使用GRU网络进行性别分类
这个例子展示了如何使用深度学习对说话者的性别进行分类。该示例使用了一个门控循环单元(GRU)网络和伽玛通倒频谱系数(gtcc)、音调、谐波比和几个谱形状描述符。
介绍
基于语音信号的性别分类是许多音频系统的重要组成部分,如自动语音识别、说话人识别和基于内容的多媒体索引。
这个例子使用了GRU网络,这是一种非常适合研究序列和时间序列数据的递归神经网络(RNN)。GRU网络可以学习序列时间步长之间的长期依赖关系。
这个例子用γ酮倒谱系数序列训练GRU网络(gtcc)、音高估计(球场),谐波比(harmonicRatio),以及若干光谱形状描述符(光谱描述符).
为了加速训练过程,请在带有GPU的机器上运行此示例。如果你的机器有GPU和并行计算工具箱™,那么MATLAB©自动使用GPU进行训练;否则,使用CPU。
用预先训练的网络对性别进行分类
在进入详细的训练过程之前,你将使用预先训练过的网络在两个测试信号中对说话人的性别进行分类。
下载预先训练的网络。
网址=“http://ssd.mathworks.com/金宝appsupportfiles/audio/GenderClassification.zip”;downloadNetFolder = tempdir;netFolder = fullfile (downloadNetFolder,“GenderClassification”);如果~存在(netFolder“dir”解压缩(url, downloadNetFolder)结束
加载预先训练的网络以及预先计算的用于特征归一化的向量。
matFileName=fullfile(netFolder,“genderIDNet.mat”);负载(matFileName“genderIDNet”,“米”,“年代”);
用公喇叭加载测试信号。
[audioIn, Fs] = audioread (“maleSpeech.flac”);声音(音频输入,Fs)
隔离信号中的语音区域。
边界=检测语音(audioIn,Fs);audioIn=audioIn(边界(1):边界(2));
创建一个audioFeatureExtractor从音频数据中提取特征。您将使用同一个对象来提取用于训练的特征。
器= audioFeatureExtractor (...“采样器”Fs,...“窗口”汉明(圆(0.03 * Fs),“周期”),...“OverlapLength”,圆形(0.02*Fs),......“gtcc”,真的,...“gtccDelta”,真的,...“gtccDeltaDelta”,真的,......“SpectralDescriptorInput”,“melSpectrum”,...“spectralCentroid”,真的,...“spectralEntropy”,真的,...“光谱通量”,真的,...“光谱坡度”,真的,......“节”,真的,...“harmonicRatio”,真正的);
从信号中提取特征并将其规格化。
特点=提取(萃取器,audioIn);=(功能特性。“- M)。/ S;
信号的分类。
性别=分类(genderIDNet,特性)
性别=绝对的男性
用女性扬声器识别另一个信号。
[audioIn, Fs] = audioread (“femaleSpeech.flac”);声音(音频输入,Fs)
边界=检测语音(audioIn,Fs);audioIn=audioIn(边界(1):边界(2));特点=提取(萃取器,audioIn);=(功能特性。“- M)。/ S;分类(genderIDNet特性)
ans =绝对的女
预处理训练音频数据
本例中使用的GRU网络在使用特征向量序列时效果最好。为了演示预处理管道,本示例演示单个音频文件的步骤。
读取包含语音的音频文件的内容。说话人的性别是男性。
[audioIn, Fs] = audioread (“Counting-16-44p1-mono-15secs.wav”);标签= {“男性”};
绘制音频信号,然后使用声音命令。
时间向量=(1/Fs)*(0:size(audioIn,1)-1);图形绘制(时间向量,audioIn)ylabel(“振幅”)包含(“时间(s)”)头衔(“音频样本”)网格在
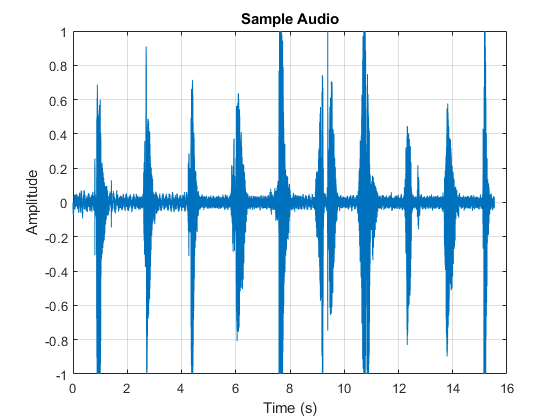
声音(audioIn Fs)
该语音信号具有不包含与说话者性别相关的有用信息的沉默片段。使用detectSpeech定位音频信号中的语音片段。
语音指数=检测语音(音频输入,Fs);
创建一个audioFeatureExtractor从音频数据中提取特征。语音信号本质上是动态的,随时间变化。假设语音信号在短时间尺度上是静止的,其处理通常在20-40毫秒的窗口中完成。指定30毫秒的窗口,重叠20毫秒。
器= audioFeatureExtractor (...“采样器”Fs,...“窗口”汉明(圆(0.03 * Fs),“周期”),...“OverlapLength”,圆形(0.02*Fs),......“gtcc”,真的,...“gtccDelta”,真的,...“gtccDeltaDelta”,真的,......“SpectralDescriptorInput”,“melSpectrum”,...“spectralCentroid”,真的,...“spectralEntropy”,真的,...“光谱通量”,真的,...“光谱坡度”,真的,......“节”,真的,...“harmonicRatio”,真正的);
从每个音频片段中提取特征。的输出audioFeatureExtractor是一个numFeatureVectors-借-numFeatures数组中。的sequenceInputLayer在这个例子中使用需要时间沿着第二个维度。对输出数组进行置换,使时间沿着第二个维度。
featureVectorsSegment = {};为ii = 1:size(speech hindices,1) featureVectorsSegment{end+1} = (extract (extractor,audioIn(speech hindices (ii,1):speech hindices (ii,2))))';结束numSegments =大小(featureVectorsSegment)
数字段=1×21 11
[numFeatures, numFeatureVectorsSegment1] =大小(featureVectorsSegment {1})
numFeatures = 45
numFeatureVectorsSegment1 = 124
复制标签,使它们与段一一对应。
标签= repelem(标签、大小(speechIndices, 1))
标签=1×11单元{“男性”}{‘男性’}{‘男性’}{‘男性’}{‘男性’}{‘男性’}{‘男性’}{‘男性’}{‘男性’}{‘男性’}{‘男性’}
当使用一个sequenceInputLayer在美国,使用长度一致的序列通常是有利的。将特征向量数组转换为特征向量序列。每个序列使用20个特征向量,5个特征向量重叠。
FeatureVectorSequence=20;featureVectorOverlap=5;hopLength=FeatureVectorSequence-featureVectorOverlap;idx1=1;featuresTrain={};sequencePerSegment=0(numel(FeatureVectorSegment),1);为ii = 1:numel(featureVectorsSegment) sequencePerSegment(ii) = max(floor((size(featureVectorsSegment{ii},2) - featureVectorsPerSequence)/hopLength) + 1,0);idx2 = 1;为j = 1:sequencePerSegment(ii) featuresTrain{idx1,1} = featureVectorsSegment{ii}(:,idx2:idx2 + featureVectorsPerSequence - 1);idx1=idx1+1;idx2=idx2+hopLength;结束结束
为了简洁起见,helper函数HelperFeatureVector2Sequence封装上述处理,并在示例的其余部分中使用。
复制标签,使它们与训练集一一对应。
= repelem标签(标签,sequencePerSegment);
预处理管道的结果是NumSequence-by-1 cell数组NUM特征-借-FeatureVectorsPerSequence矩阵。标签是一个NumSequence1数组。
NumSequence =元素个数(featuresTrain)
NumSequence = 27
[NumFeatures,FeatureVectorsPerSequence]=大小(featuresTrain{1})
NumFeatures = 45
FeatureVectorsPerSequence = 20
NumSequence =元素个数(标签)
NumSequence = 27
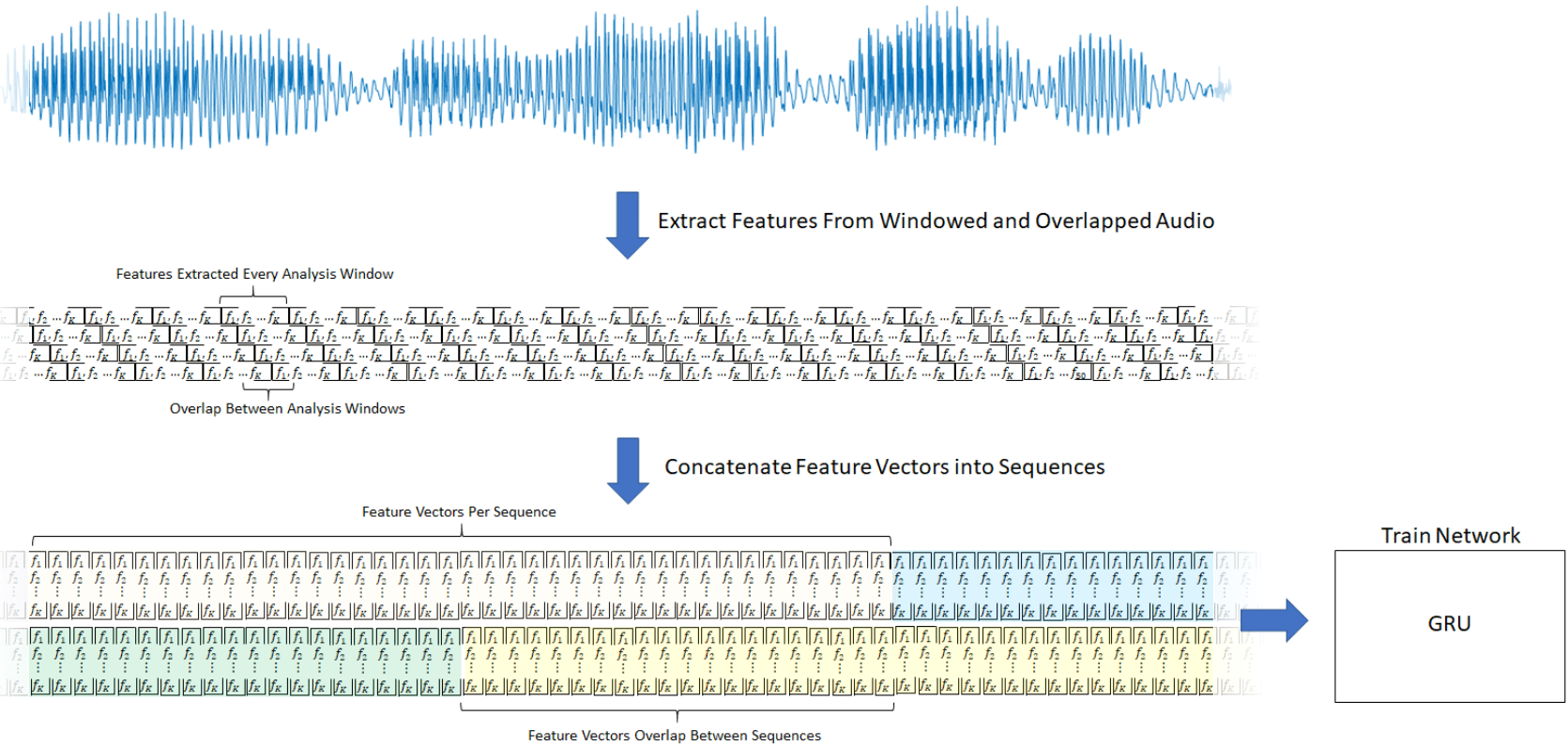
该图概述了每个检测到的语音区域使用的特征提取。
创建培训和测试数据存储
本例使用Mozilla公共语音数据集的一个子集[1].该数据集包含受试者说短句的48千赫录音。下载数据集并解压下载的文件。集PathToDatabase到数据的位置。
网址=“http://ssd.mathworks.com/金宝appsupportfiles/audio/commonvoice.zip”;downloadDatasetFolder = tempdir;dataFolder = fullfile (downloadDatasetFolder,“无法推进”);如果~存在(dataFolder“dir”) disp ('正在下载数据集(956 MB)…'解压缩(url, downloadDatasetFolder)结束
下载数据集(956mb)…
使用audioDatastore为训练和验证集创建数据存储。使用readtable读取与音频文件关联的元数据。
loc=完整文件(数据文件夹);adsTrain=音频数据存储(完整文件(loc,“火车”),“IncludeSubfolders”,真正的);metadataTrain = readtable (fullfile (fullfile (loc,“火车”),“train.tsv”),“文件类型”,“文本”);adsTrain。标签= metadataTrain.gender;adsValidation = audioDatastore (fullfile (loc,“验证”),“IncludeSubfolders”,对);metadataValidation=可读(fullfile,“验证”),“验证.tsv”),“文件类型”,“文本”); adsvalization.Labels=metadataValidation.gender;
使用countEachLabel检查培训和验证集的性别分类。
countEachLabel (adsTrain)
ans=2×2表标签计数______ _____女1000男1000
countEachLabel (adsValidation)
ans=2×2表标签计数______ _____女200男200
要用整个数据集训练网络,并达到尽可能高的精度,集合reduceDataset来假.要快速运行此示例,请设置reduceDataset来真正的.
reduceDataset = false;如果reduceDataset%减少训练数据集的20倍adsTrain=splitEachLabel(adsTrain,round(numel(adsTrain.Files)/2/20));adsvalization=splitEachLabel(adsvalization,20);结束
创建培训和验证集
确定数据集中音频文件的采样率,然后更新音频特征提取器的采样率、窗口和重叠长度。
[~, adsInfo] =阅读(adsTrain);Fs = adsInfo.SampleRate;器。SampleRate = f;器。窗口=汉明(圆(0.03 * Fs),“周期”);器。OverlapLength =圆(0.02 * Fs);
要加快处理速度,请将计算分布到多个工作人员上。如果您有并行计算工具箱™, 该示例对数据存储进行分区,以便在可用辅助进程之间并行进行特征提取。确定系统的最佳分区数。如果没有并行计算工具箱™, 该示例使用单个worker。
如果~ isempty(版本(“平行”)) && ~reduceDataset pool = gcp;numPar = numpartitions (adsTrain、池);其他的numPar = 1;结束
使用“local”配置文件启动并行池(parpool)…连接到并行池(工作人员数量:6)。
在一个循环:
从音频数据存储中读取。
检测语音区域。
从语音区域中提取特征向量。
复制标签,使其与特征向量一一对应。
labelsTrain = [];featureVectors = {};%循环最优的分区数parfor2 = 1: numPar%的分区数据存储再分=分区(adsTrain、numPar ii);%预先配置featureVectorsInSubDS={};segmentsPerFile=0(numel(subds.Files),1);%循环分区数据存储中的文件为jj = 1:元素个数(subds.Files)%1.读入单个音频文件audioIn =阅读(再分);% 2。确定对应于语音的音频区域语音指数=检测语音(音频输入,Fs);% 3。从每个语音片段中提取特征segmentsPerFile大小(jj) = (speechIndices, 1);特点=细胞(segmentsPerFile (jj), 1);为{kk} = (extract (extractor,audioIn(speech hindices (kk,1):speech hindices (kk,2))))';结束featureVectorsInSubDS = (featureVectorsInSubDS;特性(:));结束featureVectors = [featureVectors; featureVectorsInSubDS];%复制标签,使它们一对一对应%利用特征向量。repedLabels = repelem (subds.Labels segmentsPerFile);labelsTrain = [labelsTrain; repedLabels (:));结束
在分类应用中,将所有特征归一化,使其均值为零,标准差为单位,是一种良好的做法。
计算每个系数的平均值和标准差,并使用它们来规范化数据。
allFeatures =猫(2,featureVectors {:});allFeatures (isinf (allFeatures)) =南;M =意味着(allFeatures 2“omitnan”);S =性病(allFeatures 0 2,“omitnan”);featureVectors = cellfun (@ (x)(即x m)。/ S, featureVectors,“UniformOutput”、假);为ii = 1:numel(featureVectors) idx = find(isnan(featureVectors{ii}));如果~isempty(idx) {ii}(idx) = 0;结束结束
将特征向量缓冲成20个特征向量序列,其中10个特征向量重叠。如果一个序列的特征向量少于20个,就放弃它。
[FeatureRestrain,trainSequencePerSegment]=HelperFeatureVector2序列(featureVectors,FeatureVectorSequence,featureVectorOverlap);
复制标签,使它们与序列一一对应。
labelsTrain = repelem (labelsTrain [trainSequencePerSegment {:}));labelsTrain =分类(labelsTrain);
使用与创建训练集相同的步骤创建验证集。
labelsValidation = [];featureVectors = {};valSegmentsPerFile = [];parforii = 1:numPar subds = partition(adsValidation,numPar,ii);featureVectorsInSubDS = {};valSegmentsPerFileInSubDS = 0(元素个数(subds.Files), 1);为jj = 1:numel(subds. files) audioIn = read(subds);speechIndices = detectSpeech (audioIn, Fs);numSegments =大小(speechIndices, 1);特点=细胞(valSegmentsPerFileInSubDS (jj), 1);为kk=1:numSegments特征{kk}=(摘录(提取器,audioIn(speechindex(kk,1):speechindex(kk,2)));结束featureVectorsInSubDS = (featureVectorsInSubDS;特性(:));valSegmentsPerFileInSubDS (jj) = numSegments;结束repedLabels=repelem(subds.Labels,valSegmentsPerFileInSubDS);LabelValidation=[LabelValidation;repedLabels(:)];featureVectors=[featureVectors;featureVectorsInSubDS];valSegmentsPerFile=[valSegmentsPerFileInSubDS];valSegmentsPerFileInSubDS];结束featureVectors = cellfun (@ (x)(即x m)。/ S, featureVectors,“UniformOutput”、假);为ii = 1:numel(featureVectors) idx = find(isnan(featureVectors{ii}));如果~isempty(idx) {ii}(idx) = 0;结束结束[featuresValidation, valSequencePerSegment] = HelperFeatureVector2Sequence (featureVectors、featureVectorsPerSequence featureVectorOverlap);labelsValidation = repelem (labelsValidation [valSequencePerSegment {:}));labelsValidation =分类(labelsValidation);
定义GRU网络架构
GRU网络可以学习序列数据时间步长之间的长期依赖关系。这个示例使用gruLayer从正反两个方向看这个序列。
将输入大小指定为大小顺序NUM特征.指定一个输出大小为75的GRU层并输出一个序列。然后,指定一个输出大小为75的GRU层,并输出序列的最后一个元素。该命令指示GRU层将其输入映射到75个特性中,然后为完全连接层准备输出。最后,通过包含大小为2的完全连接层,然后是softmax层和分类层来指定两个类。
层=[...sequenceInputLayer(大小(featuresTrain {1}, 1)) gruLayer(75年“OutputMode”,“序列”) gruLayer (75,“OutputMode”,“最后一次”)完整连接层(2)softmaxLayer分类层];
接下来,为分类器指定训练选项。集最大时代来4因此,网络通过训练数据进行4次传递。设置MiniBatchSize256个,这样网络一次就能看到128个训练信号。指定阴谋作为“训练进步”生成随迭代次数增加而显示训练进度的绘图。设置详细的来假禁用打印与图中显示的数据相对应的表输出。指定洗牌作为“每个时代”在每个纪元开始时打乱训练顺序。指定LearnRateSchedule来“分段”每经过一定数量的纪元(1),学习率就降低一个指定的因子(0.1)。
本例使用自适应矩估计(ADAM)求解器。ADAM在GRUs这样的递归神经网络(RNNs)中比默认的SGDM (SGDM)求解器表现更好。
miniBatchSize=256;validationFrequency=floor(numel(LabelTrain)/miniBatchSize);options=trainingOptions(“亚当”,...“最大时代”4...“MiniBatchSize”,小批量,...“阴谋”,“训练进步”,...“详细”假的,...“洗牌”,“每个时代”,...“LearnRateSchedule”,“分段”,...“LearnRateDropFactor”, 0.1,...“LearnRateDropPeriod”1....“ValidationData”{featuresValidation, labelsValidation},...“ValidationFrequency”, validationFrequency);
培训GRU网络
使用指定的培训选项和层架构对GRU网络进行培训trainNetwork.由于训练集很大,训练过程可能需要几分钟。
网= trainNetwork (featuresTrain、labelsTrain层,选择);
训练进度图的顶部子图表示训练准确率,即每个小批上的分类准确率。当培训成功进行时,这个值通常会增加到100%。底部的子图显示了训练损失,这是每个小批上的交叉熵损失。当训练成功进行时,这个值通常会降至零。
如果训练不收敛,图可能会在值之间振荡,而不会朝着某个向上或向下的方向。这种振荡意味着训练精度没有提高,训练损失没有减少。这种情况可能发生在训练开始时,或在训练准确性初步提高之后。在许多情况下,改变训练选项可以帮助网络实现收敛。减少MiniBatchSize或减少InitialLearnRate可能会导致更长的训练时间,但它可以帮助网络更好地学习。
想象训练的准确性
计算训练精度,该精度表示分类器对训练信号的精度。首先,对训练数据进行分类。
预测=分类(净,featuresTrain);
绘制混淆矩阵。使用列和行摘要显示两个类的精度和召回率。
figure cm = confusionchart(categorical(labelsTrain)),prediction,“标题”,“训练的准确性”);厘米。ColumnSummary =“column-normalized”;厘米。RowSummary =“row-normalized”;

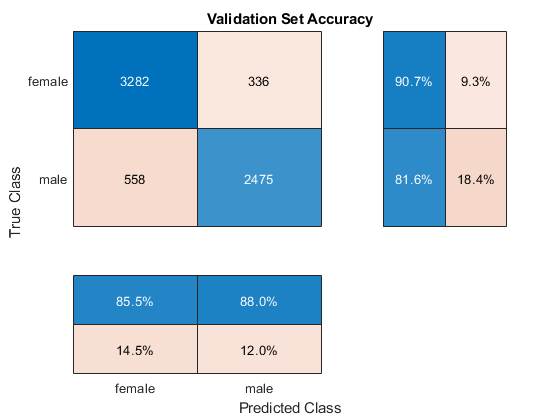
可视化验证准确性
计算验证精度。首先,对训练数据进行分类。
(预测概率)=(网络,featuresValidation)进行分类;
绘制混淆矩阵。使用列和行摘要显示两个类的精度和召回率。
图cm=混淆图(分类(标签验证)、预测、,“标题”,验证设置精度的);厘米。ColumnSummary =“column-normalized”;厘米。RowSummary =“row-normalized”;
该示例从每个训练语音文件生成多个序列。通过考虑同一文件对应的所有序列的输出类,并应用“max-rule”决策,选择置信分值最高的片段的类,可以获得更高的准确率。
确定验证集中每个文件生成的序列数。
sequencePerFile = 0(大小(valSegmentsPerFile));valSequencePerSegmentMat = cell2mat (valSequencePerSegment);idx = 1;为ii = 1:numel(valSegmentsPerFile) sequencePerFile(ii) = sum(valSequencePerSegmentMat(idx:idx+valSegmentsPerFile(ii)-1));idx = idx + valSegmentsPerFile(ii);结束
通过考虑从同一文件生成的所有序列的输出类,预测每个训练文件的性别。
numFiles =元素个数(adsValidation.Files);actualGender =分类(adsValidation.Labels);predictedGender = actualGender;成绩=细胞(1、numFiles);counter = 1;猫=独特(actualGender);为index = 1:numFiles scores{index} =概率(counter: counter + sequencePerFile(index) - 1,:);m = max(平均(分数{指数},1),[],1);如果m(1) >= m(2) predictedGender(index) = cats(1);其他的猫predictedGender(指数)= (2);结束counter = counter + sequencePerFile(index);结束
可视化多数原则预测的混淆矩阵。
图cm=混淆图(实际导向器、预测导向器、,“标题”,“验证集精度-最大规则”);厘米。ColumnSummary =“column-normalized”;厘米。RowSummary =“row-normalized”;

参考文献
金宝app支持功能
函数[序列,sequencePerSegment] = HelperFeatureVector2Sequence(特性、featureVectorsPerSequence featureVectorOverlap)如果FeatureVector序列<=FeatureVector重叠错误(重叠特征向量的数量必须小于每个序列的特征向量的数量。)结束hopLength = featureVectorsPerSequence - featureVectorOverlap;idx1 = 1;序列= {};sequencePerSegment =细胞(元素个数(特性),1);为ii = 1:numel(features) sequencePerSegment{ii} = max(floor((size(features{ii},2) - featureVectorsPerSequence)/hopLength) + 1,0);idx2 = 1;为j = 1:sequencePerSegment{ii} sequences{idx1,1} = feature {ii}(:,idx2:idx2 + featureVectorsPerSequence - 1);% #好< AGROW >idx1=idx1+1;idx2=idx2+hopLength;结束结束结束
你也可以从以下列表中选择一个网站: