vggishfeatures.
提取vgnish特征
描述
例子
下载vggishfeatures.功能
下载和解压缩音频工具箱™模型以实现vggnish。
类型vggishfeatures.在命令行。如果未安装VAGAD的音频工具箱模型,则该函数提供了网络权重的位置的链接。要下载模型,请单击链接。将文件解压缩到MATLAB路径上的位置。
或者,执行以下命令将VGGish模型下载并解压到临时目录。
downloadFolder = fullfile (tempdir,“VGGishDownload”);loc = websave (downloadFolder,'https://ssd.mathworks.com/金宝appsupportfiles/audio/vggish.zip');VGGishLocation = tempdir;VGGishLocation解压(loc)目录(fullfile (VGGishLocation,“vggish”))
提取VGGish嵌入
在音频文件中读取。
[AudioIn,FS] = audioread('Maintreetone-16-16-Mono-12secs.wav');
调用vggishfeatures.函数与音频和采样率,从音频提取VGGish特征嵌入。
featurevectors = VggishFeatures(AudioIn,FS);
的vggishfeatures.函数随着时间的推移返回128元素特征向量的矩阵。
[numHops, numElementsPerHop numChannels] =大小(featureVectors)
numHops = 23
numElementsPerHop = 128
numChannels = 1
增加VGGish特征的时间分辨率
创建一个10秒的粉红色噪声信号,然后提取VGGish特征。的vggishfeatures.Function从MEL谱图中提取有50%重叠的特征。
fs = 16 e3;大调的= 10;audioIn = pinknoise(大调的* fs, 1“单一”);特点= vggishFeatures (audioIn, fs);
绘制VGGish功能随时间的变化。
冲浪(特性,“EdgeColor”,“没有”)视图([30 65])轴紧包含(“功能指数”)ylabel(“帧”)xlabel(“特征值”)标题('VAGATH功能')

为了随着时间的推移提高VGGish特征的分辨率,指定mel谱图之间重叠的百分比。策划的结果。
重叠普遍=75;功能= VggishFeatures(AudioIn,FS,“OverlapPercentage”, overlapPercentage);冲浪(特性,“EdgeColor”,“没有”)视图([30 65])轴紧包含(“功能指数”)ylabel(“帧”) zlabel (“特征值”)标题('VAGATH功能')


主成分分析在VGGish嵌入中的应用
读入音频文件,收听它,然后从音频中提取VGGish特征。
[AudioIn,FS] = audioread(“Counting-16-44p1-mono-15secs.wav”);sound(audioIn,fs) features = vggishFeatures(audioIn,fs);
随着时间的推移可视化VGGish特性。许多单独的特征都是零值的,不包含有用的信息。
冲浪(特性,“EdgeColor”,“没有”)视图([90,-90])轴紧包含(“功能指数”)ylabel(“帧索引”)标题('VAGATH功能')

您可以应用主成分分析(PCA)将特征向量映射到一个强调嵌入之间变化的空间。调用vggishfeatures.函数,并指定ApplyPCA作为真的.可视化的VGGish特征后,PCA。
功能= VggishFeatures(AudioIn,FS,“ApplyPCA”,真正的);冲浪(特性,“EdgeColor”,“没有”)视图([90,-90])轴紧包含(“功能指数”)ylabel(“帧索引”)标题('VGGish功能+ PCA')

使用Vggish Embeddings进行深度学习
下载并解压空压机数据集。该数据集由处于健康状态或七种故障状态之一的空压机的记录组成。
url =“//www.tatmou.com/金宝appsupportfiles/audio/AirCompressorDataset/AirCompressorDataset.zip”;downloadFolder = fullfile (tempdir,“aircompressordataset”);datasetlocation = tempdir;如果~ (fullfile (tempdir,存在'aircompressordataset'),“dir”) loc = websave(downloadFolder,url);解压缩(loc fullfile (tempdir'aircompressordataset'))结束
创建一个audioDatastore对象来管理数据,并将其分解为训练集和验证集。
广告= audioDatastore (downloadFolder,'insertumbfolders',真的,'labelsource','foldernames');[adsTrain, adsValidation] = splitEachLabel(广告,0.8,0.2);
从数据存储读取音频文件,保存采样率以供以后使用。重置数据存储区以将读取指针返回到数据集的开头。侦听音频信号并在时域中绘制信号。
[x,fileinfo] =读(adstrain);fs = fileinfo.samplerate;复位(adstrain)声音(x,fs)图t =(0:size(x,1)-1)/ fs;plot(t,x)xlabel('时间'')标题(“国家=”+ String(fileinfo.label))轴紧

从训练集和验证集提取VGGish特征。转换特征,使时间沿着行。
训练费用= Cell(1,Numel(adstrain.files));为idx = 1:numel(adsTrain. files) [audioIn,fileInfo] = read(adsTrain);特点= vggishFeatures (audioIn fileInfo.SampleRate);trainFeatures {idx} =功能”;结束validationFeatures =细胞(1,元素个数(adsValidation.Files));为idx = 1:numel(adsValidation. files) [audioIn,fileInfo] = read(adsValidation);特点= vggishFeatures (audioIn fileInfo.SampleRate);validationFeatures {idx} =功能”;结束
定义A.长短期记忆网络(深度学习工具箱)网络。
layer = [sequenceInputLayer(128) lstmLayer(100,“OutputMode”,“最后一次”) fulllyconnectedlayer (8) softmaxLayer classificationLayer];
定义培训选项,使用培训选项(深度学习工具箱).
miniBatchSize = 64;validationFrequency = 5 *地板(元素个数(trainFeatures) / miniBatchSize);选择= trainingOptions (“亚当”,...“MaxEpochs”12...“迷你atchsize”miniBatchSize,...“阴谋”,“培训 - 进展”,...“洗牌”,“every-epoch”,...“Learnrateschedule”,“分段”,...“学习ropperiod”6...“LearnRateDropFactor”, 0.1,...“ValidationData”, {validationFeatures adsValidation。标签},...“ValidationFrequency”validationFrequency,...“详细”,错误的);
要训练网络,使用trainNetwork(深度学习工具箱).
网= trainNetwork (trainFeatures、adsTrain.Labels层,选项)

net = SeriesNetwork with properties: Layers: [5×1 net.cnn.layer. layer] InputNames: {'sequenceinput'} OutputNames: {'classoutput'}
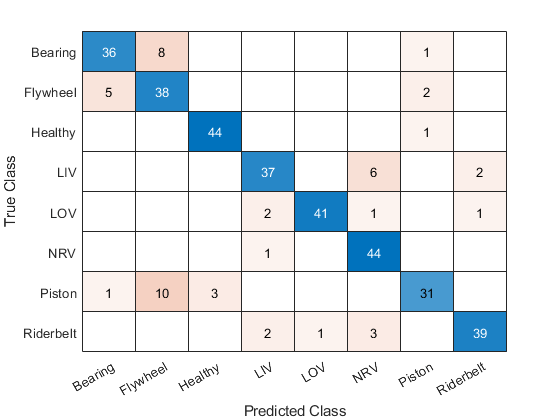
可视化验证集的混淆矩阵。
predictedClass =分类(净,validationFeatures);confusionchart (adsValidation.Labels predictedClass)
使用VAGATH EMBEDDINGS进行机器学习
下载和解压缩空气压缩机数据集[1].该数据集由处于健康状态或七种故障状态之一的空压机的记录组成。
url =“//www.tatmou.com/金宝appsupportfiles/audio/AirCompressorDataset/AirCompressorDataset.zip”;downloadFolder = fullfile (tempdir,“aircompressordataset”);datasetlocation = tempdir;如果~ (fullfile (tempdir,存在'aircompressordataset'),“dir”) loc = websave(downloadFolder,url);解压缩(loc fullfile (tempdir'aircompressordataset'))结束
创建一个audioDatastore对象来管理数据,并将其分解为训练集和验证集。
广告= audioDatastore (downloadFolder,'insertumbfolders',真的,'labelsource','foldernames');
在此示例中,您将信号分类为健康或故障。将所有故障标签组合成一个标签。将数据存储区拆分为培训和验证集。
标签= ads.Labels;标签(标签~ =分类(“健康”)) =分类(“错误”);ads.Labels = removecats(标签);[adsTrain, adsValidation] = splitEachLabel(广告,0.8,0.2);
从训练集中提取VGGish特征。每个音频文件对应多个VGGish特性。复制标签,使它们与功能一一对应。
训练费= [];trainlabels = [];为idx = 1:numel(adsTrain. files) [audioIn,fileInfo] = read(adsTrain);特点= vggishFeatures (audioIn fileInfo.SampleRate);trainFeatures = (trainFeatures;功能);trainLabels = [trainLabels; repelem (fileInfo.Label大小(功能,1))');结束
训练一个三次支持向量机(SV金宝appM)使用fitcsvm(统计学和机器学习工具箱).要探究其他分类器及其表现,请使用分类学习者(统计学和机器学习工具箱).
FaultDetector = fitcsvm(...trainFeatures,...trainLabels,...'骨箱','多项式',...“PolynomialOrder”3,...“KernelScale”,“汽车”,...“BoxConstraint”,1,...“标准化”,真的,...“类名”类别(trainLabels));
对于验证集中的每个文件:
提取VAGATH功能。
对于文件中的每个VGGish特征向量,使用训练过的分类器来预测机器是健康的还是故障的。
采用每个文件的预测模式。
预测= [];为idx = 1:numel(adsValidation. files) [audioIn,fileInfo] = read(adsValidation);特点= vggishFeatures (audioIn fileInfo.SampleRate);predictionsPerFile =分类(预测(faultDetector、特点));预测=[预测;模式(predictionsPerFile)];结束
用困惑的园林(统计学和机器学习工具箱)显示分类器的性能。
精度= = = adsValidation.Labels(预测)和/元素个数(adsValidation.Labels);cc = confusionchart(预测,adsValidation.Labels);cc.Title = sprintf ('精度= %0.2f %',精度* 100);

参考文献
Verma, Nishchal K., Rahul Kumar Sevakula, Sonal Dixit和Al Salour. 2016。空气压缩机声信号智能状态监测IEEE可靠性汇刊65(1):291-309。https://doi.org/10.1109/tr.2015.2459684。
输入参数
输出参数
算法
参考文献
[1] Gemmeke,Jort F.,Daniel P. W. Ellis,Dylan Freedman,Aren Jansen,Wade Lawrence,R. Channing Moore,Manoj Plakal和Marvin Ritter。“音频集:音频事件的本体和人为标签数据集。”在2017 IEEE声学,语音和信号处理国际会议(ICASSP)776-80。新奥尔良,洛杉矶:IEEE。https://doi.org/10.1109/ICASSP.2017.7952261。
Hershey, Shawn, Sourish Chaudhuri, Daniel P. W. Ellis, Jort F. Gemmeke, Aren Jansen, R. Channing Moore, Manoj Plakal, et al. 2017。CNN大规模音频分类架构在2017 IEEE声学,语音和信号处理国际会议(ICASSP),131-35。新奥尔良,洛杉矶:IEEE。https://doi.org/10.1109/ICASSP.2017.7952132。
扩展功能
另请参阅
应用程序
块
功能
您还可以从以下列表中选择一个网站: