“我们常用的资源)%添加标题传奇(“男”,“女”)%添加传奇

举个例子,我鼓励我的女儿参加机器人竞赛团队在她的高中。她跟她的朋友,因为她不想只是女孩的团队和一群女孩加入团队。当她从第一次团队会议回来,我问她什么工作。她说:“我们致力于团队网页”。原来男孩在建筑机器人和女孩离开,所以他们在构建团队的web页面。的包交付给团队时,男孩就挤在一起,也不打扰,包括女孩。女孩没有有意识地排除在外,但他们感到不受欢迎。我怀疑类似的动力学可能在玩女人去编码事件。
我也想知道女性偏好的前端Web开发和用户体验设计也是由同样的问题吗?
总结
也许最有趣的结果的分析是“学习编码”运动有效地缩小性别差距在软件开发和IT,受到传统教育的少数民族社区服务不足的路径。它还强调了不稳定的位置那些学习者面临由于高的学生贷款债务。最终我们不知道有多少人实现他们梦想的工作的就业从这个调查中,希望有一个后续发现“学习代码”运动是否真的提供承诺。
你用这些“学会代码”网络公开课网站或其他?你学习,你把这些类的动机是什么?请分享你的经验在这里!


另请参阅
-

速配实验
博客
-

预测当人们离开他们的工作
博客





评论
要发表评论,请点击此处登录到您的MathWorks帐户或创建一个新帐户。