使用主题模型分析文本数据
这个示例展示了如何使用Latent Dirichlet Allocation (LDA)主题模型来分析文本数据。
Latent Dirichlet Allocation (LDA)模型是一种主题模型,它发现文档集合中的底层主题,并推断主题中的单词概率。
加载和提取文本数据
加载示例数据。该文件factoryReports.csv包含工厂报告,包括每个事件的文本描述和分类标签。
数据= readtable (“factoryReports.csv”TextType =“字符串”);头(数据)
ans =8×5表类别描述紧急解决成本 _____________________________________________________________________ ____________________ ________ ____________________ _____ " 项目是偶尔陷入扫描仪卷。”“机械故障”、“中等”、“重新调整机器”、“组装器的活塞发出响亮的咔嗒咔嗒和砰砰的声音。”“机械故障”“中等”“调整机器”“启动工厂时电源被切断”“电子故障”“高”“完全更换”“16200”“组装器内电容器烧毁”“电子故障”“高”“更换元件”“352”“混频器跳闸保险丝。”“电子故障”“低”“列入观察名单”“55”施工剂中爆管正在喷洒冷却剂。"泄漏" "高" "更换部件" 371 "混合器内保险丝熔断"“电子故障”“低”“更换部件”“东西不断从传送带上掉下来。”“机械故障”“低”“重新调整机
从字段中提取文本数据描述.
textData = data.Description;textData (1:10)
ans =10×1的字符串“物品偶尔会卡在扫描仪的线轴上。”“组装器的活塞发出响亮的咔嗒咔嗒和砰砰的声音。”“启动核电站时,电力会被切断。”“组装器里的电容器被炸了。”“搅拌机把保险丝弄坏了。”"爆破管道中施工剂正在喷洒冷却剂""搅拌机里的保险丝烧断了"“事情继续从腰带上滑落。”“从传送带上掉下来的东西。”扫描卷轴一旦分开,很快就会开始弯曲。
准备文本数据进行分析
创建一个函数,用于标记和预处理文本数据,以便用于分析。这个函数preprocessText,列于预处理功能部分,依次执行以下步骤:
使用标记文本
tokenizedDocument.使使用的词义化
normalizeWords.删除标点符号使用
erasePunctuation.删除使用停止词的列表(如“and”,“of”和“the”)
removeStopWords.删除使用2个或更少字符的单词
removeShortWords.删除超过15个字符的单词
removeLongWords.
为分析准备文本数据preprocessText函数。
文件= preprocessText (textData);文档(1:5)
ans = 5×1 tokenizedDocument: 6代币:物品偶尔卡在扫描仪卷轴7代币:响亮的叮当声来组装器活塞4代币:切断电源启动工厂3代币:炸电容器组装器3代币:搅拌器trip fuse
从标记化的文档创建单词袋模型。
袋= bagOfWords(文档)
bag = bagOfWords with properties: Counts: [480×338 double] Vocabulary: [1×338 string] NumWords: 338 NumDocuments: 480
从单词袋模型中删除总出现次数不超过两次的单词。从单词袋模型中删除任何不包含单词的文档。
袋= removeInfrequentWords(袋,2);袋= removeEmptyDocuments(袋)
bag = bagOfWords with properties: Counts: [480×158 double
符合LDA模型
拟合7个主题的LDA模型。有关如何选择主题数量的示例,请参见选择LDA模型的主题数.要抑制verbose输出,请设置详细的选项为0。为了再现性,请使用rng函数与“默认”选择。
rng (“默认”) numTopics = 7;mdl = fitlda(袋、numTopics、Verbose = 0);
如果你有一个大的数据集,那么随机近似变分贝叶斯求解器通常是更好的选择,因为它可以在更少的数据中适合一个好的模型。的默认解算器fitlda(坍塌的吉布斯抽样)可以更准确,但代价是运行时间更长。使用随机近似变分贝叶斯,设置解算器选项“savb”.有关如何比较LDA求解器的示例,请参见比较LDA解决者.
使用词云可视化主题
您可以使用单词云来查看每个主题中概率最高的单词。使用词汇云将主题形象化。
图t = tiledlayout(“流”);标题(t)“LDA的话题”)为i = 1:numTopics nexttile wordcloud(mdl,i);标题(“主题”+ i)结束

查看文档中主题的混合
使用与训练数据相同的预处理功能,为一组以前未见过的文档创建一个标记化文档数组。
str = [“冷却剂在汇编器下面汇集。”“分类器在启动时烧断保险丝。”“从组装器里传出很响的咔哒声。”];newDocuments = preprocessText (str);
使用变换函数将文档转换为主题概率向量。注意,对于非常短的文档,主题混合可能不是文档内容的强表示形式。
newDocuments topicMixtures =变换(mdl);
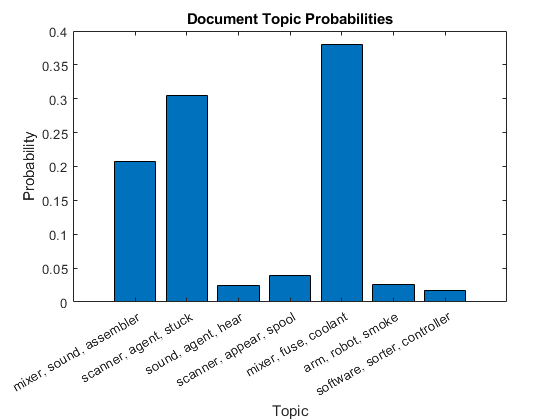
用条形图绘制第一个文档的文档主题概率。要标记主题,请使用相应主题的前三个词。
为i = 1:numTopics top = topkwords(mdl,3,i);topWords (i) =加入(顶部。词,”、“);结束图酒吧(topicMixtures(1:))包含(“主题”) xticklabels (topWords);ylabel (“概率”)标题(“文档主题概率”)
使用堆叠条形图可视化多个主题混合物。可视化文档的主题混合。
图barh (topicMixtures,“堆叠”) xlim([0 1]) title(“主题混合”)包含(“主题概率”) ylabel (“文档”)传奇(顶部,...位置=“southoutside”,...NumColumns = 2)

预处理功能
这个函数preprocessText,依次执行以下步骤:
使用标记文本
tokenizedDocument.使使用的词义化
normalizeWords.删除标点符号使用
erasePunctuation.删除使用停止词的列表(如“and”,“of”和“the”)
removeStopWords.删除使用2个或更少字符的单词
removeShortWords.删除超过15个字符的单词
removeLongWords.
函数文件= preprocessText (textData)标记文本。文件= tokenizedDocument (textData);将单词义化。= addPartOfSpeechDetails文件(文档);文件= = normalizeWords(文档、风格“引理”);%擦掉标点符号。= erasePunctuation文件(文档);删除一个停止词列表。= removeStopWords文件(文档);%删除2个或更少的单词,以及15个或更大的单词%字符。文件= removeShortWords(文件,2);= removeLongWords文档(文档、15);结束
另请参阅
tokenizedDocument|bagOfWords|removeStopWords|fitlda|ldaModel|wordcloud|addPartOfSpeechDetails|removeEmptyDocuments|removeInfrequentWords|变换
相关的话题
你也可以从以下列表中选择一个网站:
