利用MATLAB深度学习容器在Amazon Web Services上训练网络
本示例展示了如何在Amazon EC2®实例上使用MATLAB®在云中训练深度学习网络。
这个工作流通过在云端的MATLAB深度学习容器中训练神经网络,帮助您加快深度学习应用程序的速度。在云中使用MATLAB可以让您选择可以充分利用高性能NVIDIA®gpu的机器。您可以通过web浏览器或VNC连接远程访问MATLAB深度学习容器。然后,您可以在云中Amazon EC2支持gpu的实例上运行MATLAB桌面,以受益于可用的计算资源。
要开始使用MATLAB深度学习容器在AWS®上训练深度学习模型,您必须:
有关此工作流的分步说明,请参见MATLAB深度学习容器在NVIDIA GPU云亚马逊网络服务.
要了解更多信息并查看相同工作流的截图,请参阅博客文章https://blogs.mathworks.com/deep-learning/2021/05/03/ai-with-matlab-ngc/.
云中的语义分割
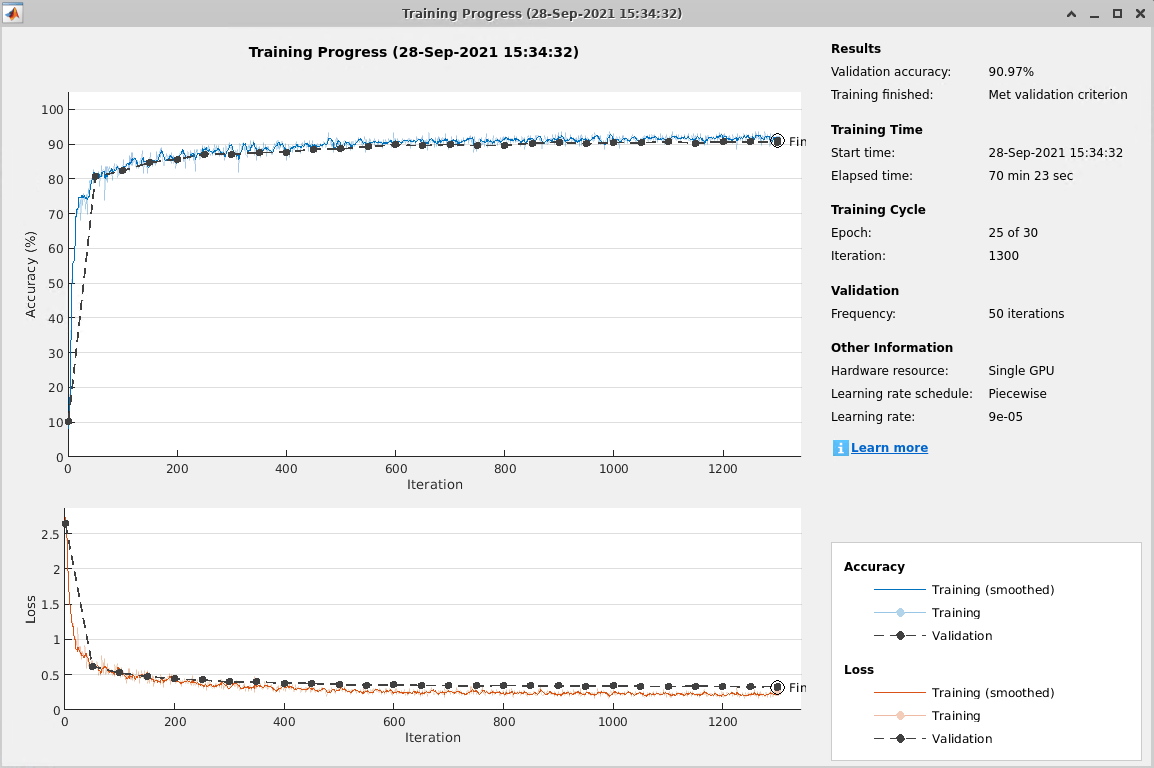
为了演示云中可用的计算能力,展示了使用MATLAB深度学习容器云工作流训练的语义分割网络的结果。在AWS上,训练是在NVIDIA Tesla®V100 SMX2上的p3.2xlarge EC2 GPU启用实例上验证的,该实例具有16 GB的GPU内存。训练花费了大约70分钟来满足验证标准,如训练进度图所示。要了解更多关于语义分割网络示例的信息,请参见基于深度学习的语义分割.
注意,要使用Live Script示例训练语义分割网络,请更改doTraining来真正的.
基于多gpu的云端语义分割
在具有多个gpu的机器上训练网络以提高性能。
当您使用多个gpu进行训练时,每个图像批都分布在gpu之间。GPU之间的分布有效地增加了可用的GPU内存总量,允许更大的批处理大小。推荐的做法是,随着GPU的数量线性地扩大迷你批处理的大小,以保持每个GPU上的工作负载不变。因为增加小批大小提高了每次迭代的意义,也增加了一个等效的因素的初始学习率。
例如,在一台有4个gpu的机器上运行这个训练:
在语义分割的例子中,set
ExecutionEnvironment来multi-gpu在培训中选项.将mini-batch大小增加4以匹配gpu的数量。
初始学习率增加4,以匹配gpu数量。
下面的训练进度图显示了使用多个gpu时性能的提高。结果表明,语义分割网络在4个NVIDIA Titan Xp GPU上训练,GPU内存为12 GB。该示例使用multi-gpu训练选项与小批量大小和初始学习率按4的因素缩放。这个网络在大约20分钟内训练了20个epoch。

如下图所示,使用4个gpu并调整训练选项如上所述,网络具有相同的验证精度,但训练速度快3.5倍。

相关的话题
您也可以从以下列表中选择一个网站: