光谱描述符
音频工具箱™ 提供一组描述形状的函数,有时称为音色的音频。本示例定义了用于确定光谱特征的方程,引用了每个特征的常见用法,并提供了示例,以便您能够对光谱描述符所描述的内容有直观的了解。
谱描述符广泛应用于机器和深度学习应用,以及感知分析。光谱描述符已应用于一系列应用,包括:
光谱质心
哪里
是对应于bin的频率,单位为Hz .
是bin处的光谱值 .震级谱和功率谱都是常用的。
和 是波段边缘,在箱子里,在上面计算光谱质心。
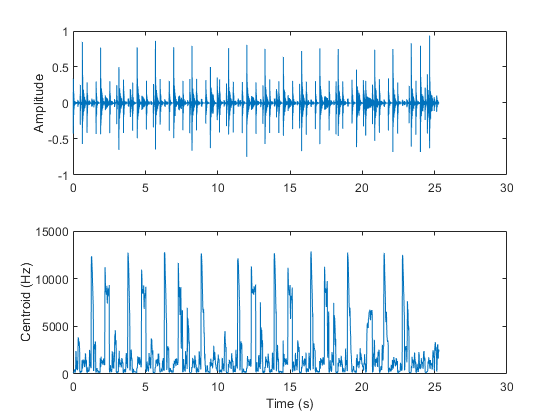
光谱质心表示光谱的“重心”。它用于指示亮度[2.,通常用于音乐分析和体裁分类。例如,观察音频文件中与高帽子击中相对应的质心上的跳跃。
[音频,fs]=音频读取(“FunkyDrums-44p1-stereo-25secs.mp3”);audio=sum(audio,2)/2;质心=spectralCentroid(audio,fs);子地块(2,1,1)t=linspace(0,size(audio,1)/fs,size(audio,1));绘图(t,audio)ylabel(“振幅”) subplot(2,1,2) t = linspace(0,size(audio,1)/fs,size(质心,1));情节(t,质心)包含(“时间(s)”) ylabel (‘质心(Hz)’)
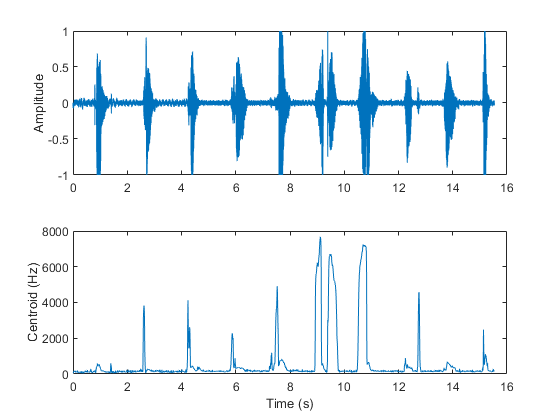
光谱质心也常用来将语音分为浊音和浊音[3.].例如,在不发音的语音区域中,质心跳动。
[音频,fs]=音频读取(“计数-16-44p1-mono-15秒波形”);质心=频谱熵(音频,fs);子批次(2,1,1)t=linspace(0,大小(音频,1)/fs,大小(音频,1));绘图(t,音频)标签(“振幅”) subplot(2,1,2) t = linspace(0,size(audio,1)/fs,size(质心,1));情节(t,质心)包含(“时间(s)”) ylabel (‘质心(Hz)’)
光谱扩散
光谱传播(spectralSpread)是光谱质心周围的标准偏差[1.]:
哪里
是对应于bin的频率,单位为Hz .
是bin处的光谱值 .震级谱和功率谱都是常用的。
和 是波段边缘,在箱子里,在上面计算光谱扩散。
是光谱的质心。
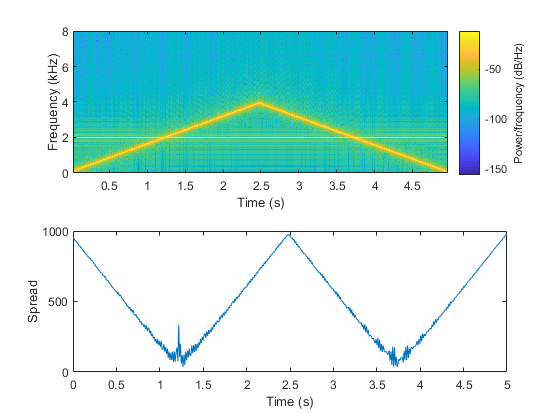
频谱扩展表示频谱的“瞬时带宽”。它被用来表示音调的主导地位。例如,当音调发散时,传播增加,当音调收敛时,传播减少。
fs=16e3;音调=音频振荡器(“SampleRate”fs,“纽顿”,2,“SamplesPerFrame”,512,“频率”(2000、100));时间= 5;numLoops =地板(持续时间* fs / tone.SamplesPerFrame);信号= [];为i=1:numLoops信号=[信号;音调()];如果我< numLoops / 2的基调。频率=基调。频率+ (0,50);其他的基调。频率=基调。频率- [0,50];结束结束扩展=频谱扩展(信号,fs);子批次(2,1,1)频谱图(信号,圆形(fs*0.05),圆形(fs*0.04),2048,fs,“桠溪”) subplot(2,1,2) t = linspace(0,size(signal,1)/fs,size(spread,1));情节(t,传播)包含(“时间(s)”) ylabel (“传播”)
光谱偏度
哪里
是对应于bin的频率,单位为Hz .
是bin处的光谱值 .震级谱和功率谱都是常用的。
和 是带边,在箱子里,在上面计算光谱偏度。
是光谱的质心。
就是光谱扩散。
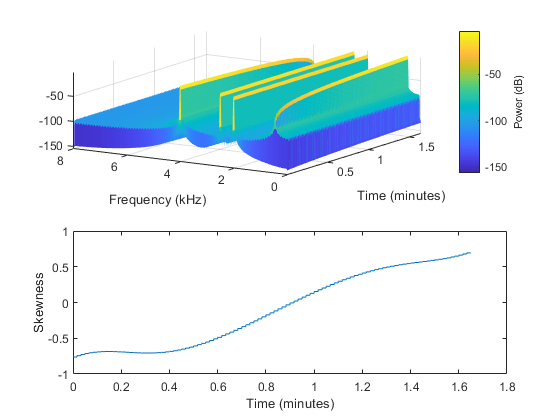
光谱偏度度量的是围绕质心的对称性。在语音学中,频谱偏度常被称为频谱倾斜与其他光谱矩一起使用,以区分发音的位置[4.]。对于谐波信号,它表示高次谐波和低次谐波的相对强度。例如,在四音信号中,当低音占主导地位时,存在正偏斜,当高音占主导地位时,存在负偏斜。
fs=16e3;持续时间=99;音调=音频振荡器(“SampleRate”fs,“纽顿”,4,“SamplesPerFrame”fs,“频率”, 500, 2000, 2500, 4000,“振幅”[0, 0.4, 0.6, 1]);信号= [];为I = 1:duration signal = [signal;tone()];基调。振幅=基调。振幅+ (0.01,0,0,-0.01);结束偏态= spectralSkewness(信号、fs);t = linspace(0,大小(信号,1)/ fs,大小(偏态,1))/ 60;次要情节(2,1,1)谱图(信号,圆(fs * 0.05),圆(fs * 0.04),圆(fs * 0.05), fs,“桠溪”,“权力”视图([-58 33])subplot(2,1,2) plot(t,skewness) xlabel(的时间(分钟)) ylabel (“偏斜”)
谱峰态
哪里
是对应于bin的频率,单位为Hz .
是bin处的光谱值 .震级谱和功率谱都是常用的。
和 是带边,在箱子里,在上面计算光谱峰度。
是光谱的质心。
就是光谱扩散。
谱峰度测量谱在其质心周围的平坦度或非高斯度。相反,它被用来表示光谱的峰度。例如,当语音信号上的白噪声增加时,峰度降低,表明频谱的峰度较低。
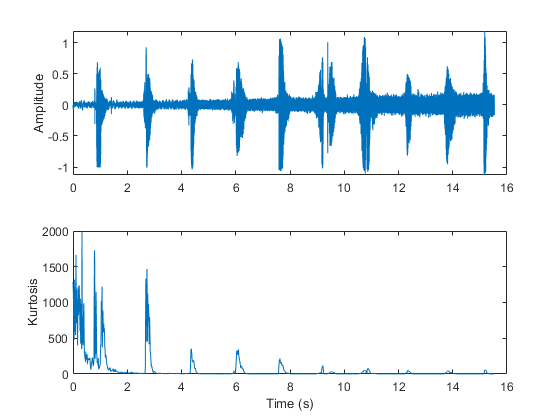
[audioIn, fs] = audioread (“计数-16-44p1-mono-15秒波形”);noiseGenerator=dsp.ColoredNoise(“颜色”,“白色”,“SamplesPerFrame”大小(audioIn 1));噪音= noiseGenerator ();噪音=噪音/ max (abs(噪音));斜坡= linspace(0为元素个数(噪音)';噪音=噪音。*坡道;audioIn = audioIn + noise;峰度= spectralKurtosis (audioIn, fs);t = linspace(0,大小(audioIn 1) / fs,大小(audioIn, 1));次要情节(2,1,1)情节(t, audioIn) ylabel (“振幅”) t = linspace(0,size(audioIn,1)/fs,size(kurtosis,1));次要情节(2,1,2)情节(t,峰态)包含(“时间(s)”) ylabel (“峰度”)
谱熵
哪里
是对应于bin的频率,单位为Hz .
是bin处的光谱值 .震级谱和功率谱都是常用的。
和 是用于计算光谱熵的带边(以箱为单位)。
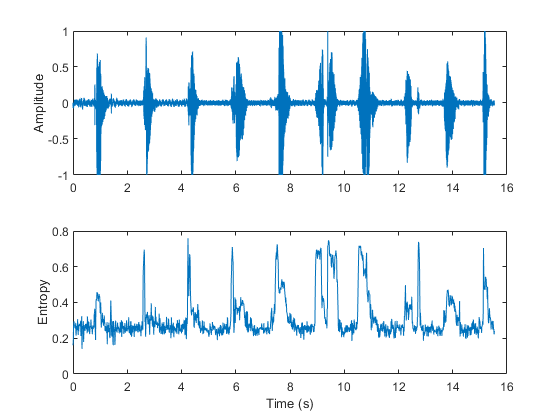
谱熵已成功地应用于语音识别中的浊音/清音判决[6.]因为熵是一种无序度的量度,所以有声语音区域的熵比清音语音区域的熵低。
[audioIn, fs] = audioread (“计数-16-44p1-mono-15秒波形”);熵= spectralEntropy (audioIn, fs);t = linspace(0,大小(audioIn 1) / fs,大小(audioIn, 1));次要情节(2,1,1)情节(t, audioIn) ylabel (“振幅”)t=linspace(0,大小(audioIn,1)/fs,大小(熵,1));子地块(2,1,2)绘图(t,熵)xlabel(“时间(s)”) ylabel (“熵”)
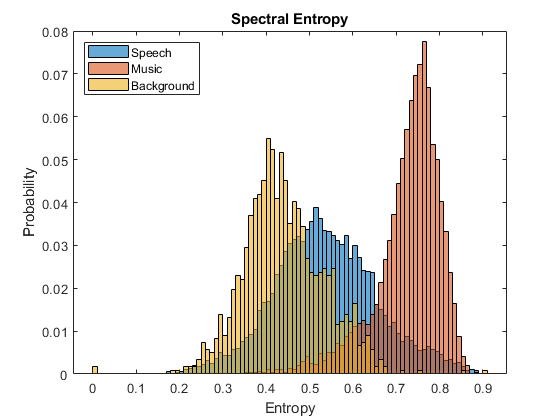
谱熵也被用来区分语音和音乐[7.] [8.].例如,比较语音、音乐和背景音频文件的熵直方图。
fs=8000;[演讲、演讲]=有声阅读(“彩虹-16-8-mono-114s.wav”);演讲=重新取样(演讲、fs、speechFs);演讲= speech. / max(演讲);(音乐、musicFs) = audioread (“rockguitar - 16 - 96立体声- 72 secs.flac”);music=sum(music,2)/2;music=resample(music,fs,musicFs);music=music./max(music);[background,backgroundFs]=audioread(“Ambiance-16-44p1-mono-12secs.wav”);背景=重采样(背景,fs,backgroundFs);背景=背景。/max(背景);speechEntropy=频谱特性(语音,fs);MusicCentropy=频谱特性(音乐,fs);backgroundEntropy=频谱特性(背景,fs);图h1=直方图(speechEntropy);保持在h2 =直方图(musicEntropy);h3 =直方图(backgroundEntropy);h1。归一化=“概率”;h2.正常化=“概率”;h3。归一化=“概率”;h1。BinWidth = 0.01;h2。BinWidth = 0.01;h3。BinWidth = 0.01;标题(“谱熵”)传奇(“演讲”,“音乐”,“背景”,“位置”,“西北”)包含(“熵”) ylabel (“概率”)举行从
光谱平坦度
光谱平坦(spectralFlatness)量度谱的几何平均数与谱的算术平均数的比率[9]:
哪里
是bin处的光谱值 .震级谱和功率谱都是常用的。
和 是用于计算光谱平坦度的带边(以箱为单位)。
光谱平坦度表示光谱的峰值。较高的光谱平坦度表示噪声,较低的光谱平坦度表示音调。
[音频,fs]=音频读取(“波导环通-24-96-立体声-10秒aif”);audio=sum(audio,2)/2;noise=(2*rand(numel(audio,1)-1)。*linspace(0,0.05,numel(audio));audio=audio+noise;flatness=spectralFlatness(audio,fs);子地块(2,1,1)t=linspace(0,size(audio,1)/fs,size(audio,1));plot(t,audio)标签(“振幅”) subplot(2,1,2) t = linspace(0,size(audio,1)/fs,size(flatness,1));情节(t,平面度)ylabel (“平整度”)包含(“时间(s)”)
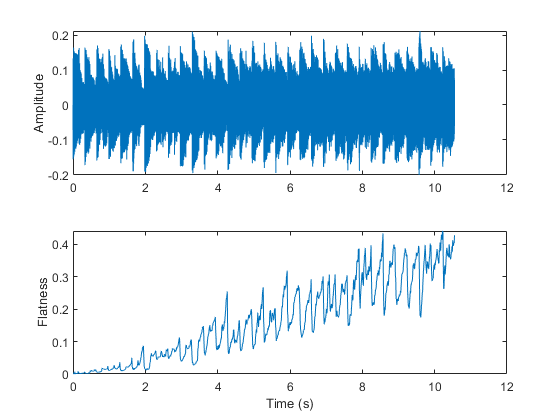
频谱平坦度也成功地应用于歌唱语音检测[10]及声频场景识别[11].
光谱波峰
光谱波峰(光谱休息)量度谱的最大值与谱的算术平均值的比率[1.]:
哪里
是bin处的光谱值 .震级谱和功率谱都是常用的。
和 是在箱子里的波段边缘,在上面计算光谱波峰。
光谱波峰是光谱峰度的指示。较高的谱峰表示更多的调性,而较低的谱峰表示更多的噪声。
[音频,fs]=音频读取(“波导环通-24-96-立体声-10秒aif”);audio=sum(audio,2)/2;noise=(2*rand(numel(audio,1)-1)。*linspace(0,0.2,numel(audio));audio=audio+noise;crest=spectralCrest(audio,fs);subplot(2,1,1)t=linspace(0,size(audio,1)/fs,size(audio,1));plot(t,audio)ylabel(“振幅”) subplot(2,1,2) t = linspace(0,size(audio,1)/fs,size(crest,1));情节(t,嵴)ylabel (“波峰”)包含(“时间(s)”)

光谱通量
谱通量(spectralFlux)是对光谱随时间变化的量度[12]:
哪里
是bin处的光谱值 .震级谱和功率谱都是常用的。
和 是用于计算光谱通量的带边(以箱为单位)。
是标准类型。
光谱通量广泛应用于起始检测[13]及音频分割[14].例如,鼓轨道中的节拍对应于高光谱通量。
[音频,fs]=音频读取(“FunkyDrums-48-stereo-25secs.mp3”);音频=总和(音频,2)/2;流量=频谱流量(音频,fs);子批次(2,1,1)t=linspace(0,大小(音频,1)/fs,大小(音频,1));绘图(t,音频)标签(“振幅”) subplot(2,1,2) t = linspace(0,size(audio,1)/fs,size(flux,1));情节(t,通量)ylabel (“通量”)包含(“时间(s)”)
光谱斜率
哪里
是对应于bin的频率,单位为Hz .
是平均频率。
是bin处的光谱值 .幅值谱是常用的。
是平均光谱值。
和 是用于计算光谱斜率的带边(以箱为单位)。
频谱斜率已广泛应用于语音分析,特别是在建模说话人应力[19].坡度与声带的共振特性直接相关,也被应用于说话人的识别[21]光谱斜率是音色的一个重要的社会方面。光谱斜率辨别已被证明发生在儿童早期发育阶段[20].当低共振峰的能量远大于高共振峰的能量时,谱斜率最为明显。
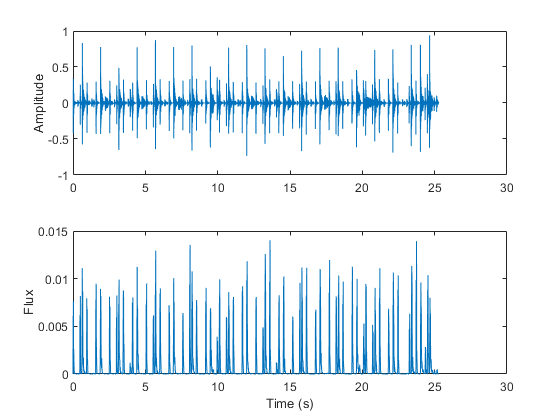
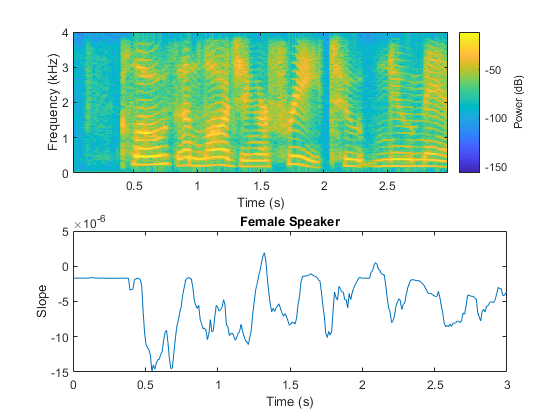
(女,femaleFs) = audioread (“FemaleSpeech-16-8-mono-3sec.wav”);女= female. / max(女);femaleSlope = spectralSlope(女,femaleFs);t = linspace(0,大小(女,1)/ femaleFs大小(femaleSlope, 1));次要情节(2,1,1)谱图(女,圆(femaleFs * 0.05),圆(femaleFs * 0.04),圆(femaleFs * 0.05), femaleFs,“桠溪”,“权力”)子地块(2,1,2)地块(t,女坡)名称(“女性演讲者”) ylabel (“坡度”)包含(“时间(s)”)
光谱衰减
光谱减少(spectralDecrease)表示频谱的减少量,同时强调较低频率的斜率[1.]:
哪里
是bin处的光谱值 .幅值谱是常用的。
和 是波段边缘,在箱子里,在上面计算光谱减少。
在语音文献中,谱减法比谱斜率使用得少,但在音乐分析中,谱减法和谱斜率一起被普遍使用。特别是,光谱降低已被证明是一种很好的仪器识别特征[22].
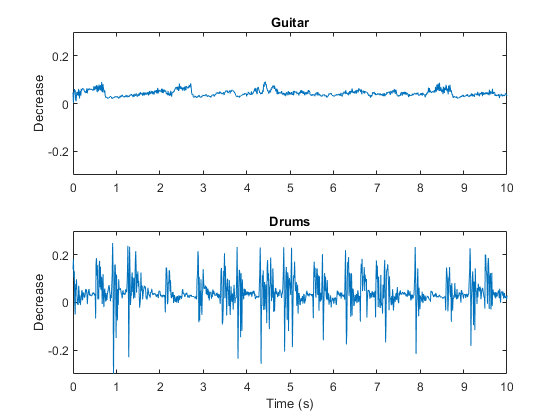
(吉他,guitarFs) = audioread (“摇滚吉他-16-44p1-stereo-72secs.wav”);吉他=平均(吉他,2);[鼓,鼓]=有声读物(“RockDrums-44p1-stereo-11secs.mp3”);鼓=意味着(鼓,2);guitarDecrease = spectralDecrease(吉他,guitarFs);drumsDecrease = spectralDecrease(鼓、drumsFs);t1 = linspace(0,大小(吉他,1)/ guitarFs大小(guitarDecrease, 1));t2 = linspace(0,大小(鼓,1)/ drumsFs大小(drumsDecrease, 1));次要情节(2,1,1)情节(t1, guitarDecrease)标题(“吉他”) ylabel (“减少”)轴([0.10-0.3 0.3])子地块(2,1,2)图(t2,drumsDecrease)标题(“鼓”) ylabel (“减少”)包含(“时间(s)”)轴([010-0.30.3])
光谱滚边点
谱滚转点(spectralRolloffPoint)通过确定总能量的给定百分比所处的频率区间来测量音频信号的带宽[12]:
哪里
是bin处的光谱值 .震级谱和功率谱都是常用的。
和 是要在其上计算光谱衰减点的带边(以箱为单位)。
是指定的能量阈值,通常为95%或85%。
在返回之前转换为HzspectralRolloffPoint.
频谱滚动点已经被用来区分浊音和浊音语音,语音/音乐的区分[12,音乐体裁分类[16],声场景识别[17],以及音乐情绪分类[18]。例如,观察语音、摇滚吉他、原声吉他和声学场景的滚动点的不同平均值和方差。
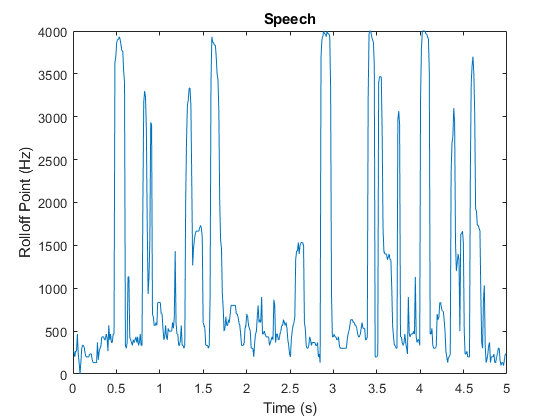
大调的= 5;%从每个文件剪辑5秒。[语音,fs1]=音频阅读(“SpeechDFT-16-8-mono-5秒波形”);语音=语音(1:min(结束,fs1*dur));[电吉他,fs2]=音频阅读(“摇滚吉他-16-44p1-stereo-72secs.wav”);电吉他=平均值(电吉他,2);%转换为单声道进行比较。electricGuitar = electricGuitar (1: fs2 *大调的);[acousticGuitar, fs3] = audioread (“SoftGuitar-44p1_mono-10mins.ogg”);声学吉他=声学吉他(1:fs3*dur);[声学场景,fs4]=音频读取(“MainStreetOne-16-16-mono-12secs.wav”);声学场景=声学场景(1:fs4*dur);r1=频谱滚动偏移点(语音,fs1);r2=频谱滚动偏移点(电吉他,fs2);r3=频谱滚动偏移点(声学吉他,fs3);r4=频谱滚动偏移点(声学场景,fs4);t1=林空间(0,大小(语音,1)/fs1,大小(r1,1));t2=林空间(0,大小(电吉他,1)/fs2,大小(r2,1));t3=林空间(0,大小,大小(声学吉他,1)/fs3,尺寸(r3,1));t4=linspace(0,尺寸(声学场景,1)/fs4,尺寸(r4,1));图形图(t1,r1)标题(“演讲”) ylabel (“滚边点(Hz)”)包含(“时间(s)”)轴([0 5 0 4000])
图绘制(t2, r2)标题(“摇滚吉他”) ylabel (“滚边点(Hz)”)包含(“时间(s)”)轴([0 5 0 4000])
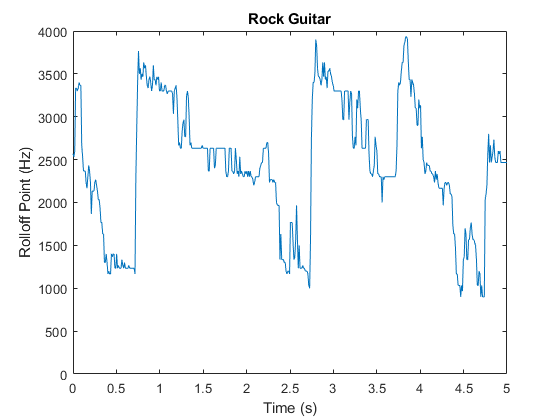
图绘制(t3, r3)标题(木吉他的) ylabel (“滚边点(Hz)”)包含(“时间(s)”)轴([0 5 0 4000])
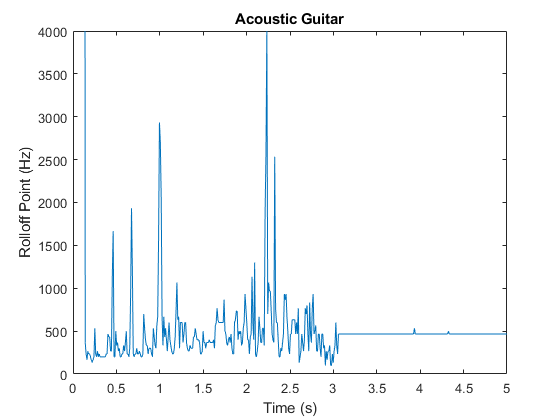
图4地块(t4、r4)标题(“声学场景”) ylabel (“滚边点(Hz)”)包含(“时间(s)”)轴([0 5 0 4000])

参考文献
[1] Peeters,G.“CUIDADO项目中用于声音描述(相似性和分类)的大量音频特征”,技术报告;IRCAM:巴黎,法国,2004年。
[2] 格雷、约翰·M.和约翰·W·戈登:“光谱修改对音色的感知影响。”美国声学学会杂志。1978年第63卷第5期1493-1500页。
蕾米,埃里克和查尔斯·e·凯恩斯。语音学和音系学部分新泽西州霍博肯:约翰·威利父子公司,2015年。
[4] Jongman, Allard, et al. <英语擦音的声学特征>美国声学学会杂志。2000年第108卷第3期1252-1263页。
[5] Zhang,Y.Guo和Q.Zhang,“基于频谱峰度的鲁棒语音活动检测特征设计。”第一届教育技术与计算机科学国际研讨会,2009年,第269-272页。
[6] Misra,H.,S.Ikbal,H.Bourard和H.Hermansky.“稳健ASR的基于谱熵的特征。”2004年IEEE声学、语音和信号处理国际会议.
[7] A.Pikrakis、T.Giannakopoulos和S.Theodoridis.“一种计算效率高的无线电录音语音/音乐鉴别器。”国际音乐信息检索及相关活动会议, 2006年。
[8] 一种基于动态规划和贝叶斯网络的无线电录音语音/音乐鉴别器IEEE多媒体交易。第10卷,2008年第5期,第846-857页。
[9] Johnston, j.d.,《使用感知噪声标准转换音频信号编码》。IEEE通信选定领域期刊。第6卷第2期,1988年,第314-323页。
[10] 关于降低歌唱声音检测中的误报率2014年IEEE声学、语音和信号处理国际会议(ICASSP), 2014年。
[11] Y.Petetin,C.Laroche和A.Mayoue,“用于音频场景识别的深度神经网络,”2015年第23届欧洲信号处理会议(EUSIPCO),2015.
Scheirer, E.和M. Slaney。鲁棒多特征语音/音乐鉴别器的构建与评估。1997年IEEE声学、语音和信号处理国际会议,1997.
[13] S. Dixon,《复发性检测》(Onset Detection Revisited)。数字音频效果国际会议。第120卷,2006年,133-137页。
[14] 用于浏览和注释的多功能音频分割1999年IEEE信号处理在音频和声学中的应用研讨会论文集,1999.
[15]我们,亚历山大。音频内容分析在信号处理和音乐信息学中的应用简介新泽西州皮斯卡塔韦:IEEE出版社,2012年。
[16] Li, Tao, M. Ogihara。《音乐体裁分类与分类学》我EEE声学、语音和信号处理国际会议,2005.
[17] 《基于音频的上下文识别》,Eronen,A.j.,V.t.Peltonen,j.t.Tuomi,A.p.Klapuri,S.Fagerlund,t.Sorsa,G.Lorho和j.HuopaniemiIEEE音频,语音和语言处理汇刊。第14卷,2006年第1期,第321-329页。
[18] 任家敏、吴明菊和张成荣。“基于音色和调制特征的音乐情绪自动分类。”情感计算。2015年第6卷第3期236-246页。
约翰·h·L·汉森和桑杰·帕蒂尔。"压力下的言语:分析,建模和识别"计算机科学课堂讲稿。2007年第4343卷,108-137页。
Christine D.和Laurel J. Trainor。《婴儿期光谱斜率辨别:对社会重要音色的敏感性》。婴儿行为和发育。第25卷,第2期,2002年,第183-194页。
H.a. Murthy, F. Beaufays, L.p. Heck, M. Weintraub。“在电话通道上的健壮的文本独立扬声器识别”。IEEE语音和音频处理汇刊。1999年第7卷第5期554-568页。
埃西德,S, G.理查德和B.大卫。《基于自动分类的复调音乐乐器识别》。IEEE音频,语音和语言处理汇刊。2006年第14卷第1期,第68-80页。
你也可以从以下列表中选择一个网站: