聚类分析最快的方法是使用Anwendung von clustering algorithm和Erkennung versteckter Muster on Gruppierungen in einem Datensatz。您可以在häufig的探索性数据分析中找到答案,如果发现异常外星人,您可以在überwachten Lernen找到答案。
聚类算法bilden Gruppierungen auf eine Weise, dass Daten einer Gruppe (odereines Clusters) in höheres Maß and Ähnlichkeit aufweisen als Daten in anderen cluster。e können verschiedene Ähnlichkeitsmaße herangezogen werden, z. B. euklidisch, Kosinusabstand and correlation的概率论。我的方法是unuberwachten Lernens从聚类分析的形式。
聚类算法lassen sich in zwei große Gruppen einteilen:
- Das harte群集,bei dem jder Datenpunkt ausschließlich zu einem群集gehört, wie z. B. die beliebtek-Means-Methode。
- Das weiche Clustering, bei dem jder Datenpunkt zu mehr als einem Cluster gehören kann, wie z. B. bei der gaß schen verilungskurve。Als Beispiele seien Phoneme in der Sprache genant, die Als combined aus mehren Grundlauten modelliert werden können, sowie Gene, die an mehren biologischen Prozessen beteiligt sein können。

Das k-Means-Clustering repräsentiert Gruppen durch ihren Schwerpunkt - den Durchschnitt der einzelnen Elemente, dargestellt durch die Sterne in der Abbildung oben。
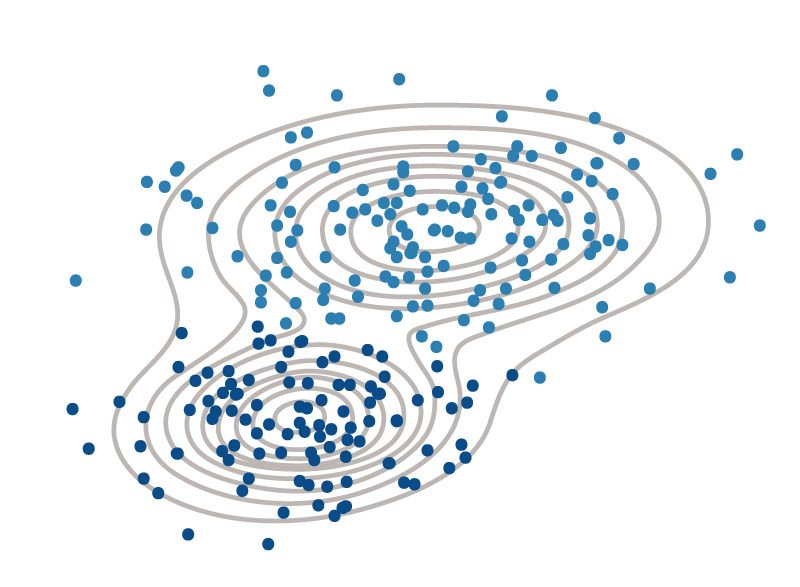
Die Gaußsche Verteilungskurve, Die Wahrscheinlichkeiten für Die Zugehörigkeit zu clusterzuweist和Die Stärke der联合麻省verschiedenen clusterdarstellt。
在einer Vielzahl von Domänen和Anwendungen eingesett的聚类分析中,um Muster and Sequenzen zu identifiieren:
- 簇können在Datenkomprimierungsverfahren die Daten anstelle des Rohsignals darstellen。
- 聚类在分割算法中的应用。
- 在生物信息学中发现的遗传学聚类和序列分析。
聚类技术我们可以使用以下方法:Ähnlichkeit zwischen gelabelten und ungelabelten Daten beim teilüberwachten Lernen(半监督学习)herzustellen,我们可以使用以下方法建立模型:最小的gelabelten Daten erstellt werden und dazu verwendet werden, den ursprünglich ungelabelten Daten Label zuzuweisen。Im Gegensatz dazu bezieht das teilüberwachte Clustering verfügbare Informationen über die Clusterin den Clustering- prozess ein, so zum Beispiel, wenn bekannt ist, dass eige Beobachtungen zum selben Cluster gehören, oder wenn mehrere Cluster mit einer bgebnisvarilen assoziiert werden。
MATLAB®unterstützt viele gängige Algorithmen zur clusteranalysis:
- Hierarchisches集群这是一个群集的等级制度,它是一个群集制度。
- k-Means-Clusteringteilt Daten在原始人k-Cluster basierend auf dem Abstand zum Schwerpunkt eines cluster auf。
- 高斯ßVerteilungskurve根据聚类是一种多变量正常的聚类。
- 双拟杆菌räumliches聚类(auch als DBSCAN bekannt)gruppiert Punkte, die nahe beieinander liegen, in Bereichen mit hoher Dichte and behält dabei Ausreißer in Regionen mit geringer Dichte im Blick。我很相信我的看法。
- Selbstorganisierende卡特神经网络的拓扑结构和神经网络的拓扑结构。
- 谱聚类überträgt die Eingangsdaten in eine graphenbasierte Darstellung, in der die Cluster deutlicher voneinander getrennt sind als im ursprünglichen Merkmalsraum。我们的聚类可以在geschätzt werden的本征图中找到。
Wesentliche Punkte
- Die clusteranalysis wid häufig in der explorativen datenanalysis, zur Erkennung von Anomalien and segmenerung sowie Vorverarbeitung für überwachtes Lernen eingesetzt。
- k-Means-Clustering sowie hierarchisches Clustering bleiben weiterhin gefragt, aber für nichtkonvexe Formen sind fortgeschrittenere Techniken wie DBSCAN and Spectral Clustering erforderlich
- Weitere unüberwachte Methoden, die zur Erkennung von Gruppierungen in Daten verwendet werden können, sind Verfahren zur Dimensionalitätsreduktion and as Feature Ranking。