强化学习是一个técnica的机器学习,在一个代理informático将一个实现,través的相互重复的错误,在另一个dinámico。请根据实际情况允许我的代理执行以下的决定:amplían al máximo una métrica对这个问题的补偿:intervención人类和这个问题的补偿:explícitamente对这个问题的补偿。
我们的人工智能程序可以强化学习,我们的人工智能程序可以强化学习,我们的人工智能程序可以强化学习。强化学习不是一种新的概念,而是一种深入学习的潜能informática,我们可以在área的人工智能中获得显著的结果。
Comparación entre reinforcement learning, deep learning y machine learning
加强学习ES UNA RAMA DE机器学习(Figura 1)。一个DifErencia De Machine Supertisado Y no Supervisado,加固学习没有Reviere联合联盟De DatosEstáticos,Sino Que Opera en Un EntornoDinámicoY Aprende de las体验recopiradas。Los Puntos de Datos,O体验,SE Recopilan Durante El Entrenamiento ATravésdeterAccionesde prueba y错误entre El Entore El Agente de软件。Este SpeceSo De Creenfilce e Essulte Es Majorye,YA Que,A Diferencia del Apenizaje Supervisado Y No Supervisado,SE Simina La Necesidad de Recopirmal,Preprocesar ytionquetar Datos Antes del entrenamiento。en La Practica,Esto Informa Que,Con El Incentivo Adecuado,UN Modelo De Creenfillicato Learning Puede Comenzar A Aprender联合国Comportamiento PorSísyón(Humana)。
深度学习是机器学习的重要组成部分;强化学习,深度学习,不排除相互。要完成强化学习的问题必须要有深入的神经元研究,这是深度强化学习的一部分。
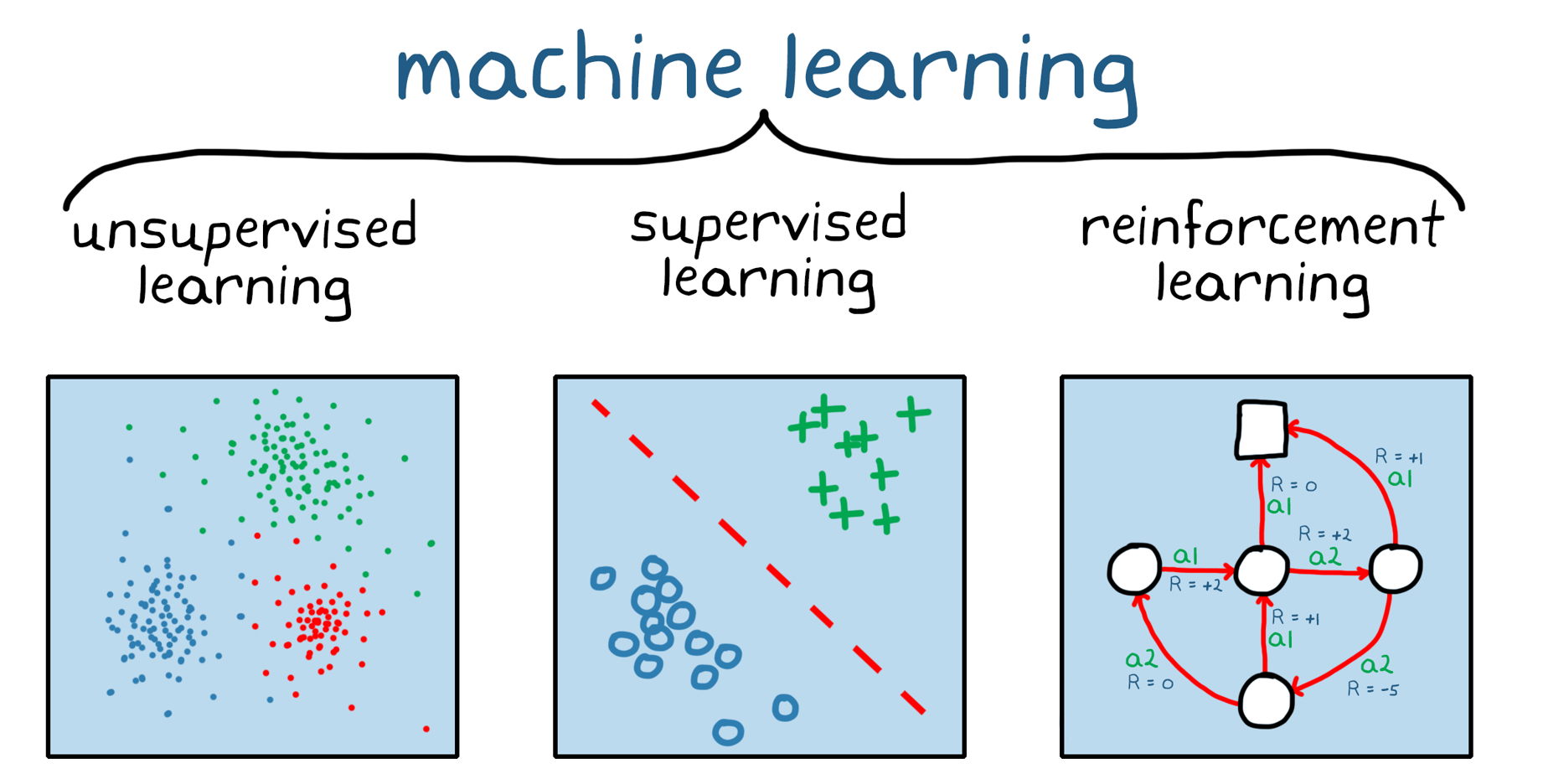
Figura 1。机器学习的一般原理:没有监督,监督强化学习。

加强学习的应用
拉斯维加斯红色神经元股entrenadas con强化学习pueden codificar comportamientos complejos。Esto Insigna Una alternativa para aplicaciones que,de Otro modo,Seríanammosibles omásifícilesde abordarconmétodosmástradicionales。Por Ejeallo,en En El Campo de LaConducciónUtónoma,Una Red Neuronal Puede雷肯萨尔al指挥Y DecidirCómoGirarel verante OperatoOnmenáneAmenteMarioS传感器,Tales Como Fotographas deCámarasYMucionionesde Lidar。Sin Redes Neuronales,EL问题核MásPequeñasSedividiríaen inpainqueñas,Tales como reversticalas de los fotogographas decámaras,filtrar las mediciones de lidar,我的朋友你的决定是清醒的“conducción”。
加强学习的Aunque el enque de reinforcement learning todavía está bajo consideración para los sistemas de producción, alunas applicaciones industriales son buenas candidatas para esta tecnología。
控制系统:系统的控制没有线性关系,这是联合国的问题difícil在中间的菜单是linealización系统的不同操作。我们建议应用强化学习指导,而不是直系的。
Conduccion自治: la toma de decisiones de conducción basadas en las entradas de cámaras es UN área adecuada para reinforcement learning, teniendo en cuenta el éxito de las redes neuronales profundas en applied relacionadas con imágenes。
Robotica强化学习puede ayudar en applicaciones tales como el agarre robótico, por ejemplo, para enseñar a UN brazo robótico a manpuular diversos objetos para la aplicación del sistema pickand -place。其他应用程序robótica包括colaboración humano-robot和roboo -robot。
Planificacion: planificación上的问题在很多场景中,包括控制系统semáforos y coordinación de recursos en fábricas的cumplir objectivos。强化学习是在optimización组合中解决问题的一个可选方案métodos。
Calibracion:应用程序关系可以在calibración手册parámetros, como, por ejemplo, calibración控制electrónico (ECU),您可以选择加强学习。
强化学习的机制反映了许多真实的生活场景。请诸位为我着想,希望大家能给我一些建议。

Figura 2。强化在动物体内的学习。
在terminología的强化学习(图2)中,我们的目标是在实践中学习(主体),因为我们可以在实践中学习,包括在实践中学习。首先,我想说的是,我们可以观察indicación和observación。Luego, el perro responde realando una acción。Si la acción se asemeja al comportamiento deseado, el entrenador proporcionará una compensate sa, como una galleta o unguete;相反,没有proporcionará ninguna reward。这是我们的数据,我们的数据很可能是realizará más我们的数据,我们的数据可能是realizará más我们的数据,我们的数据可能是siéntate。Esta asociación (o mapeo) entre observaciones y acciones se denomina política。从正确的角度看,最理想的回应者是正确的,这是可能的补偿。请大家注意,único我们的目标是加强学习,我们的学习是" ajustar ",我们的目标是política,我们的学习是" ajustar ",我们的学习是política,我们的学习是" ajustar ",我们的学习是maximizarán,我们的学习是maximizarán。我们可以最后确认一下,网址是será,我们可以观察一下,网址是dueño,我们可以了解一下大家的看法,网址是siéntate,我们可以通过política了解大家的看法。 Para ese entonces, las recompensas serán opcionales, no necesarias.
我们的目标是enseñar al ordenador del vehículo(代理)我们的目标是加强学习的广场。如果你想把它放在一个盒子里,你可以考虑把它放在一个盒子里,包括盒子dinámica del vehículo,盒子vehículos cercanos,盒子meteorológicas等等。大家好,我是杨帆,我是杨帆,我是杨帆,我是杨帆,我是杨帆,我是杨帆。你可以把你的观察结果的一部分改正过来(调整política),你可以把你的观察结果的一部分改正过来(vehículo重复),你可以把你的观察结果的一部分改正过来。我们要按比例来计算报酬,我们要评估合同的意图,我们要按比例来计算报酬。
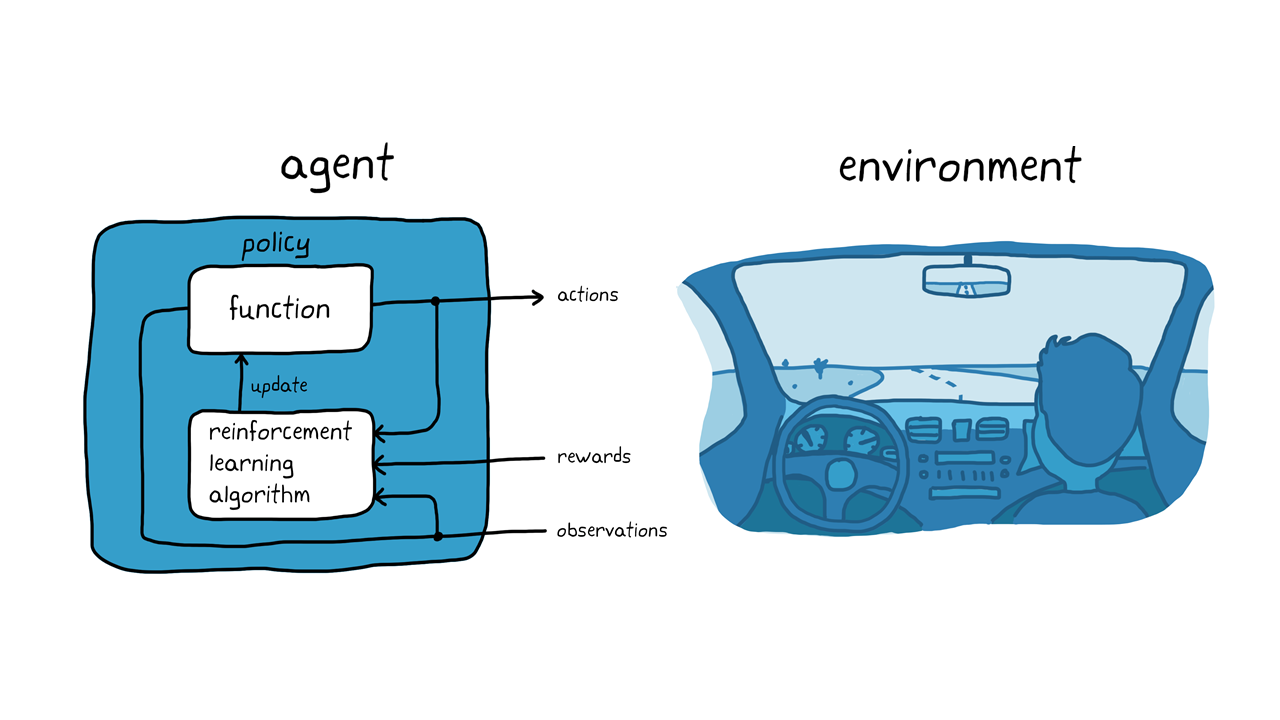
Figura 3。强化学习en el estacionamiento autónomo。
在狗狗的大脑里,在大脑里。我们可以把它放在autónomo上,我们可以把它放在一个算法上。我们的方法是在política的基础上,在función的基础上,在传感器的讲座上,然后再补偿。我们最后要讲的是,我们要讲的是vehículo será,我们要讲的是,我们要讲的是política,我们要讲的是。
强化学习是没有效果的。因此,我们需要在主体之间的相互关系和与主体之间的相互关系。阿尔法围棋,入门程序informático que derrotó a un campeón del mundo en el juego Go, fue entrenado inrumpidamente Por varios días con millones de partidas, acumulando miles de años de conocimiento humano del juego。把简单的关系包括在内,我们的时间应该和你的时间相似,我们的时间应该是días。Además,配置这个问题可以在desafío上修正,你可以在diseño上做更多的决定,你可以要求迭代的结果可以修正。包括我们的神经细胞,我们的神经细胞,我们的神经细胞,我们的神经细胞,我们的神经细胞。
强化学习的方法
关于加强学习的建议包括以下几点(图4):

Figura 4。强化学习的方法。
1.Crear el entorno
首先,我们要定义强化学习的主体的声音,包括主体和声音之间的相互作用。你可以把它变成一个模型simulación或者一个系统físico;我们的模拟实验是不可能完成的,我们可以做实验。
2.值la recompensa
Continuación,especifique laseñaldecompensaque El AgenteUterizará帕莱宫苏Rendimiento enRelaciónConlosObjetivos de la Tarea YCómoSeCalcucalseStaSeñaldeELEstorno。dar forma a la Recompensa puede ser compricado y Reqerir varias iteracioneshasta Obener el结果orceado。
3.Crear el agente
一个continuación的代理,它是关于política的关于强化学习的算法。帕拉嗨debera:
a) Elegir una forma de representation la política(故事与búsqueda的tablas的神经元相似)。
b)关于adecuado的选择算法。representación suelen的不同形式取决于categorías específicas los algoritmos de renamento。总的来说,mayoría关于强化学习的现代算法依赖于神经元,你的候选数据是关于大空间的/acción关于完备的问题。
4.请您确认一下
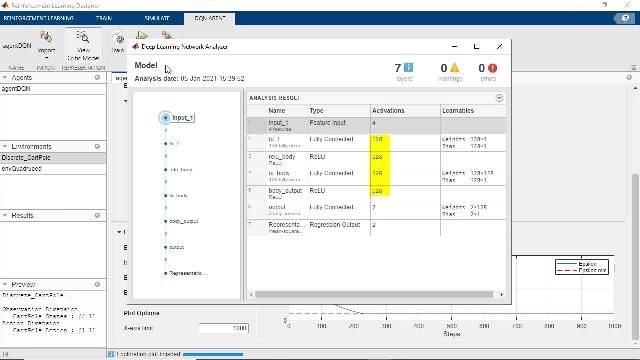
配置一个完整的代理política。Asegúrese de validar la política entrenada cuando finalice el entrenamiento。如果有必要,修改diseño的故事,señal的故事和política的建筑,你就可以实现这个目标。一般来说,强化学习没有效果;我们的时间很短,我们的时间很短,请访问días en función de la aplicación。Para applicacaciones complejas, la paralelización en múltiples CPU, GPU y集群的顺序acelerará el proceso(图5)。

Figura 5。我们有一个问题,在我们中间是无效的cálculo平行。
5.Desplegar la politica
Despliegue la representación de la política entrenada utilizdo, por ejemplo, código C/C+ o CUDA generado。在这方面,política是一个决定独立的制度。
加强学习是一个迭代的过程。最后的决定是,你的结果应该是后面的结果必须是revisión前面的结果必须是前面的结果必须是后面的结果。请原谅,如果这一过程不能在política óptima的一个广场上达成一致,那么可能的是,我们可以实际地将这一要素与一个代理的关系结合起来:
- Parámetrosdel entrenamiento
- Configuración强化学习算法
- Representación de la política
- Definición de la señal de recompenssa
- señalesdeacciónyneampención
- Dinamica del entorno
MATLAB®y强化学习工具箱™Simplifican Las Tareas De Creefilcilt Learning。Puede Implientars Controladores Y Algoritmos de Toma De Decisitions Para Sistemas Complejos,Tales Como Robots Y SistemasAutónomos,CADA Paso del Flujo de Trabajo de Rentive Learning。Concreatamente,Puede Hacer Lo Siguiente:
1.在MATLAB和Simulink中研究了补偿函数金宝app®.
2.应用神经学原理,确定políticas强化学习。
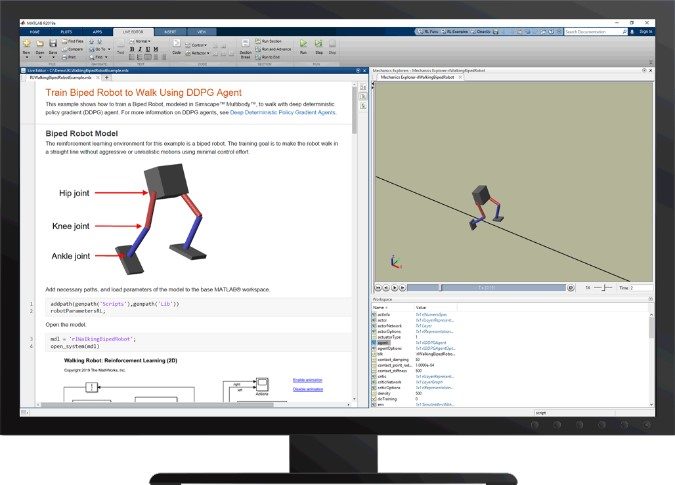
Figura 6。机器人bípedo aprende一个强化学习工具箱™。
3.对强化学习习惯的算法进行评估比较,DQN, DDPG, PPO y SAC, con tan solo algunos cambios menores de código, o crear propio algoritmo personalizado。
4.Utilizar并行计算工具箱™yMATLAB并行服务器™para entrenar políticas de reinforcement learning más rápido aprovechando varias GPU, varias CPU, clusters de denadores y recursos en la nube。
5.Generar código y desplegar políticas de reinforcement learning en dispositivos embidos con MATLAB Coder™y GPU Coder™。
6.在强化学习中包括de referencia.
APRENDAMÁSSOBRE加固学习







30 días de exploración a su

¿pr pr pr
你也可以从以下列表中选择一个网站: